C4.5决策树算法详解:机器学习中的核心工具
需积分: 10 152 浏览量
更新于2024-07-24
收藏 327KB PDF 举报
"这篇文档是关于机器学习中的C4.5决策树算法的介绍,涵盖了算法的基本描述、特征以及在不同场景的应用。"
C4.5算法是机器学习和数据挖掘领域中用于分类问题的一组算法,专注于监督学习。它通过对具有属性值的数据集进行学习,构建一个从属性值到类别的映射,以便对新的未知实例进行分类。在实际应用中,C4.5算法可以处理具有多个属性和互斥类别的实例集合。
1.1 引言
C4.5算法由Ross Quinlan开发,是对ID3算法的改进。ID3主要处理离散属性,而C4.5则扩展了这一功能,能够处理连续属性并有效地处理缺失值。
1.2 算法描述
C4.5通过信息增益或信息增益比来选择最佳划分属性,构建决策树。信息增益衡量的是一个属性对数据集纯度的改善程度,信息增益比则考虑了属性的熵,避免了偏向于选择具有更多值的属性。
1.3 C4.5特性
1.3.1 树修剪:C4.5通过后剪枝策略来防止过拟合,即当子树的训练数据纯度提升不明显时,将其替换为叶节点。
1.3.2 处理连续属性:C4.5通过创建基于属性值的分割点来处理连续属性,将它们转化为离散的划分。
1.3.3 处理缺失值:C4.5可以处理数据集中存在的缺失值,通过计算所有可能的分支条件下的信息增益,选择最佳路径。
1.3.4 诱导规则集:除了生成决策树,C4.5还能产生规则集,这些规则更易于理解和解释。
1.4 软件实现讨论
C4.5算法有多种软件实现,如Weka数据挖掘库,它们提供用户友好的界面和API,便于研究人员和开发者使用。
1.5 案例分析
1.5.1 高尔夫数据集:展示了C4.5如何处理多类别问题和连续属性。
1.5.2 大豆数据集:演示了C4.5在处理有缺失值的数据集上的性能。
1.6 高级主题
1.6.1 从二级存储挖掘:探讨如何在大型数据集上使用C4.5,可能需要高效的数据流处理和内存管理。
1.6.2 倾斜决策树:研究非垂直(斜)分割,提高决策树的表达能力。
1.6.3 特征选择:通过减少特征数量,提高模型的效率和可解释性。
1.6.4 集成方法:结合多个C4.5决策树,如随机森林,增强分类的准确性和鲁棒性。
1.6.5 分类规则:C4.5生成的不仅仅是树,还可以是易于理解的规则集合。
1.6.6 重新描述:通过转换或简化规则,提高决策树的解释性和简洁性。
1.7 练习与参考文献
章节末尾通常会包含练习题,帮助读者深入理解和应用C4.5算法,并提供相关参考资料进一步学习。
C4.5是一种强大的分类工具,其特点是能处理连续和缺失数据,通过修剪防止过拟合,并能生成易于理解和解释的决策树和规则集。在实际应用中,它常常被用于数据挖掘、预测模型构建等领域,通过不断优化和扩展,C4.5成为了机器学习中不可或缺的一部分。
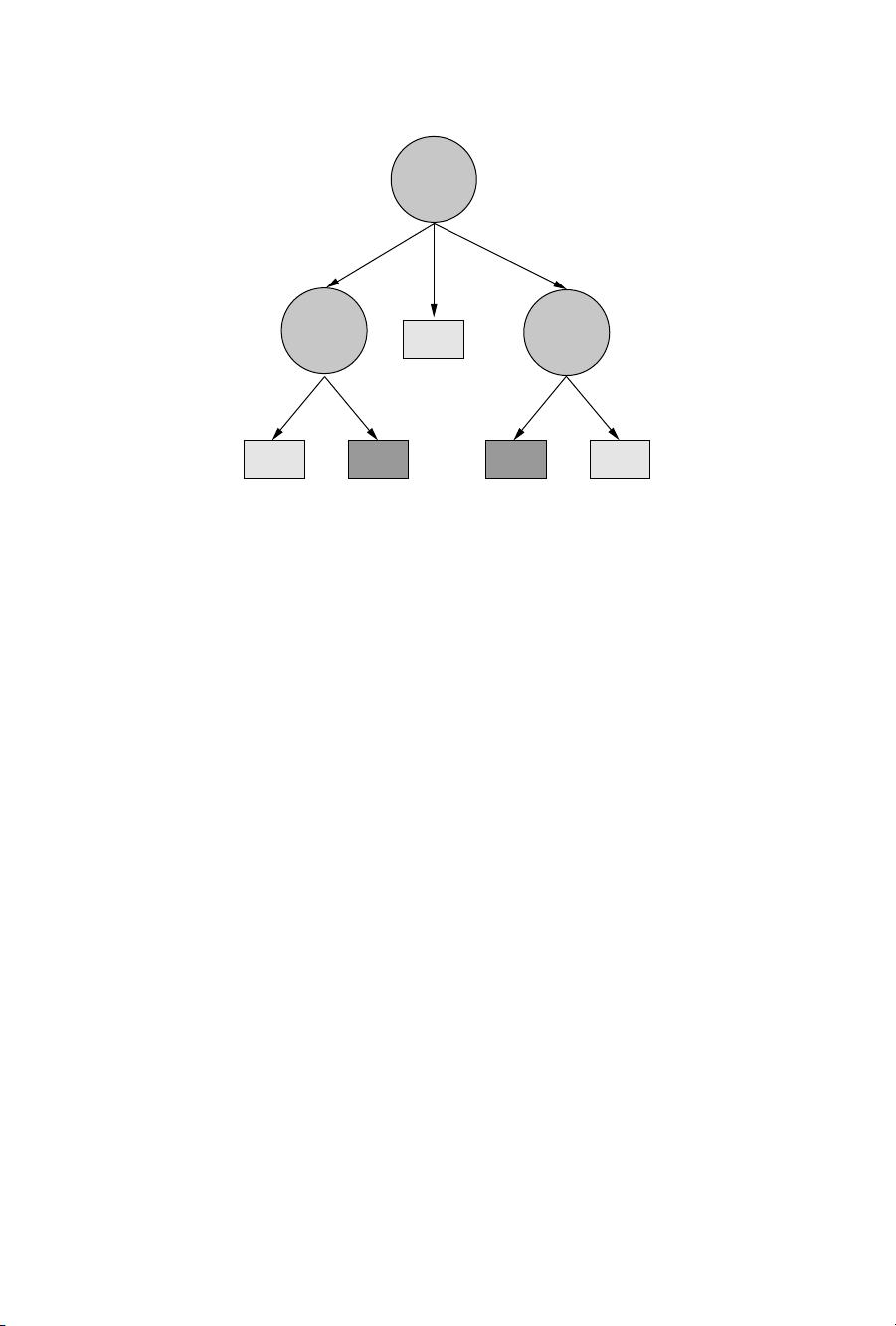
4 C4.5
Yes
Yes
Yes
No No
Outlook
Humidity
Windy
Sunny Rainy
Overcast
>75<=75 FalseTrue
Figure 1.2 Decision tree induced by C4.5 for the dataset of Figure 1.1.
Figure 1.1 presents the classical “golf” dataset, which is bundled with the C4.5
installation. As stated earlier, the goal is to predict whether the weather conditions
on a particular day are conducive to playing golf. Recall that some of the features are
continuous-valued while others are categorical.
Figure 1.2 illustrates the tree induced by C4.5 using Figure 1.1 as training data
(and the default options). Let us look at the various choices involved in inducing such
trees from the data.
r
What types of tests are possible? As Figure 1.2 shows, C4.5 is not restricted
to considering binary tests, and allows tests with two or more outcomes. If the
attribute is Boolean, the test induces two branches. If the attribute is categorical,
the test is multivalued, but different values can be grouped into a smaller set of
options with one class predicted for each option. If the attribute is numerical,
then the tests are again binary-valued, and of the form {≤ θ?,> θ?}, where θ
is a suitably determined threshold for that attribute.
r
How are tests chosen? C4.5 uses information-theoretic criteria such as gain
(reduction in entropy of the class distribution due to applying a test) and
gain ratio (a way to correct for the tendency of gain to favor tests with many
outcomes). The default criterion is gain ratio. At each point in the tree-growing,
the test with the best criteria is greedily chosen.
r
How are test thresholds chosen? As stated earlier, for Boolean and categorical
attributes, the test values are simply the different possible instantiations of that
attribute. For numerical attributes, the threshold is obtained by sorting on that
attribute and choosing the split between successive values that maximize the
criteria above. Fayyad and Irani [10] showed that not all successive values need
to be considered. For two successive values v
i
and v
i+1
of a continuous-valued
© 2009 by Taylor & Francis Group, LLC
剩余18页未读,继续阅读
2018-03-12 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

云在青天1
- 粉丝: 1
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建基于Django和Stripe的SaaS应用教程
- Symfony2框架打造的RESTful问答系统icare-server
- 蓝桥杯Python试题解析与答案题库
- Go语言实现NWA到WAV文件格式转换工具
- 基于Django的医患管理系统应用
- Jenkins工作流插件开发指南:支持Workflow Python模块
- Java红酒网站项目源码解析与系统开源介绍
- Underworld Exporter资产定义文件详解
- Java版Crash Bandicoot资源库:逆向工程与源码分享
- Spring Boot Starter 自动IP计数功能实现指南
- 我的世界牛顿物理学模组深入解析
- STM32单片机工程创建详解与模板应用
- GDG堪萨斯城代码实验室:离子与火力基地示例应用
- Android Capstone项目:实现Potlatch服务器与OAuth2.0认证
- Cbit类:简化计算封装与异步任务处理
- Java8兼容的FullContact API Java客户端库介绍
