IBM SPSS Modeler构建线性回归预测模型
版权申诉
"本文将介绍如何使用IBM SPSS Modeler构建线性回归预测模型,以进行理赔欺诈检测。"
在数据分析领域,线性回归是一种基本且重要的预测模型,尤其适用于研究两个或多个变量之间的关系。IBM SPSS Modeler是一款强大的数据挖掘工具,它允许用户通过直观的工作流程来构建和评估各种预测模型,包括线性回归模型。
线性回归分析的目标是找到一个最佳的直线(线性函数),这条直线能够最好地描述因变量(在理赔欺诈检测模型中可能是索赔金额)与一个或多个自变量(如疾病严重程度、年龄和住院天数)之间的关系。在这个模型中,自变量影响因变量,而模型参数(斜率和截距)代表了这种影响的强度。
在IBM SPSS Modeler中,建立线性回归模型通常涉及以下步骤:
1. 数据准备:导入包含历史理赔记录的数据集,如CSV文件InsClaim.dat,确保数据质量良好,无缺失值或异常值。
2. 特征选择:选择可能影响索赔金额的特征,如ASG、AGE和LOS作为自变量。
3. 模型构建:在SPSS Modeler中选择“线性回归”节点,将选定的特征输入模型,系统会自动计算最佳拟合线,以最小化预测值与实际值之间的差异。
4. 模型评估:通过统计指标如R²(决定系数)来评估模型的拟合度。R²值接近1表示模型解释了大部分的变异,而低R²值则表明模型的预测能力较弱。
5. 预测与应用:如果模型效果满意,可以使用它来预测新的理赔金额。对于预测误差较大的案例,可能需要进一步调查,以识别潜在的欺诈行为。
6. 错误分析:分析预测误差较大的样本,可能揭示出模型的局限性或者新发现的模式,这可能需要改进模型,例如引入非线性模型,或者使用更复杂的算法如决策树、随机森林等。
7. 模型验证与优化:通过交叉验证或者保留一部分数据作为测试集,验证模型的泛化能力,如果需要,可以调整模型参数或者尝试不同的模型。
8. 部署与监控:最后,将建立好的模型应用于实际业务,对新的理赔数据进行预测,并定期评估模型性能,以确保其持续的有效性。
IBM SPSS Modeler提供了一个全面的平台,使得数据科学家和分析师能够高效地构建和应用线性回归模型,以解决实际问题,如理赔欺诈检测。通过理解模型的输出和解释,可以更好地洞察数据中的模式,并做出更有依据的决策。
!
用
SPSS Modeler
建立线性回归预测模型
Modeler
线性回归模型示例
线性回归模型是一种常用的统计学模型。IBM SPSS Modeler 是一个强大的数据挖掘分
析工具, 本文将介绍如何用它进行线性回归预测模型的建立和使用。 在本文中,将通
过建立一个理赔欺诈检测模型的实例来展示如何利用 IBM SPSS Modeler 建立线性回归
预测模型以及如何解释及应用该模型。
简介!
回归分析(Regression Analysis)是一种统计学上对数据进行分析的方法, 主要是希望
探讨数据之间是否有一种特定关系。线性回归分析是最常见的一种回归分析, 它用线
性函数来对因变量及自变量进行建模(自变量和因变量都必须是连续型变量), 这种
方式产生的模型称为线性模型。线性回归模型由于其运算速度快、直观性强以及参数
易于确定等特点, 在实践中应用最为广泛,也是建立预测模型的重要手段之一。
IBM SPSS Modeler 是一组数据挖掘工具,通过这些工具可以采用商业技术快速建立预
测性模型, 并将其应用于商业活动,从而改进决策过程。在后面的文章中,将通过一
个理赔欺诈检测的实际 商业应用来介绍如何用 IBM SPSS Modeler 建立、分析及应用
线性回归分析模型。
用线性回归建立理赔欺诈检测模型!
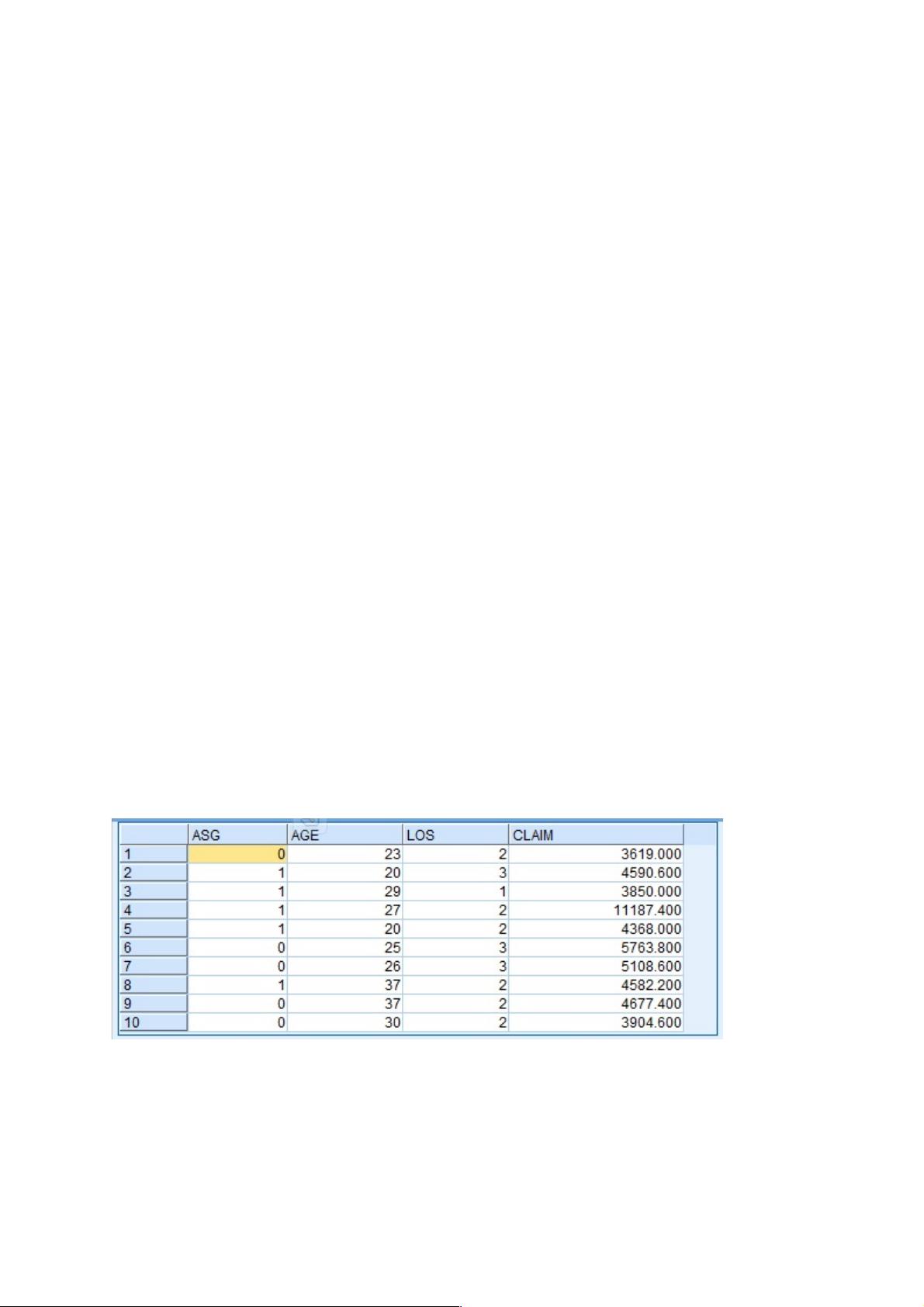
在本例中,用于建立模型的数据存放在 InsClaim.dat 中,该文件是一个 CSV 格式的数
据文件, 存储了某医院以往医疗保险理赔的历史记录。该文件共有 293 条记录,每条
记录有 4 个字段, 分别是 ASG(疾病严重程度)、AGE(年龄)、LOS(住院天数)
和 CLAIM(索赔数额)。 图 1 显示了该数据的部分内容。
图!1.!历史理赔数据文件!
!
任务与计划!
基于已有的数据,我们的任务主要有如下内容:
• 建立理赔金额预测模型,该模型将基于病人的疾病严重程度、住院天数及年龄
预测其索赔金额。!
下载后可阅读完整内容,剩余7页未读,立即下载

普通网友
- 粉丝: 13w+
- 资源: 9195
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
