智慧政务:自然语言处理在文本挖掘中的应用
需积分: 0 158 浏览量
更新于2024-08-05
收藏 347KB PDF 举报
"第八届“泰迪杯”数据挖掘挑战赛C题——'智慧政务’中的文本挖掘应用,涉及群众留言分类和热点问题挖掘。挑战包括建立一级标签分类模型,以及设计并实施热点问题的挖掘策略。"
在这个数据挖掘挑战中,主要关注的是如何运用自然语言处理(NLP)和文本挖掘技术来处理政府政务中的文本数据。任务分为两部分:
1. **群众留言分类**
这个任务要求参赛者根据提供的内容分类三级标签体系,构建一个能够自动分类群众留言的一级标签模型。一级标签分类模型的目标是帮助政府更有效地分配留言到相应的职能机构,以提高工作效率。这需要参赛者对附件2的数据进行深度学习或者机器学习算法的训练,如朴素贝叶斯、支持向量机、决策树、随机森林或现代的深度学习模型(如卷积神经网络CNN或transformer系列模型)。评价标准是F-Score,它综合了查准率(Precision)和查全率(Recall),能全面评估模型在所有类别的性能。
2. **热点问题挖掘**
在这个环节,参赛者需要找出在特定时间段内被集中反映的问题,这些问题可以是针对特定地点或人群的。这涉及到文本聚类和情感分析技术,可能需要定义一个热度评价指标来量化问题的严重性和关注度。完成这个任务后,需要按照指定的表格格式提供排名前5的热点问题及其详细信息,包括问题ID、热度指数、时间范围、地点/人群和问题描述。
为了实现这些目标,Python编程语言将发挥关键作用,因为它有丰富的NLP库,如NLTK、spaCy、TextBlob和Gensim,以及用于机器学习和深度学习的库,如scikit-learn、TensorFlow和PyTorch。参赛者需要熟悉这些工具,以及如何利用它们来处理和理解大规模文本数据,进行有效特征提取,训练和优化模型,并最终实现自动化和精准的文本处理任务。
此外,挑战还要求参赛者提交测试结果,这意味着他们不仅需要开发有效的算法,还需要将其封装成可以接受新数据并生成预测的程序。这需要良好的编程实践,包括代码的可读性、可维护性和文档化。
这个挑战旨在考察参赛者的NLP理论知识,数据分析能力,以及用Python实现复杂文本挖掘解决方案的技能。通过解决这些问题,参赛者不仅可以提升自己的技术能力,还能为政府提供智能化的决策支持,提升社会治理的效率和质量。
1
第八届“泰迪杯”数据挖掘挑战赛——
C 题:“智慧政务”中的文本挖掘应用
一、问题背景
近年来,随着微信、微博、市长信箱、阳光热线等网络问政平台逐步成为政府了解民意、
汇聚民智、凝聚民气的重要渠道,各类社情民意相关的文本数据量不断攀升,给以往主要依
靠人工来进行留言划分和热点整理的相关部门的工作带来了极大挑战。同时,随着大数据、
云计算、人工智能等技术的发展,建立基于自然语言处理技术的智慧政务系统已经是社会治
理创新发展的新趋势,对提升政府的管理水平和施政效率具有极大的推动作用。
附件给出了收集自互联网公开来源的群众问政留言记录,及相关部门对部分群众留言的
答复意见。请利用自然语言处理和文本挖掘的方法解决下面的问题。
二、解决问题
1、群众留言分类
在处理网络问政平台的群众留言时,工作人员首先按照一定的划分体系(参考附件 1 提
供的内容分类三级标签体系)对留言进行分类,以便后续将群众留言分派至相应的职能部门
处理。目前,大部分电子政务系统还是依靠人工根据经验处理,存在工作量大、效率低,且
差错率高等问题。请根据附件 2 给出的数据,建立关于留言内容的一级标签分类模型。
通常使用 F-Score 对分类方法进行评价:
1
1
2
1
n
ii
i
ii
PR
F
n P R
=
=
+
,
其中
i
P
为第 i 类的查准率,
i
R
为第 i 类的查全率。
2、热点问题挖掘
某一时段内群众集中反映的某一问题可称为热点问题,如“XXX 小区多位业主多次反映
入夏以来小区楼下烧烤店深夜经营导致噪音和油烟扰民”。及时发现热点问题,有助于相关
部门进行有针对性地处理,提升服务效率。请根据附件 3 将某一时段内反映特定地点或特定
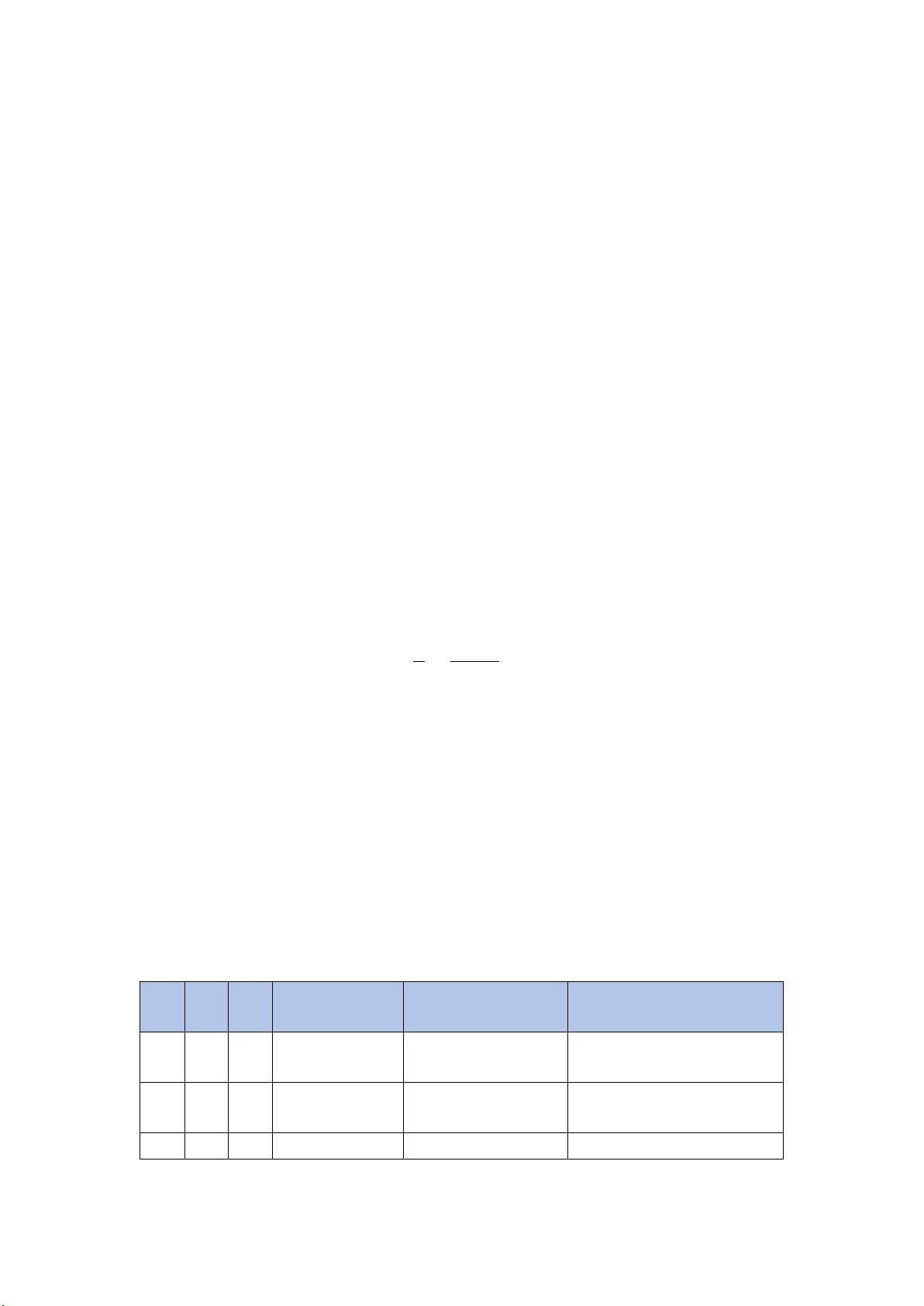
人群问题的留言进行归类,定义合理的热度评价指标,并给出评价结果,按表 1 的格式给出
排名前 5 的热点问题,并保存为文件“热点问题表.xls”。按表 2 的格式给出相应热点问题
对应的留言信息,并保存为“热点问题留言明细表.xls”。
表 1-热点问题表
热度
排名
问题
ID
热度
指数
时间范围
地点/人群
问题描述
1
1
…
2019/08/18 至
2019/09/04
A 市 A5 区魅力之城小
区
小区临街餐饮店油烟噪音扰民
2
2
…
2017/06/08 至
2019/11/22
A 市经济学院学生
学校强制学生去定点企业实习
…
…
…
…
…
…
下载后可阅读完整内容,剩余3页未读,立即下载
2021-08-15 上传
2012-11-19 上传
2008-12-06 上传

雨后的印
- 粉丝: 21
- 资源: 288
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握Jive for Android SDK:示例应用的使用指南
- Python中的贝叶斯建模与概率编程指南
- 自动化NBA球员统计分析与电子邮件报告工具
- 下载安卓购物经理带源代码完整项目
- 图片压缩包中的内容解密
- C++基础教程视频-数据类型与运算符详解
- 探索Java中的曼德布罗图形绘制
- VTK9.3.0 64位SDK包发布,图像处理开发利器
- 自导向运载平台的行业设计方案解读
- 自定义 Datadog 代理检查:Python 实现与应用
- 基于Python实现的商品推荐系统源码与项目说明
- PMing繁体版字体下载,设计师必备素材
- 软件工程餐厅项目存储库:Java语言实践
- 康佳LED55R6000U电视机固件升级指南
- Sublime Text状态栏插件:ShowOpenFiles功能详解
- 一站式部署thinksns社交系统,小白轻松上手
