Hive实现原理:淘宝视角解析
需积分: 9 150 浏览量
更新于2024-07-09
收藏 3.46MB PDF 举报
“Hive实现原理--------from淘宝.pdf”是一份由淘宝的周忱(周敏)编写的关于Hive实现原理的新人培训课程材料。该资料涵盖了Hive的基础概念、如何使用MapReduce实现Hive查询以及Hive在处理数据聚合时的工作流程。
Hive是基于Hadoop的数据仓库工具,它允许通过SQL-like查询语言(HQL)对存储在HDFS上的大数据进行分析处理。Hive的主要优点在于将复杂的分布式计算简化为易于理解的SQL查询,使得非编程背景的用户也能进行大数据分析。
在Hive实现原理中,主要涉及以下几个关键知识点:
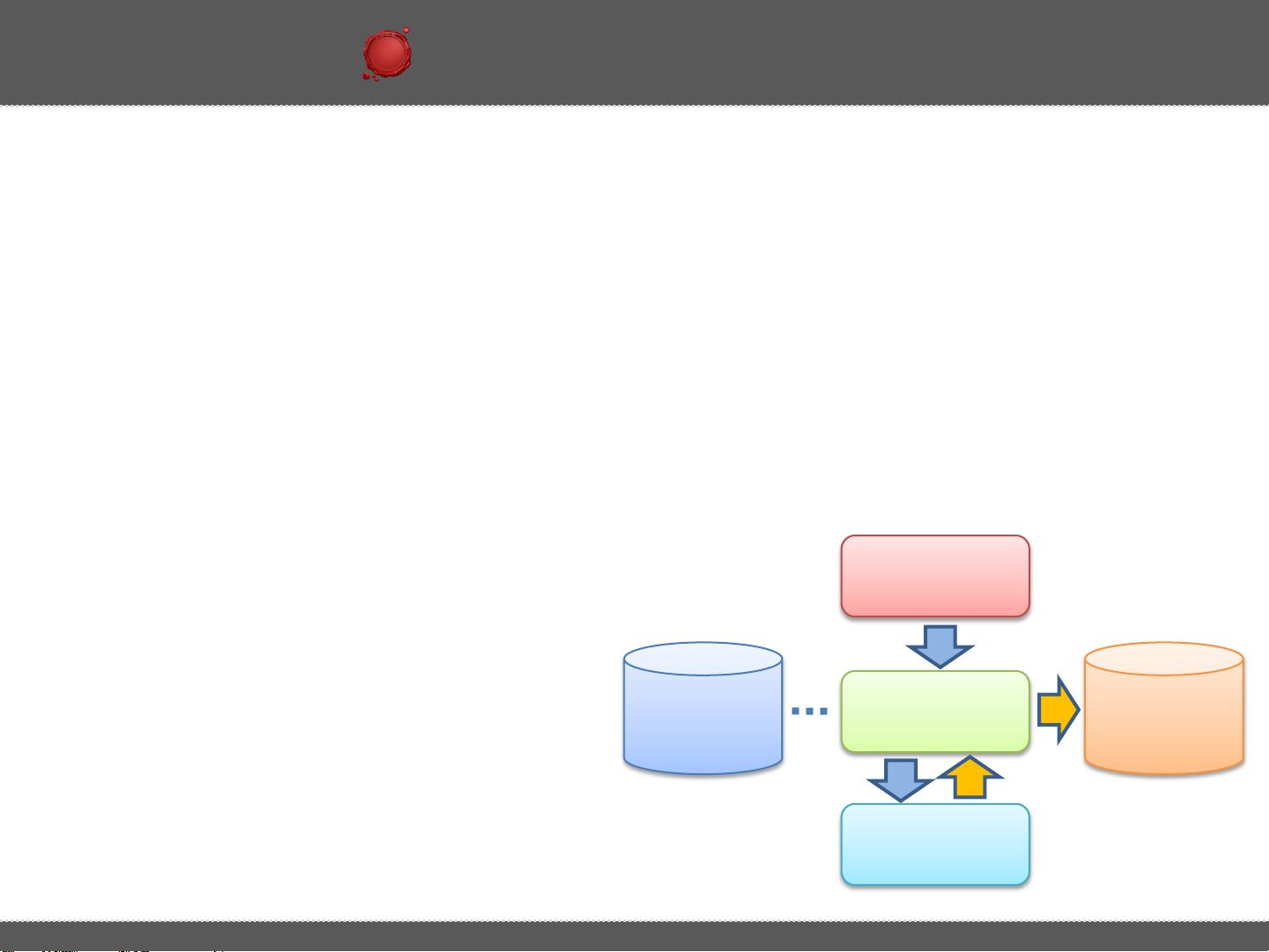
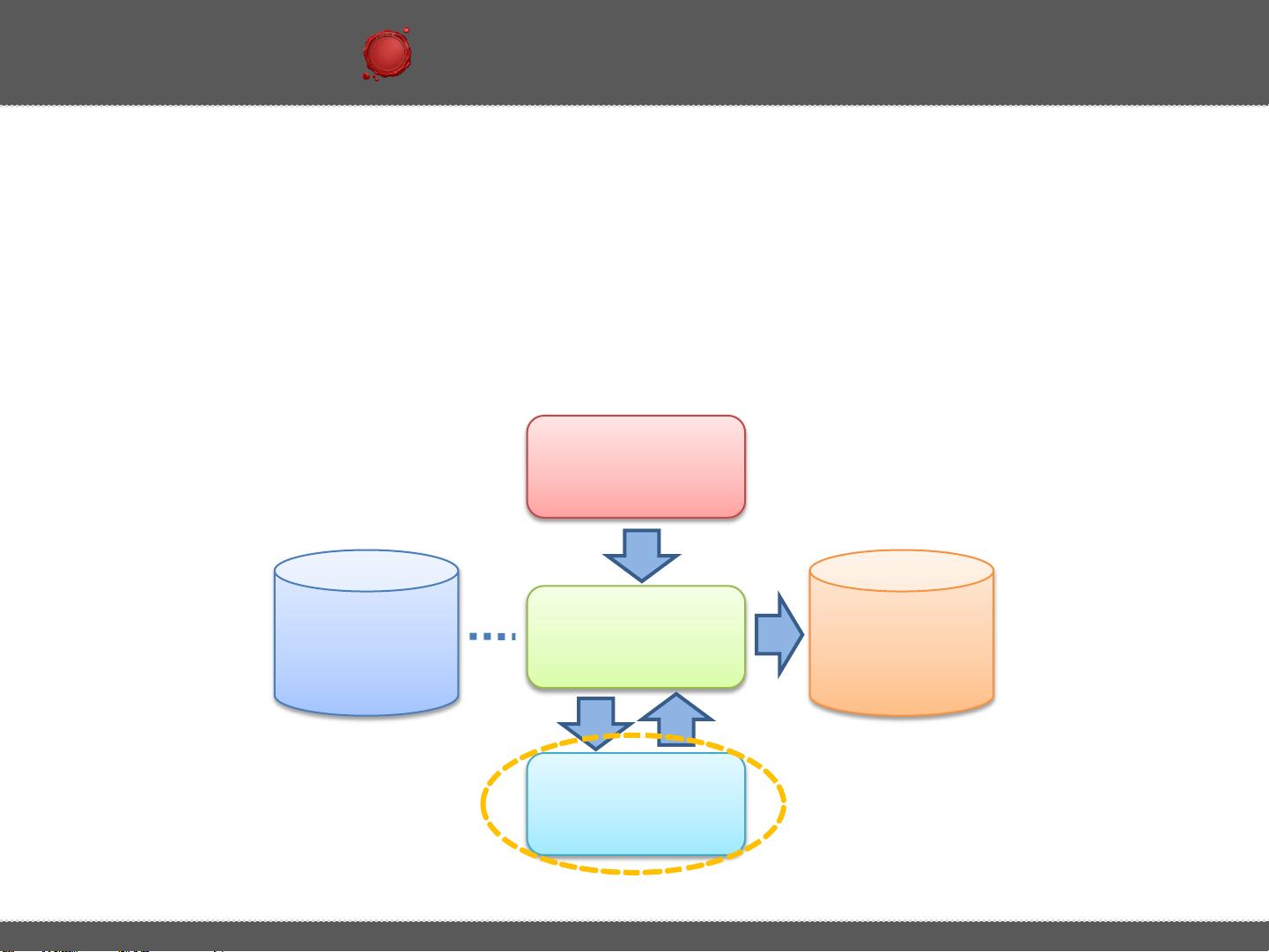
1. **MapReduce**:Hive的执行引擎是基于MapReduce的,这意味着当执行一个Hive查询时,会转化为一系列的MapReduce任务来执行。例如,对于一个简单的分组计数查询`SELECT pageid, age, count(1) FROM pv_users GROUP BY pageid, age;`,Hive会将其分解为Map和Reduce阶段。
- **Map阶段**:数据首先由Mapper处理,Mapper接收原始数据,按照指定的分组键(这里是`pageid`和`age`)进行分区,并生成键值对(key-value pair)。例如,`(pageid, age)`作为key,1作为value。
- **Shuffle阶段**:Mapper产生的键值对被排序并传输到Reducer,确保相同key的数据被分发到同一个Reducer。
- **Sort阶段**:在数据传输过程中,按照key进行排序,以便Reducer可以正确处理每个分组。
- **Reduce阶段**:Reducer负责聚合操作,对每个分组的value进行计数,生成最终结果 `(pageid, age, count)`。
2. **Hive SQL到MapReduce的转化**:Hive将SQL查询语句转化为可执行的MapReduce作业,这个过程称为编译和优化。Hive查询解析器解析输入的HQL,然后生成逻辑计划,经过优化器的优化,生成物理执行计划,最后转化为MapReduce任务。
3. **元数据管理**:Hive维护了一个元数据存储,通常是在MySQL或Derby中,用于存储表结构、分区信息等,这些元数据对于Hive查询的解析和执行至关重要。
4. **Hive的扩展性**:随着技术的发展,Hive也开始支持其他执行引擎,如Tez和Spark,以提高查询性能。Tez和Spark提供更高效的执行模型,减少了MapReduce的启动和通信开销。
5. **Hive的优化策略**:包括选择最佳执行路径、减少数据移动、使用Join优化(如Map-side Join和Bucket Map Join)、使用物化视图等,以提高查询效率。
6. **Hive的存储结构**:Hive支持多种文件格式,如TextFile、SequenceFile、RCFile、ORC、Parquet等,每种格式有其特定的压缩和存储优势,可以根据实际需求选择。
Hive是通过将复杂的大数据处理任务转换为简单的SQL查询,利用Hadoop的分布式计算能力,实现对大规模数据的高效分析。这份淘宝内部的培训材料深入浅出地介绍了Hive的工作原理,对于理解Hive如何处理大数据查询非常有帮助。

Hive执行流程
• 操作符
Hive实现原理
1
操作符
描述
TableScanOperator
扫描hive表数据
ReduceSinkOperator
创建将发送到Reducer端的<Key,Value>对
JoinOperator
Join两份数据
SelectOperator
选择输出列
FileSinkOperator
建立结果数据,输出至文件
FilterOperator
过滤输入数据
GroupByOperator
Group By语句
MapJoinOperator
/*+ mapjoin(t) */
LimitOperator
Limit语句
UnionOperator
Union语句
Taobao Java Team | zhouchen.zm
剩余61页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-08-14 上传
2023-04-26 上传
2023-04-26 上传
2023-04-26 上传
2019-11-06 上传
2023-12-07 上传

wangtaolin00
- 粉丝: 4
- 资源: 34
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
