Lucene原理与代码分析详解
需积分: 26 129 浏览量
更新于2024-07-25
收藏 4.73MB PDF 举报
"Lucene 原理与代码分析完整版"
Lucene是一个开源的全文搜索引擎库,由Apache软件基金会开发并维护。它提供了一个可扩展的、高性能的、灵活的框架,用于在Java应用程序中实现全文检索功能。本书《Lucene原理与代码分析》深入探讨了Lucene的核心机制和实现细节。
在全文检索的基本原理部分,作者首先介绍了全文检索的总论,解释了为何需要全文检索以及它的核心价值。全文检索允许用户通过输入关键词快速找到包含这些关键词的文档,而无需浏览所有文档。接着,书中详细阐述了索引中存储的内容,包括文档、词元、词项(Term)和文档倒排索引(PostingList)。
创建索引是Lucene工作流程的关键步骤,主要包括以下四个阶段:
1. 提供要索引的原文档,这些文档可以是各种格式,如HTML、PDF等。
2. 使用Tokenizer对文档进行分词,将连续的字符序列分解成有意义的词汇单元(词元)。
3. 应用LinguisticProcessor进行语言处理,例如去除停用词、词形还原等,以提高检索准确性。
4. 最后,Indexer将词元转换为索引结构,包括构建字典、排序词项和组合文档倒排列表。
在搜索索引时,用户输入的查询语句会经过词法分析、语法分析和语言处理。词法分析识别出查询中的关键词,语法分析构造查询语句的结构,而语言处理则考虑了特定语言的特性。然后,搜索引擎会查找匹配的文档,并通过计算每个文档中关键词的权重以及使用向量空间模型(VSM)来确定文档的相关性,对结果进行排序。
第二篇的代码分析篇将带领读者深入到Lucene的源码层面,理解其内部机制。从Lucene的总体架构到索引文件格式,涵盖了Lucene中的一些关键组件和数据结构。其中,索引文件格式包括基本概念、基本类型和基本规则,如前缀后缀规则、差值规则和或然跟随规则,这些都是为了高效存储和检索索引信息而设计的。
《Lucene原理与代码分析》是一本深入剖析Lucene的书籍,不仅涵盖了全文检索的基本理论,还详细解析了Lucene的实现细节,对于想要理解和掌握Lucene的开发者来说,是一份宝贵的参考资料。通过阅读本书,读者可以全面了解如何在实际项目中运用Lucene来构建高效的全文搜索引擎。

16
到相同的转换。
语言处理组件(linguistic processor)的结果称为词(Term)。
在我们的例子中,经过语言处理,得到的词(Term)如下:
“student”,“allow”,“go”,“their”,“friend”,“allow”,“drink”,“beer”,“my”,“friend”,“jerry”,
“go”,“school”,“see”,“his”,“student”,“find”,“them”,“drink”,“allow”。
也正是因为有语言处理的步骤,才能使搜索 drove,而 drive 也能被搜索出来。
第四步
第四步第四步
第四步:
::
:将得到的词
将得到的词将得到的词
将得到的词(Term)传给索引组件
传给索引组件传给索引组件
传给索引组件(Indexer)。
。。
。
索引组件(Indexer)主要做以下几件事情:
1. 利用得到的词
利用得到的词利用得到的词
利用得到的词(Term)创建一个字典
创建一个字典创建一个字典
创建一个字典。
。。
。
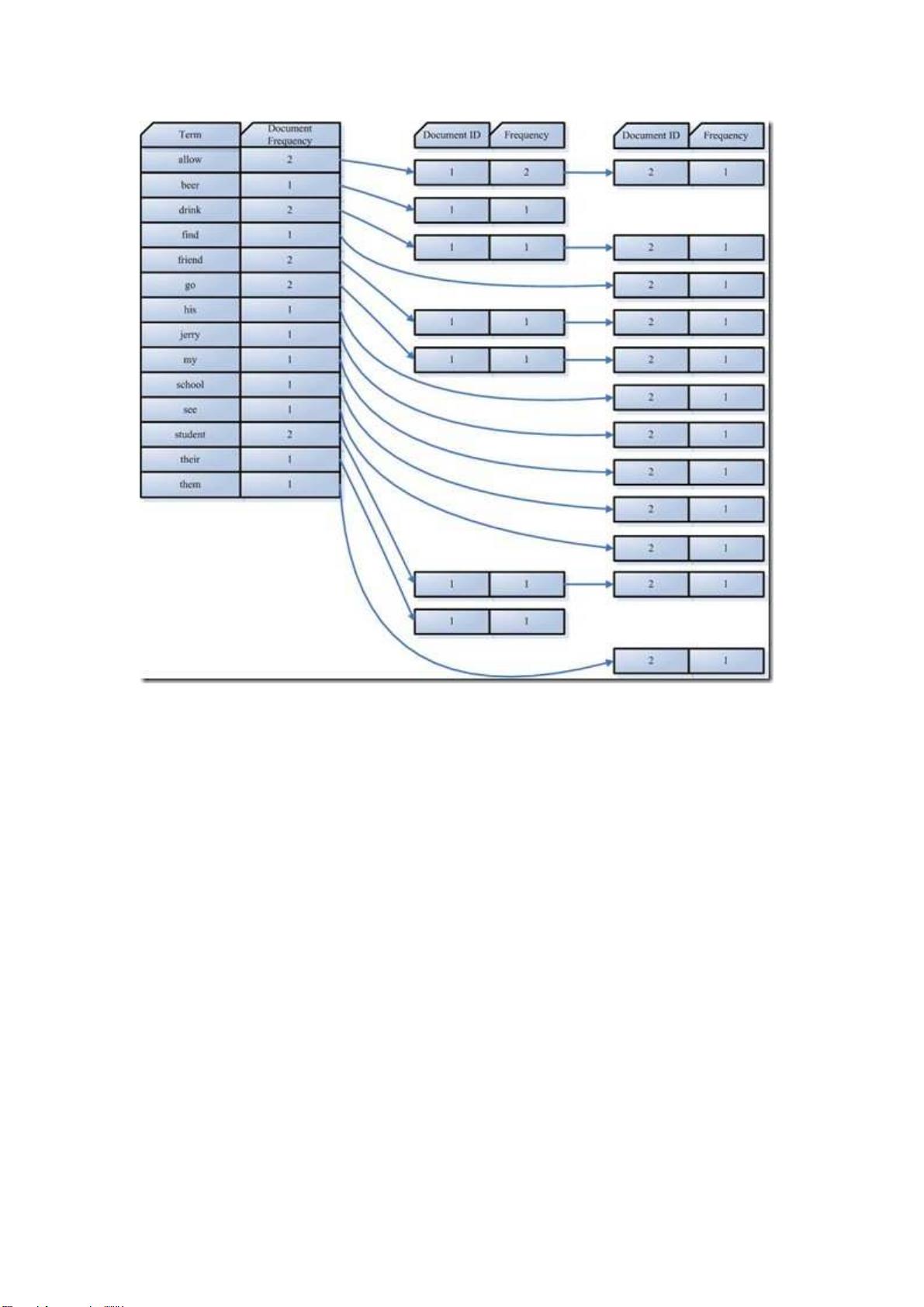
在我们的例子中字典如下:
Term Document ID
student 1
allow 1
go 1
their 1
friend 1
allow 1
drink 1
beer 1
my 2
friend 2


剩余526页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2013-09-11 上传
2012-11-04 上传
2010-11-17 上传
2017-09-23 上传
2018-04-19 上传

PiaoFengTT
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular程序高效加载与展示海量Excel数据技巧
- Argos客户端开发流程及Vue配置指南
- 基于源码的PHP Webshell审查工具介绍
- Mina任务部署Rpush教程与实践指南
- 密歇根大学主题新标签页壁纸与多功能扩展
- Golang编程入门:基础代码学习教程
- Aplysia吸引子分析MATLAB代码套件解读
- 程序性竞争问题解决实践指南
- lyra: Rust语言实现的特征提取POC功能
- Chrome扩展:NBA全明星新标签壁纸
- 探索通用Lisp用户空间文件系统clufs_0.7
- dheap: Haxe实现的高效D-ary堆算法
- 利用BladeRF实现简易VNA频率响应分析工具
- 深度解析Amazon SQS在C#中的应用实践
- 正义联盟计划管理系统:udemy-heroes-demo-09
- JavaScript语法jsonpointer替代实现介绍
