面板数据中的固定效应模型:原理与应用
版权申诉
68 浏览量
更新于2024-06-26
收藏 3.25MB DOCX 举报
"固定效应模型的估量原理说明"
固定效应模型是统计分析中处理面板数据(Panel Data)的一种重要方法,特别适用于分析那些存在不可观测个体特定效应(Fixed Effects)的情况。这种模型常用于经济、社会学和管理科学等领域,以研究不同个体之间的差异和时间序列上的变化。
在面板数据线性回归模型中,固定效应模型假设不同截面(如不同的个体、国家或地区)的截距项不同,但斜率系数是相同的。这意味着模型中每个个体都有其特定的固有特征或效应,这些特征或效应不会随时间改变,只在不同个体间有所不同。例如,在研究家庭消费与收入的关系时,不同家庭可能由于自身特有的条件(如地理位置、家庭规模等)导致消费习惯的差异,这些差异是固定的,并不随时间变化。
固定效应模型分为三种类型:
1. 个体固定效应模型:适用于不同个体在不同时间点的数据,例如上述描述中的中国各省级地域居民消费与收入的数据。在这个模型中,不同省份的家庭消费可能受到省份本身特性的影响,而这些特性是稳定的,不随时间变化。
检验固定效应模型的合理性通常采用F统计量。通过比较无约束模型(如随机效果模型或混合模型)和有约束模型(固定效果模型)的残差平方和,构建F统计量,然后进行F检验。零假设是所有固定效应均为零,如果拒绝这个零假设,则说明设定固定效应模型是有意义的。
在实际应用中,我们可能会经历以下步骤:
1. 数据准备:收集并整理面板数据,例如这里提到的中国东北、华北、华东15个省级地域的年人均消费和收入数据。
2. 创建面板数据工作文件:将数据输入到统计软件中,创建适合分析的面板数据格式。
3. 定义变量:定义序列名,如居民家庭人均消费(consume)和人均收入(income)。
4. 选择模型和进行估计:选择合适的面板模型进行估计,比如使用固定效应模型。
5. 面板单位根检验:在进行回归分析前,先进行单位根检验以确保数据的平稳性。
固定效应模型的优点在于能够控制未观测到的个体特异性因素,使得模型的估计结果更具有解释力。然而,固定效应模型的缺点是无法识别和估计那些随时间变化的变量的影响,因为这些变量会被个体固定效应吸收。因此,在建模时需根据研究问题和数据特性选择合适的方法。在上述案例中,通过对中国各省级地域的数据进行固定效应模型分析,可以更好地理解消费与收入之间的关系,同时消除省份固有特性对结果的影响。
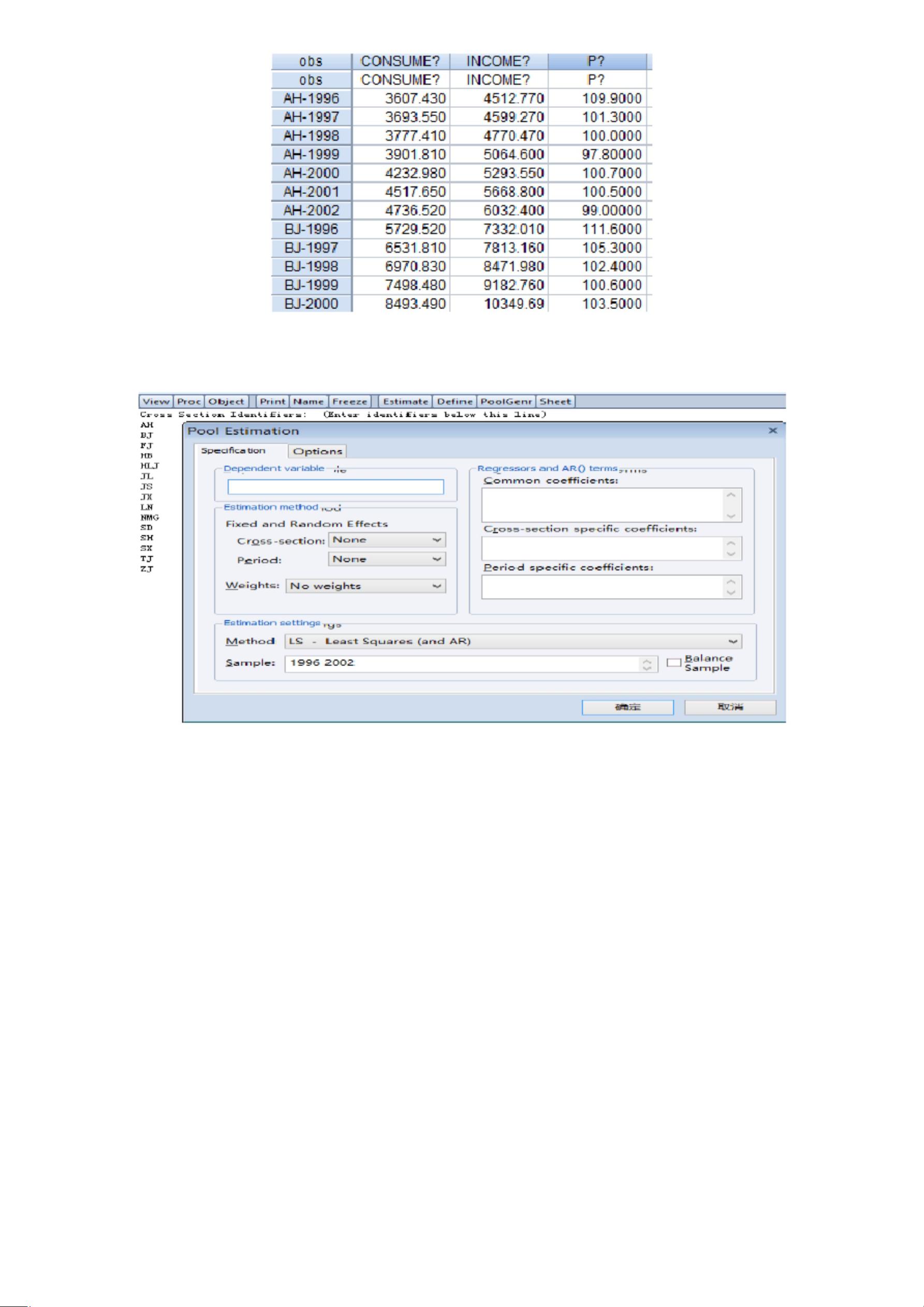
2.估量操作:
步骤:(1)点击 poolmodel——Estimate
对话框说明
剩余23页未读,继续阅读
2023-03-13 上传
2023-03-13 上传
2023-03-13 上传

若♡
- 粉丝: 6388
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
