Hadoop2.0大数据实战:从运维到开发
需积分: 16 109 浏览量
更新于2024-07-22
1
收藏 7.37MB PDF 举报
"ZKPK-Hadoop2.0大数据课程-SZ.pdf 是一份关于Hadoop 2.0的大数据学习资料,由讲师DylanRen提供,涵盖了Hadoop的起源、大数据概念、特性以及应用场景,并对比了传统数据仓库架构与大数据平台架构。"
本文将深入探讨Hadoop 2.0及其在大数据领域的应用。首先,Hadoop源于解决大数据处理的挑战,其设计灵感来源于Google的分布式计算框架。大数据被定义为超出常规处理能力的大量信息,主要特征概括为3V:数据量大(Volume)、数据流动速度快(Velocity)和数据类型多样化(Variety)。这些特征在金融、政府、医疗健康等多个领域都有广泛的应用,例如风险评估、交通优化、社交网络分析等。
Hadoop的出现打破了传统数据仓库的局限,传统的架构难以应对大数据的实时处理和分析需求。相比之下,Hadoop平台架构提供了更高效、可扩展的解决方案。Hadoop的思想源头可以追溯到Google,Google通过使用廉价PC服务器构建大规模集群,解决了数据存储和计算的难题,如PageRank算法,这是Google搜索引擎的核心,利用Map-Reduce进行计算。
Map-Reduce是Google提出的分布式计算模型,它将大型计算任务分解成可并行处理的小任务(Map阶段)和结果整合(Reduce阶段)。这一思想被引入到Hadoop中,形成了Hadoop MapReduce框架,用于处理和分析海量数据。此外,Hadoop还受到了早期开源全文搜索引擎Lucene的影响,Lucene为实现类似Google的搜索功能提供了基础。
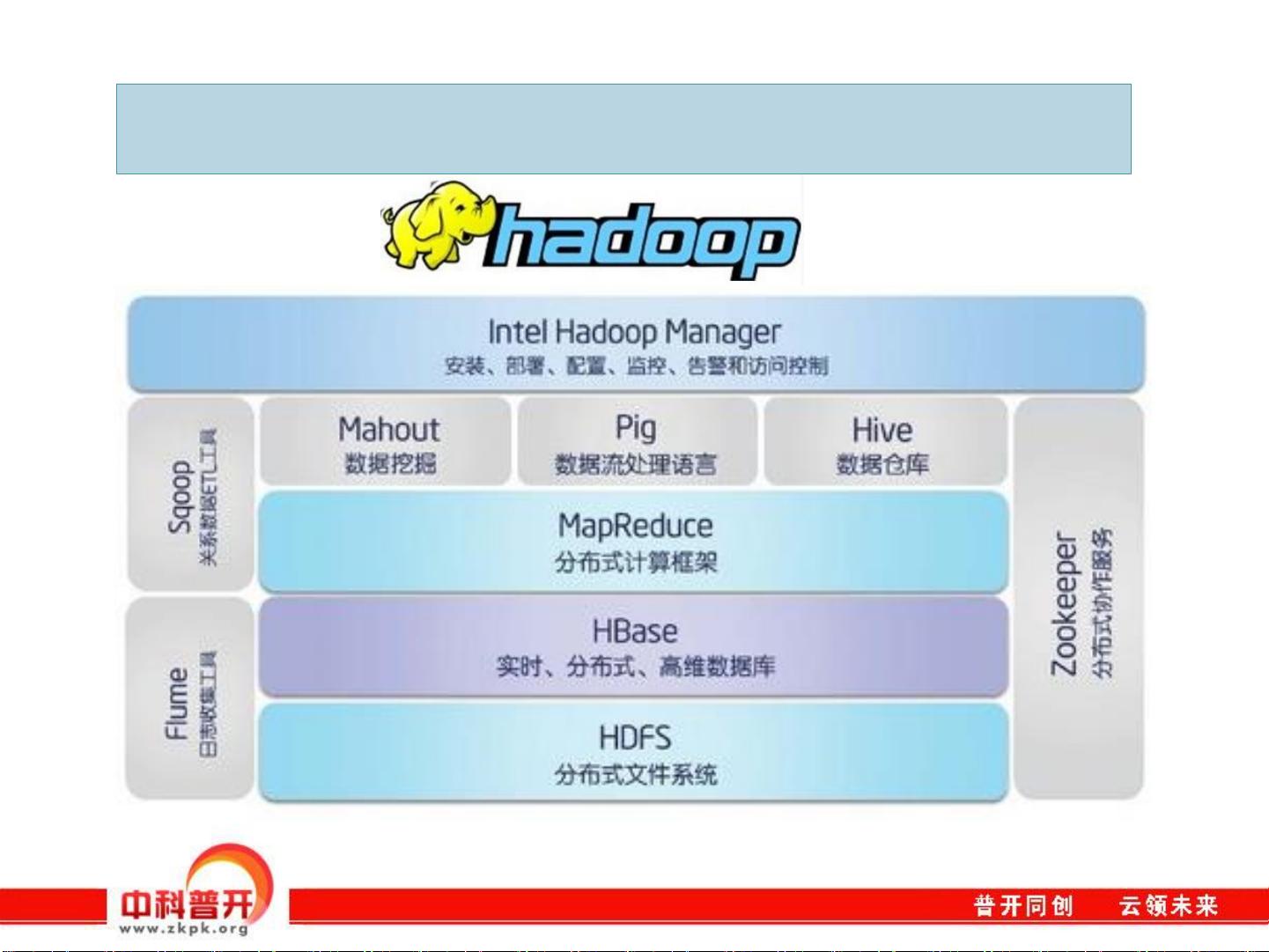
Hadoop 2.0进一步优化了这一框架,引入了YARN资源管理系统,使得Hadoop不仅能处理批处理任务,还能支持更多实时分析和流处理工作负载。Hadoop生态系统还包括HDFS(Hadoop Distributed File System),用于分布式存储,以及HBase、Spark等其他组件,它们共同构成了处理大数据的强大工具集。
这份资料深入浅出地介绍了Hadoop 2.0在大数据环境中的重要地位,以及大数据如何改变了各行各业的数据处理方式。无论是对于初学者还是经验丰富的IT专业人士,都是一份有价值的学习资源,能够帮助读者理解并掌握大数据处理的核心技术和应用。




2022-11-11 上传
2019-11-18 上传
2024-06-20 上传
2021-09-06 上传
2021-05-24 上传
2017-07-31 上传
2022-11-21 上传
2022-11-21 上传

a407790089
- 粉丝: 2
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
