Python爬虫实战:入门到案例剖析
需积分: 13 126 浏览量
更新于2024-07-16
收藏 2.41MB PPTX 举报
Python爬虫实战是一份针对Python编程语言进行网络爬虫技术的实用教程。该PPT主要分为两部分:Python爬虫简介和一个简单的爬虫示例,同时涵盖了爬虫相关的法律问题以及Robots协议。
**Python爬虫简介**
Python爬虫,也称为网络蜘蛛,是一种自动化工具,它模仿人类用户在互联网上漫游并抓取所需信息。网络爬虫的工作原理是通过发送HTTP请求,解析网页内容,提取有用的数据,并将其存储或进一步处理。Python因其丰富的库和易用性,如requests、BeautifulSoup等,被广泛用于爬虫开发。爬虫像一只网络上的“蜘蛛”,在万维网上穿梭,遵循网络协议,获取数据。
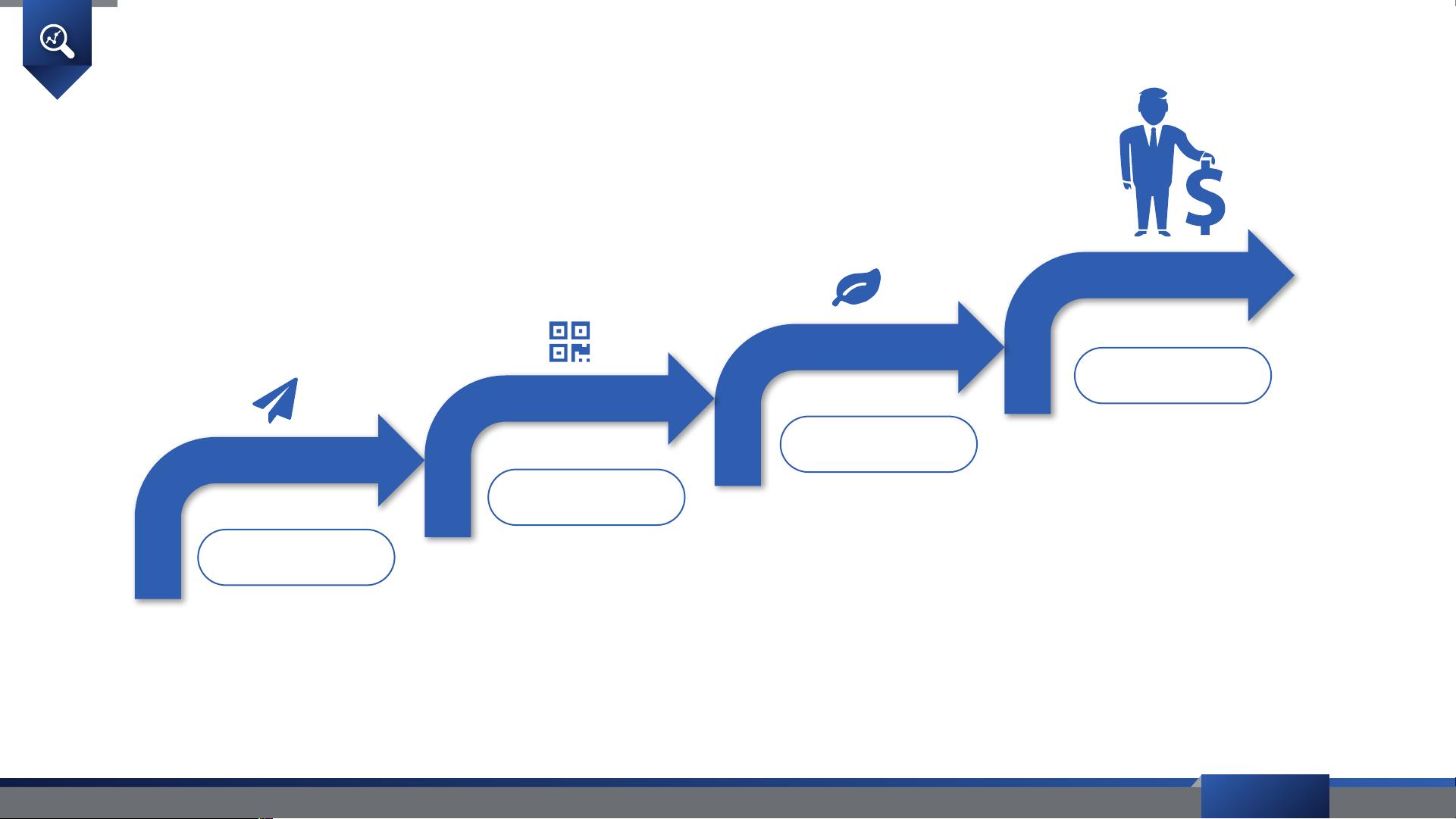
**数据爬取流程**
数据爬取包括四个关键步骤:数据下载、数据解析、数据整合和数据存储。首先,通过urllib.request等库下载原始网页,然后解析HTML或XML文档,提取各种类型和结构的数据。数据整合至关重要,这涉及对信息进行规划处理,消除孤岛效应,提高数据价值的利用效率。存储阶段通常选择关系数据库(如MySQL、PostgreSQL)、NoSQL数据库(如MongoDB)或分布式文件系统(如Hadoop HDFS)。
**法律与伦理考虑**
在进行爬虫开发时,必须遵守相关法律法规,尊重网站的Robots协议。Robots协议是一套指导爬虫如何访问网站的指南,如果无视这些规则,可能会导致网站封禁爬虫,甚至可能面临法律纠纷。了解和遵守版权法、隐私法等,确保合法抓取数据。
**一个简单的爬虫示例**
演示了爬虫的三个基本要素:抓取、分析和存储。使用Python 3.x版本,开发者可以借助Sublime Text 3等开发工具,通过requests库发起请求,如`import requests`。示例代码展示了如何使用urllib.request模块打开URL并获取响应内容。
**开发工具和库**
推荐使用Python 3.x版本,以及requests库进行基础抓取。在Python 2.x中,urllib和urllib2曾是常用的抓取工具,但在Python 3.x中已经弃用,改用urllib.request。在命令行中安装类库可以通过pip3进行,如`pip3 install requests`。
这份Python爬虫实战PPT提供了从基础知识到实践应用的全面教学,帮助学习者理解和掌握如何利用Python构建高效、合法的网络爬虫系统。
28
数据爬取的流程
数据下载
从互联网下载原始
网页
数据解析
从 XML/HTML 等
抽取多种类型和结
构的数据
数据整合
前瞻性的设计规划
和整合处理,是消
除信息孤岛的有力
手段,利于高效地
发挥数据的价值
数据存储
将整理和分类的数
据进行针对性的存
储
( 关 系 数 据
库, Nosql, 分布
式文件系统)
剩余23页未读,继续阅读
2020-04-09 上传
2020-05-02 上传
2021-09-25 上传
2021-05-16 上传
2023-09-08 上传
2019-12-04 上传
2021-05-16 上传

TT123456XY
- 粉丝: 5
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
