讲解Transformer背景知识及原理的ppt
需积分: 50 97 浏览量
更新于2023-12-14
1
收藏 1.66MB PPTX 举报
Transformer是一种用于解决序列到序列问题的模型,如文本摘要、文本翻译和问答系统。它由Encoder和Decoder两部分组成,Encoder用于将输入数据转换为语义编码c,而Decoder则利用这个编码生成输出数据。
在Encoder中,输入数据[x1,x2,x3,x4...]经过深度学习器(如RNN/LSTM/GRU)的处理,产生隐藏层数据[h1,h2,h3,h4],最终生成语义编码c。例如,通过一个拥有4个隐藏层的RNN学习器,输入数据 <x1,x2,x3,x4...>经过学习后,生成的隐藏层数据为 <h1,h2,h3,h4>。
在Decoder中,语义编码c被用于生成输出数据。通过将c作为输入,Decoder使用相同的深度学习器来逐步生成输出序列。输出序列的每一步都是根据前一步的输出和隐藏层状态生成的,直至生成完整的序列。
Transformer模型的设计与传统的Encoder-Decoder模型有很大不同。它引入了Self-Attention机制,允许模型在生成输出时同时考虑输入序列中的不同元素之间的关系。这种机制使得模型能够更好地捕捉序列中的长程依赖关系,从而提高了模型的表现和性能。
在Transformer中,Self-Attention机制通过计算注意力权重来确定输入序列中每个元素对于生成输出的贡献。这样,每个输出位置都可以获取所有输入位置的信息,提供了更全局的上下文。
除此之外,Transformer还引入了多头注意力机制,即将Self-Attention机制应用多次,并将每个注意力头的输出进行线性组合,以获得更好的表征能力和泛化能力。
Transformer的模型设计还包括位置编码和残差连接。位置编码用于解决序列中元素的位置信息丢失问题,通过添加一定的编码向量来将元素位置信息融入模型。残差连接则能够更好地传递梯度信息,避免训练过程中的梯度消失或爆炸问题。
为了评估Transformer模型的性能,常用的指标有BLEU和ROUGE等。BLEU用于评估生成文本与参考答案的相似度,ROUGE则用于评估生成文本与参考摘要之间的相似度。
综上所述,Transformer是一种基于Encoder-Decoder模型的序列到序列问题解决方法,通过引入Self-Attention机制和其他设计优化,能够更好地处理序列数据,提高模型的表现和性能。其在自然语言处理领域具有广泛的应用前景。参考资料中的博客和论文提供了更详细的内容,可供进一步了解。
Background
2. Attention
2. Attention
Attention 模型在产生输出的时候,会产生一个“注意力范围”表
示接下来输出的时候要重点关注输入序列中的哪些部分,然后根
据关注的区域来产生下一个输出,如此往复 .
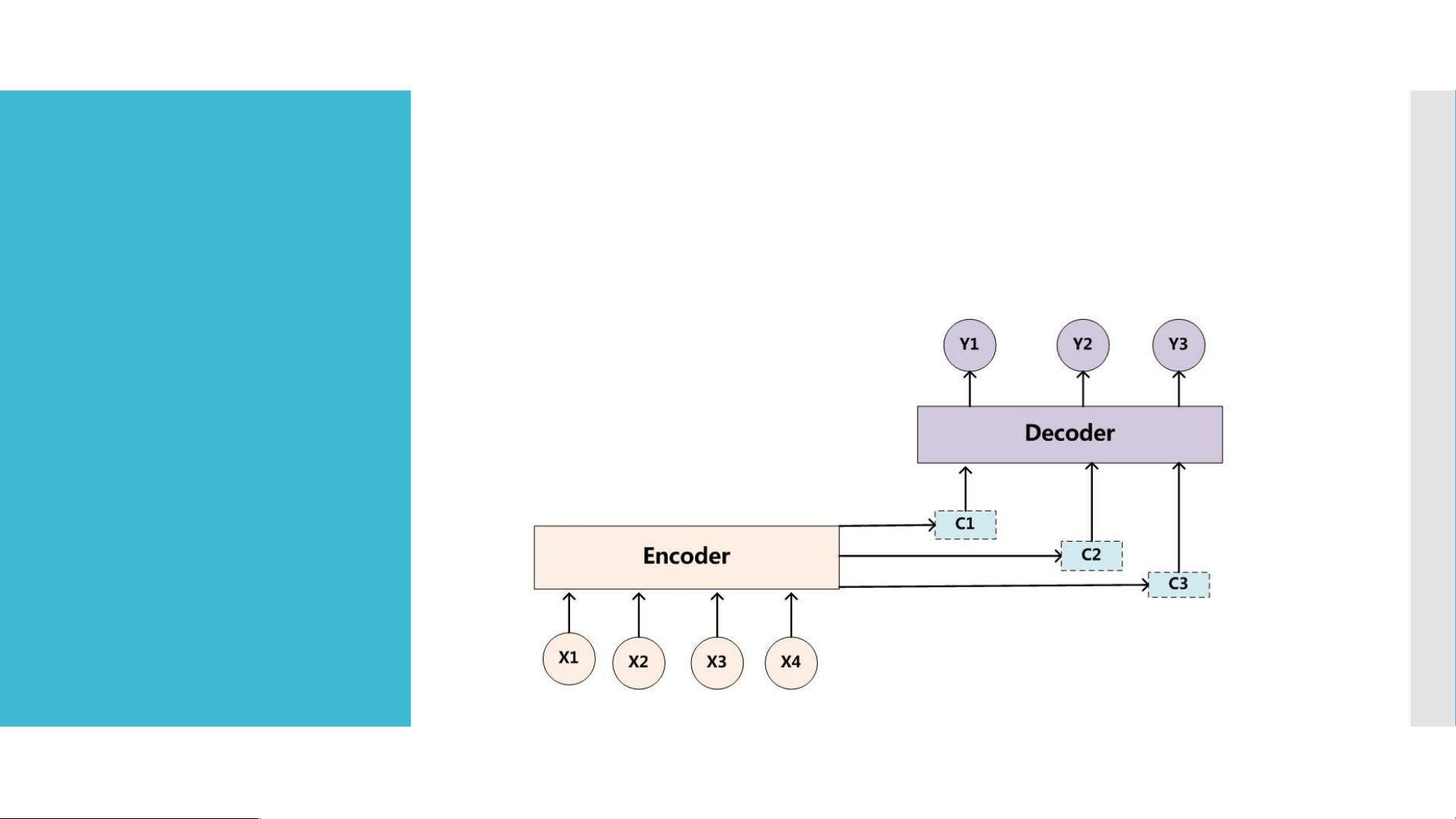
Attention 将 Encoder 的语义编码 C 变为子集
{c1 , c2 , c3}

剩余25页未读,继续阅读
2023-06-15 上传
2022-12-21 上传
2022-09-20 上传
103 浏览量
2009-09-23 上传
2024-06-18 上传
2023-12-09 上传
2023-05-31 上传

OneQ666
- 粉丝: 18
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- -ImportExcelOnec
- learning-web-technologies-spring-2020-2021-sec-h
- msgpack-rpc-jersey-blank:使用Jetty + Jersey + Jackson + MessagePack的现代Java RPC堆栈
- QQ自动点赞源码-易语言
- Simu5G:Simu5G-用于OMNeT ++和INET的5G NR和LTELTE-A用户平面仿真模型
- rust_template::crab:Rust项目模板。 只需运行init.py
- mvuehr:微人事前端
- SRC:HAB沙箱
- babylon:Web应用程序允许语言变量的国际化
- grunt-less-branding:根据品牌处理 LESS 文件
- neo_spacecargo:示例双向遍历扩展
- Frotend_Facturacion
- jsonotron:一个用于管理基于JSON模式的类型系统的库
- angular-task-1:Angular第一项任务:库存管理应用
- sclc:狮子座的约会约会系统
- NUCLEO-H745 CUBEIDE tcp通讯
