Kettle实战指南:配置、转换与任务创建详解
下载需积分: 50 | DOC格式 | 816KB |
更新于2024-09-10
| 99 浏览量 | 举报
Kettle,全称为Pentaho Data Integration(简称PDI),是一个开源的ETL(Extract, Transform, Load)工具,用于数据集成、数据转换和数据加载。本文档提供了一个简化的Kettle使用指南,主要针对实际项目中如何利用该工具进行数据处理。
首先,Kettle的使用涉及以下几个关键步骤:
1. **创建资源库**:
- 在Kettle的登录界面上,通过点击新建按钮进入配置界面,配置存储转换、任务和相关元数据的数据库。建议建立独立的数据库用户,如用户名`admin`和密码`admin`,专门用于Kettle数据管理。
2. **创建转换**:
- 新建转换用于将数据从源库A的表A1转移到目标库B的表B1。具体操作包括:
- 添加"表输入"作为数据源,设置数据库连接。
- 编辑SQL提取语句,确保字段别名与目标表一致且无标点符号。
- 添加"表输出"作为数据目标,配置目标数据库连接和表名。
- 连接表输入和表输出,可以设置数据批量导入。
- 保存并测试转换,可能需要使用"执行SQL脚本"预处理操作。
3. **创建任务**:
- 任务用于串联多个操作,如转换、任务和脚本,形成一个自动化的工作流程。创建任务步骤如下:
- 新建任务,任务中可以包含多个转换,这些转换按照序列执行。
- 可以调整任务的调度、依赖关系等高级特性。
在整个使用过程中,需要注意以下几点:
- SQL编写规范:确保SQL语句正确,字段别名与目标表匹配,没有多余标点,如有参数需启用变量替换。
- 数据处理优化:对于大数据量,注意设置合适的批量导入大小以提高效率。
- 脚本执行:在转换前后可能需要运行脚本,确保数据准备和清理工作顺利进行。
- 安全性:在实际生产环境中,可能需要对数据库连接进行加密和权限管理。
Kettle是一个强大而灵活的工具,熟练掌握其使用可以帮助团队高效地进行数据集成和管理工作。通过本文档提供的步骤,用户能够快速上手并构建复杂的ETL流程。
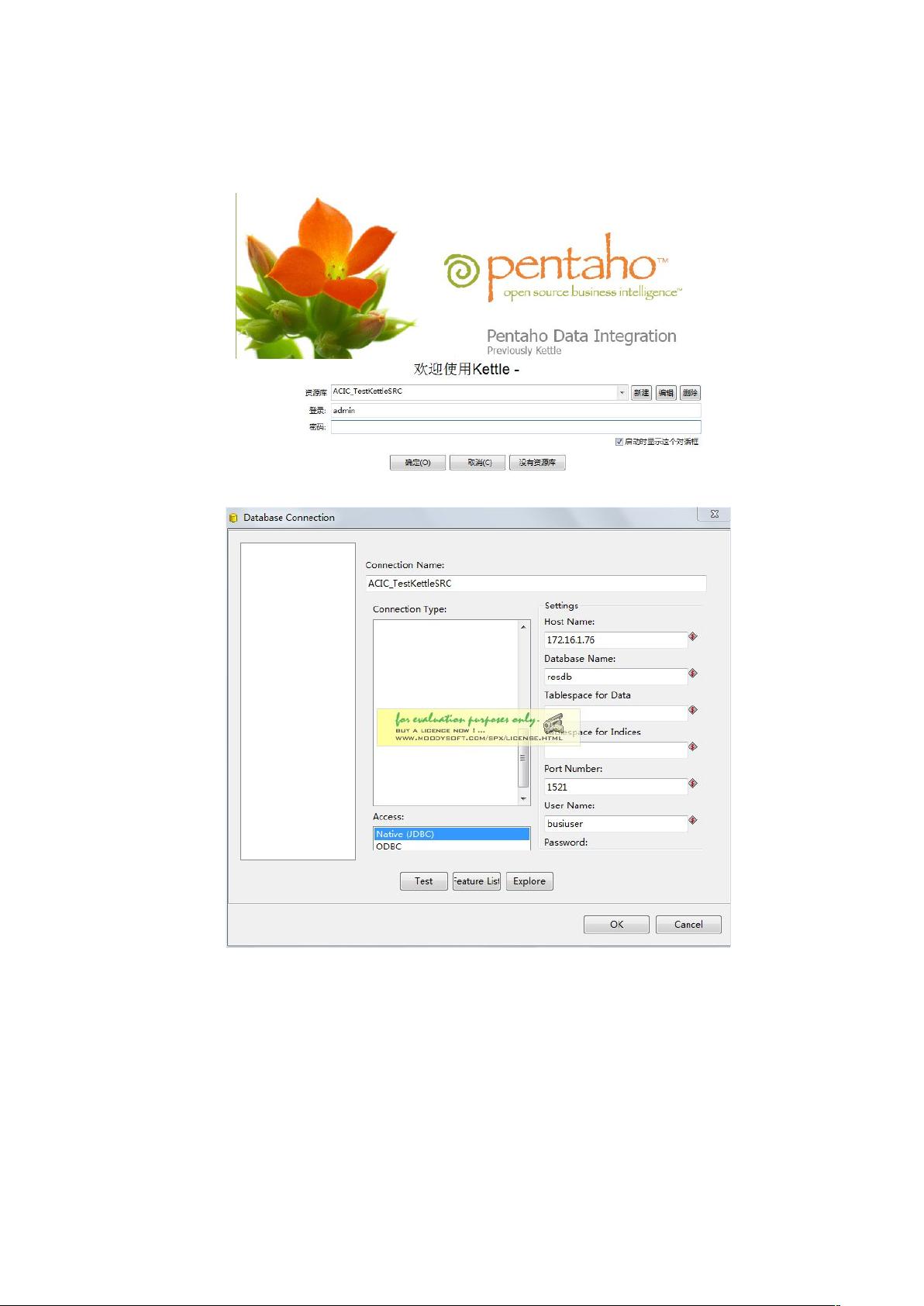
[实现功能]:配置存储相关转换、任务及相关附属信息的数据库
[操作说明]:
1) 进入登陆界面:
2) 点击新建按钮,进入配置界面,填写相关信息
3) 填写完毕,可测试是否成功,成功后,进入如下界面,点创建或更新
剩余11页未读,继续阅读
相关推荐





我认为问问
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 建筑旋流式排水汇集器:创新设计与应用
- 用MATLAB打造功能齐全的私人音乐播放器
- GraceViewPager:修复Android ViewPager常见问题及动态刷新解决方案
- Python3.7.2中GDAL库操作Shapefile教程
- 解决EasyUI弹窗拖拽越界问题的JavaScript代码
- 待办事项应用程序服务器端API的设计与实现
- 建筑排水汇集器的设计原理与应用分析
- Oracle基础教程:自学指南与代码实践
- GNU glibc-linuxthreads压缩包介绍与解析
- 使用mobx-react-router实现MobX与react-router状态同步
- Wireshark:网络抓包分析利器
- 个性化Android壁纸管理应用Just Like开发分享
- 易语言实现VLC面板窗口复制组件教程
- RecyclerView添加头部和尾部视图的示例教程
- React项目PGP Messenger客户端开发指南
- 建筑物风洞型风力发电机的设计与应用
