深度解析:Java实现一致性Hash算法
需积分: 0 58 浏览量
更新于2024-08-05
收藏 624KB PDF 举报
"对一致性Hash算法的深入研究,包括Java代码实现"
一致性Hash算法是一种分布式缓存和负载均衡的解决方案,它的主要目标是在增加或减少服务器节点时,尽可能少地改变已有的数据到服务器的映射关系,从而提高系统的伸缩性和稳定性。在传统的模运算Hash算法中,增减节点会导致大量映射关系变动,而一致性Hash算法通过在虚拟的Hash空间中构建一个环形结构来避免这个问题。
算法的核心思想是:首先创建一个虚拟的Hash环,该环的大小为2^32,每个服务器节点根据其名称计算出的Hash值被放置在这个环上。数据Key的Hash值也会位于同一环中,查找服务器时,从Key的Hash值开始顺时针找到最近的服务器节点作为映射目标。这样,即使有新的节点加入或移除,大部分原有的映射关系保持不变。
在Java中实现一致性Hash算法,需要考虑的关键点包括数据结构的选择和查找最近节点的方法。数据结构的选择至关重要,因为它直接影响到算法的效率。在描述中提到了两种可能的方案:
1. **排序+List**:首先计算所有服务器节点的Hash值并放入数组,然后排序,最后将排序后的结果放入List。查询时,可以使用二分查找法在List中找到第一个大于Key Hash值的服务器节点,时间复杂度为O(logn)。List的使用考虑到动态扩展的需求,但排序会增加额外的时间开销。
2. **遍历+List**:另一种方法是不进行排序,而是使用双向链表或者跳表等数据结构,可以直接插入节点,查询时从Key的Hash值开始顺时针遍历,直到找到最近的节点。这种方法不需要排序,但查找可能相对较慢,时间复杂度为O(n)。
在实际应用中,还可以考虑使用更高效的数据结构,如平衡树(如红黑树)或自平衡B树(如AVL树),它们可以保证在O(logn)的时间复杂度内完成插入和查找操作,同时提供较好的扩展性。此外,为了减少由于节点数量较少导致的负载不均,通常会引入虚拟节点的概念,即一个物理节点在环上对应多个虚拟节点,进一步提高分布的均匀性。
一致性Hash算法通过特殊的环形结构和高效的查找机制,解决了分布式系统中节点变动时映射关系的稳定性问题。在Java中实现时,选择合适的数据结构和查找策略是优化性能的关键。通过不断的优化和调整,可以实现高效且具有良好伸缩性的一致性Hash算法。
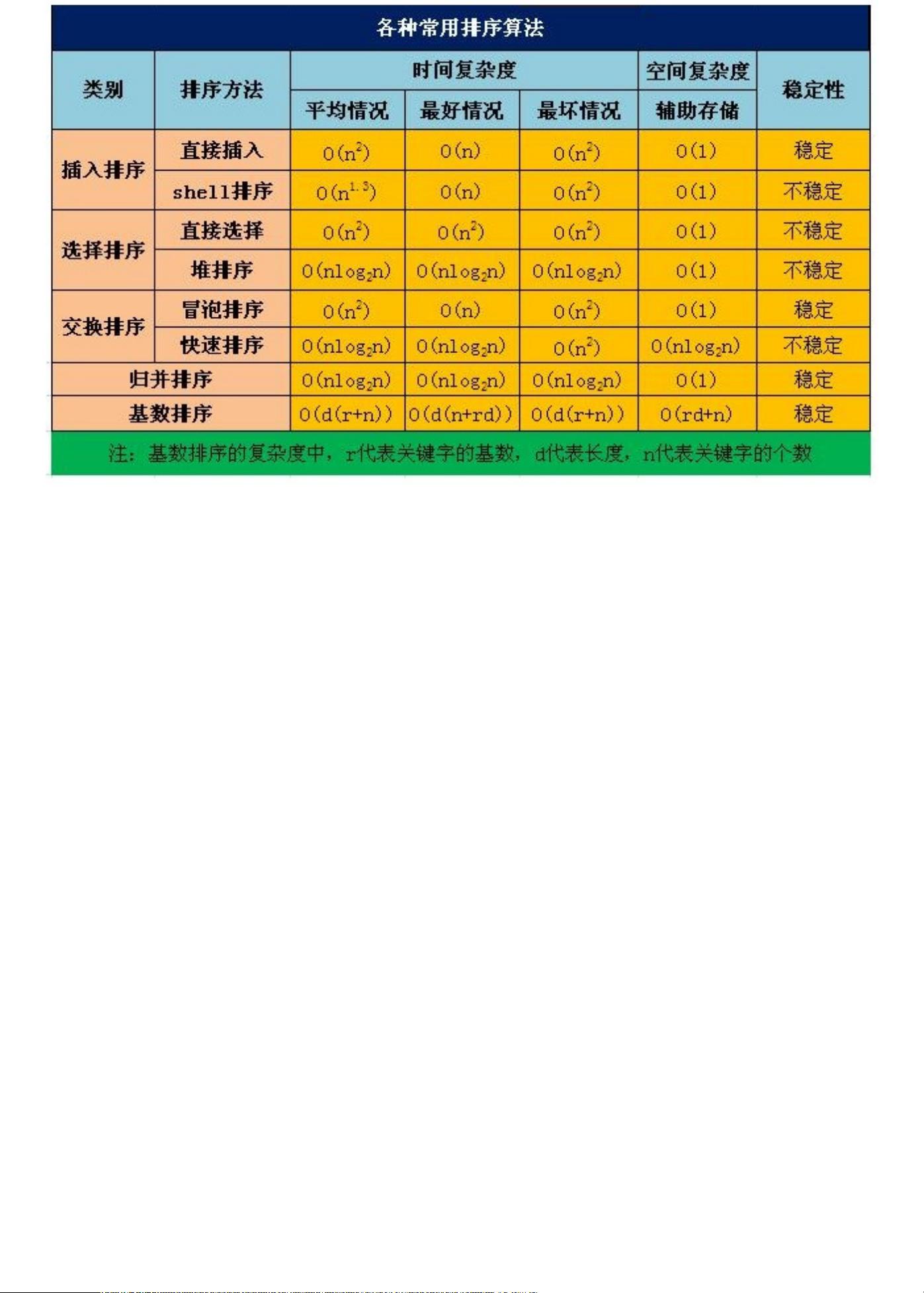
看得出来,排序算法要么稳定但是时间复杂度⾼、要么时间复杂度低但不稳
定,看起来最好的归并排序法的时间复杂度仍然有O(N * logN),稍微耗费性
能了⼀些。
2、解决⽅案⼆:遍历+List
既然排序操作⽐较耗性能,那么能不能不排序?可以的,所以进⼀步的,有
了第⼆种解决⽅案。
解决⽅案使⽤List不变,不过可以采⽤遍历的⽅式:
(1)服务器节点不排序,其Hash值全部直接放⼊⼀个List中
(2)带路由的节点,算出其Hash值,由于指明了"顺时针",因此遍历List,
⽐待路由的节点Hash值⼤的算出差值并记录,⽐待路由节点Hash值⼩的忽
略
(3)算出所有的差值之后,最⼩的那个,就是最终需要路由过去的节点
在这个算法中,看⼀下时间复杂度:
1、最好情况是只有⼀个服务器节点的Hash值⼤于带路由结点的Hash值,其
时间复杂度是O(N)+O(1)=O(N+1),忽略常数项,即O(N)
剩余12页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-06-23 上传
2012-09-11 上传
2021-05-24 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

番皂泡
- 粉丝: 26
- 资源: 320
 我的内容管理
展开
我的内容管理
展开







最新资源
- ability:Java的简单授权库
- drops:Soundworks 框架的示例应用程序(受 Brian Eno 的 Bloom 应用程序启发的集体表演)
- java-binary-tree:二叉搜索树的简单实现
- Python库 | dnsdiag-1.6.3.tar.gz
- grammar-web:上下文无关语法的在线辅导系统
- PHP实例开发源码—智伍Discuz应用中心.zip
- 行业资料-电子功用-光通信系统中上行高速数据的同步接收方法与电路的介绍分析.rar
- 基于Kotlin实现的记事本App.zip
- Lithium-SRC:Lithium客户端源代码。 被我泄漏
- KopDB:简单,好用的 DB 框架
- 大雪纷飞flash动画
- 【WordPress插件】2022年最新版完整功能demo+插件.zip
- HelloWorld:我的世界收藏库
- wui:Web的GUI小部件的集合
- 行业资料-电子功用-光纤电流互感器用镜像对称真随机四态调制解调方法的介绍分析.rar
- PHP实例开发源码—站长爱好者 PHP 留言本.zip
