谷歌MapReduce模型详解:并行处理大数据的关键
需积分: 9 167 浏览量
更新于2024-09-12
收藏 444KB PDF 举报
MapReduce是一个由Google提出并应用于大规模数据处理的编程模型和算法框架,它的核心理念是将复杂的并行计算任务分解为两个主要步骤:Map阶段和Reduce阶段。在这个模型中,用户首先编写Map函数,它接收键值对数据作为输入,通过应用特定的处理逻辑,将原始数据转换成中间的键值对形式。Map函数的输出是一系列经过初步处理的数据,这些数据随后会被发送到Reduce函数进行进一步的聚合。
在Reduce阶段,系统会收集所有具有相同键的中间值,然后应用另一个用户提供的函数来对这些值进行合并或聚合,得到最终的结果。这种设计使得即使是没有并行计算和分布式处理经验的开发者也能利用分布式环境的强大能力,通过简单的接口编写出高效处理大规模数据的工作流程。
MapReduce架构的关键在于其对输入数据的分割、调度和错误处理的自动化。它能在成千上万台普通配置的计算机组成的集群上实现并行处理,例如一个典型的MapReduce任务可能涉及数千台机器协同工作,处理的数据量达到TB级别。这种架构的优势在于其易于编程,Google的程序员已经实现了数百个MapReduce程序,它们在Google的集群上每日运行数千个实例,用于处理诸如网页抓取、日志分析、索引构建等各种场景。
然而,设计MapReduce模型的初衷是为了解决大规模数据处理中的复杂问题,如数据分布、负载均衡、容错机制等。通过提供抽象的编程模型,MapReduce简化了开发者在并行计算方面的挑战,使得他们只需关注数据处理的核心逻辑,而不是底层的并发和分布式细节。这使得原本可能需要大量代码和复杂架构才能解决的问题,通过MapReduce变得相对直观和高效。
总结来说,MapReduce是一种强大的分布式计算工具,通过分解和并行化处理,使得大规模数据处理变得更加容易和高效,对推动现代互联网公司如Google的数据驱动决策起到了关键作用。
2. 普通的网络硬件设备,每个机器的带宽为百兆或者千兆,但是远小于网络的平均带宽的一半。 ( alex 注:这里
需要网络专家解释一下了)
3. 集群中包含成百上千的机器,因此,机器故障是常态。
4. 存储为廉价的内置 IDE 硬盘。一个内部分布式文件系统用来管理存储在这些磁盘上的数据。文件系统通过数据
复制来在不可靠的硬件上保证数据的可靠性和有效性。
5. 用户提交工作( job )给调度系统。每个工作( job )都包含一系列的任务( task ) ,调度系统将这些任务调度到 集
群中多台可用的机器上。
3.1 、执行概括
通过将 Map 调用的输入数据自动分割为 M 个数据片段的集合, Map 调用被分布到多台机器上执行。输入的数据
片段能够在不同的机器上并行处理。 使用分区函数将 Map 调用产生的中间 key 值分成 R
个不同分区 (例如,
hash(key )
m od
R
) ,
Reduce 调用也被分布到多台机器上执行。分区数量( R )和分区函数由用户来指定。
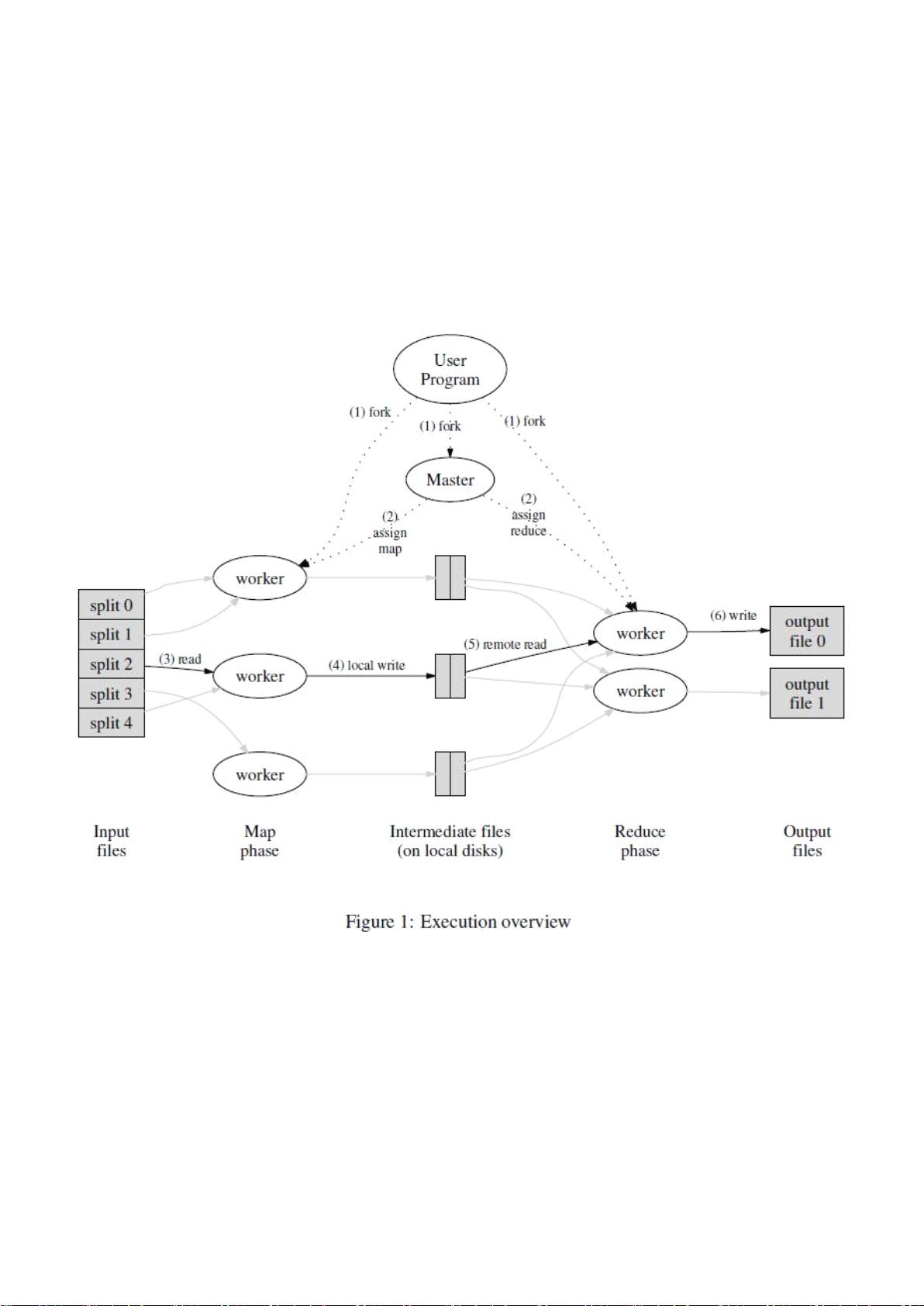
图 1 展示了我们的 MapReduce 实现中操作的全部流程。当用户调用 MapReduce 函数时, 将发生下面的一系列动 作
(下面的序号和图 1 中的序号一一对应) :
1. 用户程序首先调用的 MapReduce 库将输入文件分成 M 个数据片度,每个数据片段的大小一般从 16MB 到
64MB( 可以通过可选的参数来控制每个数据片段的大小 ) 。 然后用户程序在机群中创建大量的程序副本。 ( alex
:
copi es
of
the program 还真难翻译)
2. 这些程序副本中的有一个特殊的程序 --master 。副本中其它的程序都是 worker 程序,由 master 分配任务。有 M
个 Map 任务和 R 个 Reduce 任务将被分配, master 将一个 Map 任务或 Reduce 任务分配给一个空闲的 worker 。
3. 被分配了 map 任务的 worker 程序读取相关的输入数据片段,从输入的数据片段中解析出 key/value pair ,然后把
key/value pair 传递给用户自定义的 Map 函数,由 Map 函数生成并输出的中间 key/value pair ,并缓存在内存中。
4. 缓存中的 key/value pair 通过分区函数分成 R 个区域,之后周期性的写入到本地磁盘上。缓存的 key/value pair 在
本地磁盘上的存储位置将被回传给 master ,由 master 负责把这些存储位置再传送给 Reduce worker 。
5. 当 Reduce worker 程序接收到 master 程序发来的数据存储位置信息后,使用 RPC 从 Map worker 所在主机的磁 盘
上读取这些缓存数据。当 Reduce worker 读取了所有的中间数据后,通过对 key 进行排序后使得具有相同 key 值的数 据
剩余13页未读,继续阅读
865 浏览量
231 浏览量
232 浏览量
422 浏览量
130 浏览量
196 浏览量
182 浏览量
162 浏览量
103 浏览量

q353025805
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- VC++多线程与网络编程实战:进程与线程,Winsock基础
- VC++对话框与标准控件详解:模式对话框与编程入门
- 深入理解MFC应用程序:框架与消息处理
- 深入理解VC++动态链接库(DLL):原理与实战
- 运用软件工程思想开发扫雷游戏
- Windows Server 2003服务器群集配置实战指南
- Ruby 技巧解析:面向 Rails 开发者
- Shell编程入门指南:从Cygwin到Bash命令
- Linux环境下的C++编程实践与库对比
- Protel99使用指南:从安装到原理图设计
- ActionScript 3 RIA 开发权威指南
- 提升全文检索速度的有序单词搜索树与索引文件压缩算法
- Visual C# 中创建系统热键的方法
- AT91SAM7A3 ARM处理器数据手册详解
- SAS宏基础教程:文本操作与变量控制
- 固件开发必备:如何高效阅读DataSheet
