掌握Hadoop任务调度:流程、内置与自定义
需积分: 28 23 浏览量
更新于2024-07-19
收藏 966KB PDF 举报
Hadoop任务调度器是Hadoop框架中的关键组件,它负责在集群中管理和分配工作负载,确保数据处理过程的高效运行。本文将深入探讨Hadoop调度的基本原理和实现机制。
首先,让我们从基础知识开始。Hadoop任务调度的基础是心跳机制(heartbeat),即TaskTracker定期(默认每3秒)通过RPC与JobTracker进行通信,报告其状态和任务执行情况。心跳机制中,TaskTracker会汇报自身的状态信息,包括资源使用情况,如mapslot和reduceslot(资源划分单位,分别用于map任务和reduce任务)。这些slot的数量由配置参数`mapred.tasktracker.map.tasks.maximum`和`mapred.tasktracker.reduce.tasks.maximum`来设置。
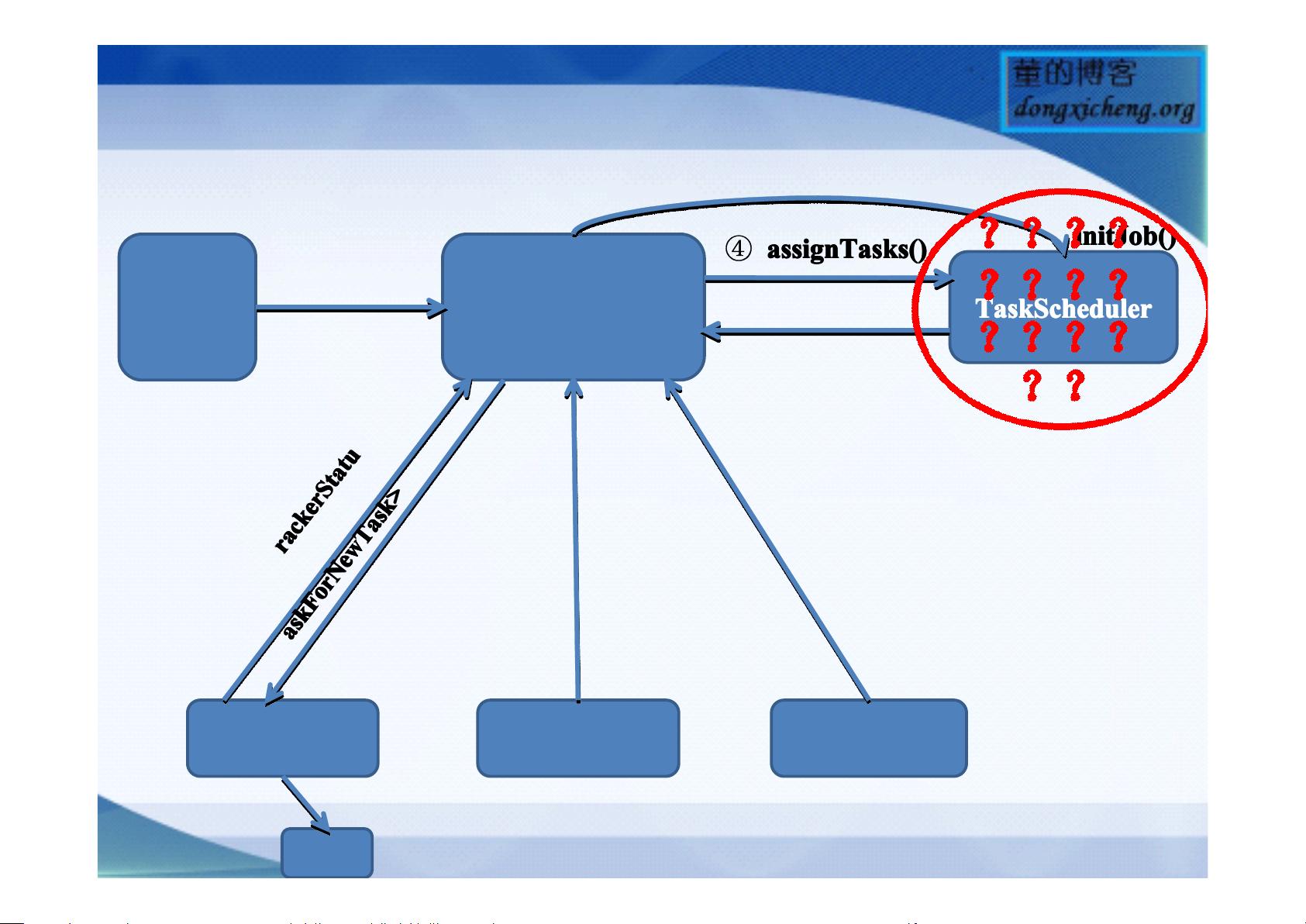
Hadoop的调度流程涉及两个主要角色:TaskTracker和JobTracker。TaskTracker负责执行具体的任务,而JobTracker则是全局的资源管理和协调中心。当JobTracker收到一个新的作业(job)时,它会通过`assignTasks()`方法将任务分配给可用的TaskTracker。这个过程会考虑到各个TaskTracker的负载和能力,以确保任务均衡地分布在集群中。
`assignTasks()`方法可能包括以下几个步骤:
1. TaskTracker状态检查:JobTracker会检查每个TaskTracker的当前任务列表(tasklist)。
2. 负载评估:根据TaskTracker的处理能力和当前任务执行进度,JobTracker决定是否可以分配新的任务。
3. 任务分配:将合适的任务分配给最适合的TaskTracker,并更新TaskTracker的状态。
在整个调度过程中,TaskScheduler扮演着核心角色,它根据资源分配策略(如FIFO, Fair Sharing, 或者自定义策略)来决定任务的优先级和分配。Hadoop的默认调度器基于公平性原则,但也允许用户编写自己的定制调度器,以满足特定场景的需求。
总结起来,Hadoop任务调度器是Hadoop分布式计算的核心组成部分,通过心跳机制、负载均衡和任务分配策略,确保了大规模数据处理任务的高效执行。理解并掌握这一部分对于Hadoop开发者和运维人员至关重要,因为合理的调度策略直接影响到系统的性能和资源利用率。如果你需要深入了解或定制自己的调度器,参考技术博客《dongxicheng.org》和博主的微博《西成懂》可以获取更多实用指导和实践案例。
Hadoop
Hadoop
Hadoop
Hadoop
调度 流程
TaskTracker
TaskTracker
TaskTracker
TaskTracker TaskTracker
TaskTracker
TaskTracker
TaskTracker TaskTracker
TaskTracker
TaskTracker
TaskTracker
JobTracker
JobTracker
JobTracker
JobTracker
TaskScheduler
TaskScheduler
TaskScheduler
TaskScheduler
④
assignTasks()
assignTasks()
assignTasks()
assignTasks()
⑤
task list
task list
task list
task list
③
<TaskTrackerStatu
<TaskTrackerStatu
<TaskTrackerStatu
<TaskTrackerStatu
s
s
s
s
,
,
,
,
askForNewTask>
askForNewTask>
askForNewTask>
askForNewTask>
⑥
tasks-to-lauch
tasks-to-lauch
tasks-to-lauch
tasks-to-lauch
Task
Task
Task
Task
⑦
launch
launch
launch
launch
③ ③
Client
Client
Client
Client
①
submitJob()
submitJob()
submitJob()
submitJob()
②
notify
notify
notify
notify
initJob()
initJob()
initJob()
initJob()
剩余22页未读,继续阅读
2021-06-24 上传
2019-01-22 上传
点击了解资源详情
2014-01-06 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

菜鸟一碗好汤
- 粉丝: 1
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
