Python数据科学案例分析:Chipotle餐厅和欧洲杯数据探索
版权申诉
117 浏览量
更新于2024-06-26
收藏 3.87MB DOCX 举报
Python 数据科学案例分析
Python 数据科学是一门重要的学科,涵盖了数据的收集、清洁、分析和可视化等多个方面。本文将通过两个案例,即 Chipotle 餐厅案例分析和欧洲杯案例,展示 Python 在数据科学中的应用。
**Chipotle 餐厅案例分析**
在这个案例中,我们将使用 Python 的 pandas 库来读取和分析 Chipotle 餐厅的订单数据。
**数据读入**
我们使用 `pd.read_csv()` 函数来读取 Chipotle 餐厅的订单数据,指定编码为 `gbk`,分隔符为 `\t`。
**数据概要**
使用 `info()` 函数来获取数据的概要信息,包括每列的数据类型、缺失值的数量等。
**缺失值和重复值处理**
使用 `isnull().sum()` 函数来检测缺失值,然后使用 `fillna()` 函数来填充缺失值。对于重复值,我们使用 `duplicated()` 函数来检测,然后使用 `drop_duplicates()` 函数来删除重复值。
**自定义查询**
我们使用 pandas 库来实现以下自定义查询:
1. 一共有多少种不同的菜品被下单?使用 `nunique()` 函数来计算。
2. 点餐的顾客最喜欢点哪种食品?使用 `value_counts()` 函数来计算。
3. 最贵的食物是什么?使用 `sort_values()` 函数来排序,然后使用 `set_index()` 函数来设置索引。
4. 每个订单号所点菜品的总额?使用 `groupby()` 函数来分组,然后使用 `sum()` 函数来计算。
5. 按照每单所下菜品数进行统计?使用 `value_counts()` 函数来计算。
**欧洲杯案例**
在这个案例中,我们将使用 Python 的 pandas 库来读取和分析欧洲杯的比赛数据。
**读入数据**
我们使用 `pd.read_csv()` 函数来读取欧洲杯的比赛数据,指定编码为 `gbk`。
**数据概览**
使用 `info()` 函数来获取数据的概要信息,包括每列的数据类型、缺失值的数量等。
**重复值与缺失值处理**
使用 `duplicated()` 函数来检测重复值,然后使用 `drop_duplicates()` 函数来删除重复值。对于缺失值,我们使用 `isnull().sum()` 函数来检测,然后使用 `fillna()` 函数来填充缺失值。
**自定义查询**
我们使用 pandas 库来实现以下自定义查询:
1. 进球数小于 6 的球队?使用布尔索引来筛选数据。
2. 点球进球数最多的球队?使用 `sort_values()` 函数来排序,然后使用 `set_index()` 函数来设置索引。
**结论**
通过这两个案例,我们可以看到 Python 在数据科学中的应用。在数据科学中,Python 是一个非常重要的工具,可以帮助我们快速地读取、分析和可视化数据。同时,Python 的 pandas 库提供了强大的数据分析功能,能够满足我们的需求。
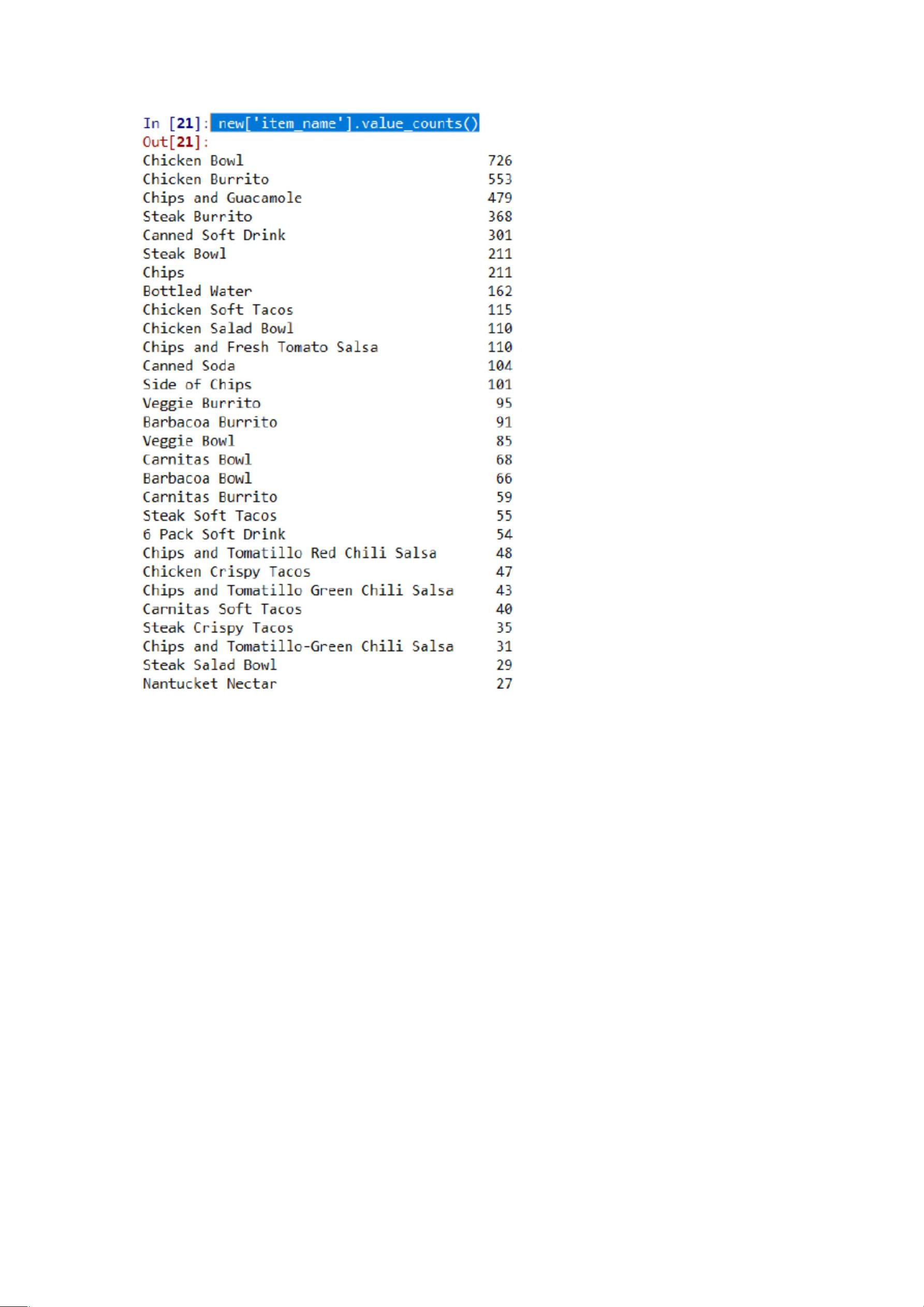
由高至低排序可见点的最多的食物是 chicken bowl
3.最贵的食物是什么
a=new.sort_values(by='item_price',ascending=False)
a.set_index('item_name')
剩余22页未读,继续阅读
2022-07-04 上传
2022-07-12 上传
2024-07-20 上传
2022-12-17 上传
2022-11-10 上传
2022-06-06 上传
2023-06-12 上传









