Apache Kylin:大数据多维分析的极致性能
需积分: 43 6 浏览量
更新于2024-07-18
收藏 1.6MB PDF 举报
"Apache Kylin大数据多维分析引擎在MEIZU的实践,提供亚秒级交互式分析功能,采用Layer Cubing和Fast Cubing技术,支持可扩展插件式架构,实现对数据源、Cube引擎、存储引擎的解耦。"
Apache Kylin是一款专为大数据环境设计的开源分布式分析引擎,其主要目标是解决海量数据的快速分析问题,特别是在在线分析处理(OLAP)场景下,提供亚秒级的查询响应时间。这个系统最初由eBay开发,并最终贡献给了Apache社区,成为了Hadoop生态系统中的重要组成部分。
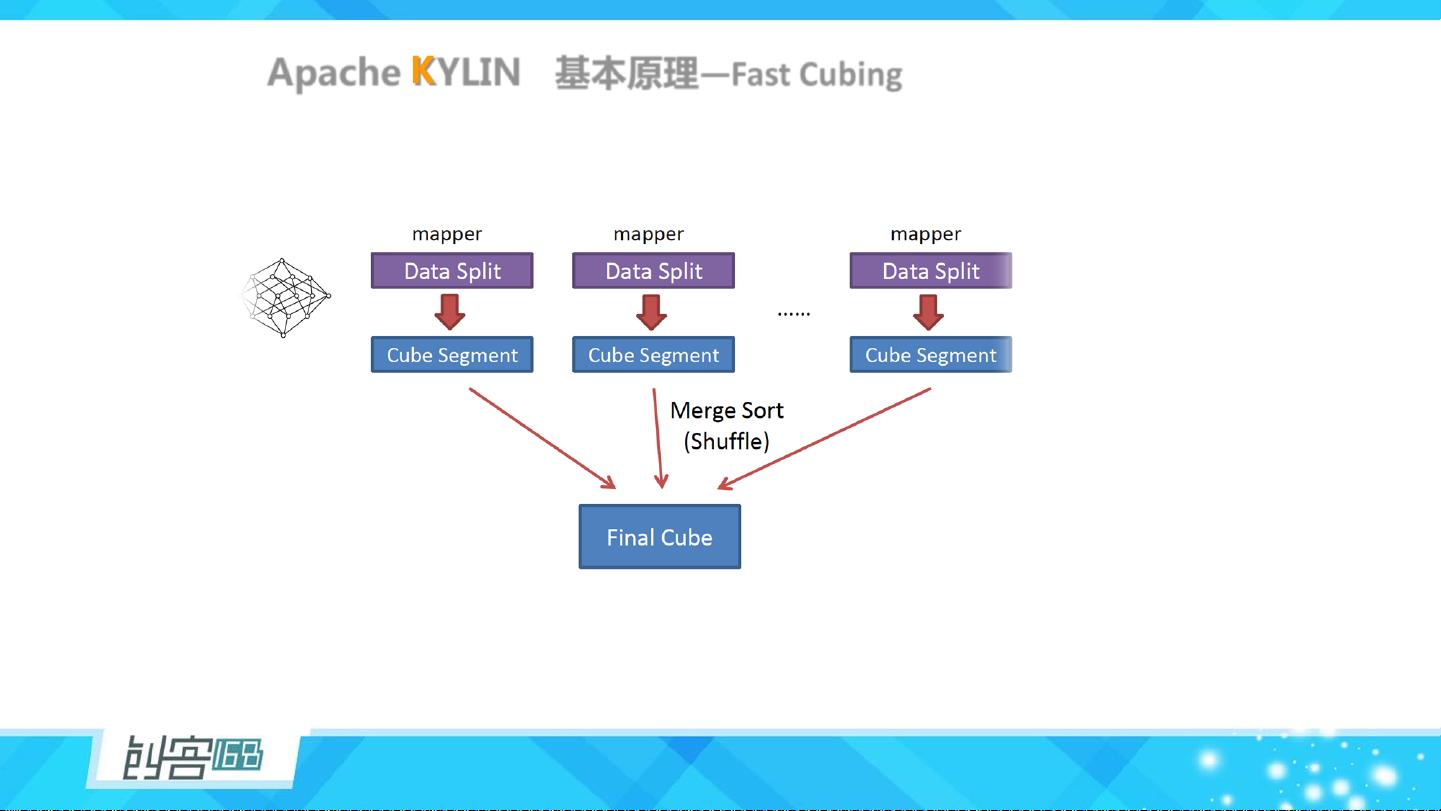
在架构上,Apache Kylin采用了创新的Layer Cubing和Fast Cubing技术。Layer Cubing是一种预计算策略,它将大数据集预先切分成多个小的、易于处理的“层”,从而显著减少了实时查询时的数据扫描量。Fast Cubing则是在Layer Cubing基础上的优化,进一步加速了立方体构建过程,使得数据分析更加高效。
Kylin的设计中,数据存储是一个关键环节。它通常使用HBase作为底层存储,因为HBase提供了高并发读写和列式存储的能力,适合大数据场景。然而,随着 Kylin 的发展,其引入了可扩展插件式架构,允许用户自定义数据源、Cube引擎和存储引擎。这种解耦的架构意味着Kylin不再局限于Hadoop、HBase或Hive,可以灵活地适应不同的数据存储和处理需求,如Spark、Kafka等。
查询引擎部分,Kylin支持标准SQL查询,提供Explain Plan功能,帮助用户理解查询执行的细节,优化查询性能。Web UI和REST API则为用户提供友好的操作界面和远程调用接口,方便集成到各种数据分析或业务系统中。
最新的特性表明,Apache Kylin致力于提升其灵活性和可扩展性,通过插件化的方式,使得开发者和企业能够根据自身的技术栈和需求定制Kylin的各个组件,增强了Kylin在大数据分析领域的适用性和竞争力。
Apache Kylin是大数据环境下进行快速多维分析的强大工具,其核心优势在于预计算和高速查询,同时,其不断演进的架构设计使其能够适应日益变化的大数据生态,满足企业的多样化需求。
Apache KYLIN 基本原理—Fast Cubing
剩余27页未读,继续阅读
2018-10-11 上传
点击了解资源详情
2018-03-30 上传
2021-02-24 上传
2023-08-10 上传
2021-06-11 上传

billy_109
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







