




梯度下降算法解析及其应用
需积分: 50 121 浏览量
更新于2024-07-15
1
收藏 3.8MB PPTX 举报
"梯度下降算法.pptx"
梯度下降是一种优化算法,广泛应用于机器学习领域,特别是解决无约束优化问题。它通过迭代的方式寻找损失函数的最小值,是求解模型参数的主要方法之一。从优化算法的发展历史来看,梯度下降在机器学习中的地位至关重要,因为它能有效地处理复杂的多维函数。
在数学上,对于一维的凸函数,我们可以直接通过求导数并令其等于零来找到最小值。对于非凸函数,可能有多个极值点,需要计算每个极值点处的函数值来确定最小值。在高维空间,即多元函数的情况下,我们不仅需要求偏导数,还可能需要考虑海森矩阵来避免鞍点和极大值点。然而,计算机无法直接一次性求出答案,这就需要用到迭代算法。
迭代算法的核心在于重复执行一组指令,每次迭代更新变量的值。梯度下降作为迭代算法的一种,根据当前位置的梯度负方向移动,模拟下山的过程。每一步都向着损失函数下降最快的方向前进。这种直观的解释揭示了梯度下降可能陷入局部最优解,而非全局最优解。如果损失函数是凸的,那么梯度下降法将保证找到全局最优解。
梯度下降有多种变体,包括批量梯度下降(Batch Gradient Descent),其中每次迭代都使用所有数据样本;随机梯度下降(Stochastic Gradient Descent),每次迭代只用一个样本;以及小批量梯度下降(Mini-Batch Gradient Descent),每次迭代用一小部分样本。这些变体在实际应用中各有优势,例如,随机梯度下降在大数据集上计算效率更高,但可能引入更多噪声。
在机器学习模型训练中,如逻辑回归、支持向量机、神经网络等,梯度下降被用来优化模型的权重或参数。通过反向传播计算损失函数关于参数的梯度,然后更新参数以减小损失。此外,为了加速收敛,还可以调整学习率(Learning Rate)或者采用优化器,如动量(Momentum)、自适应学习率算法(如Adagrad、RMSprop、Adam等)。
梯度下降是机器学习中不可或缺的工具,它在理论和实践上都有着深远的影响。理解并掌握梯度下降及其变体,对于理解和构建有效的机器学习模型至关重要。
添加主题
文字描述,总结概
括,内容大纲。
添加主题
问题引入
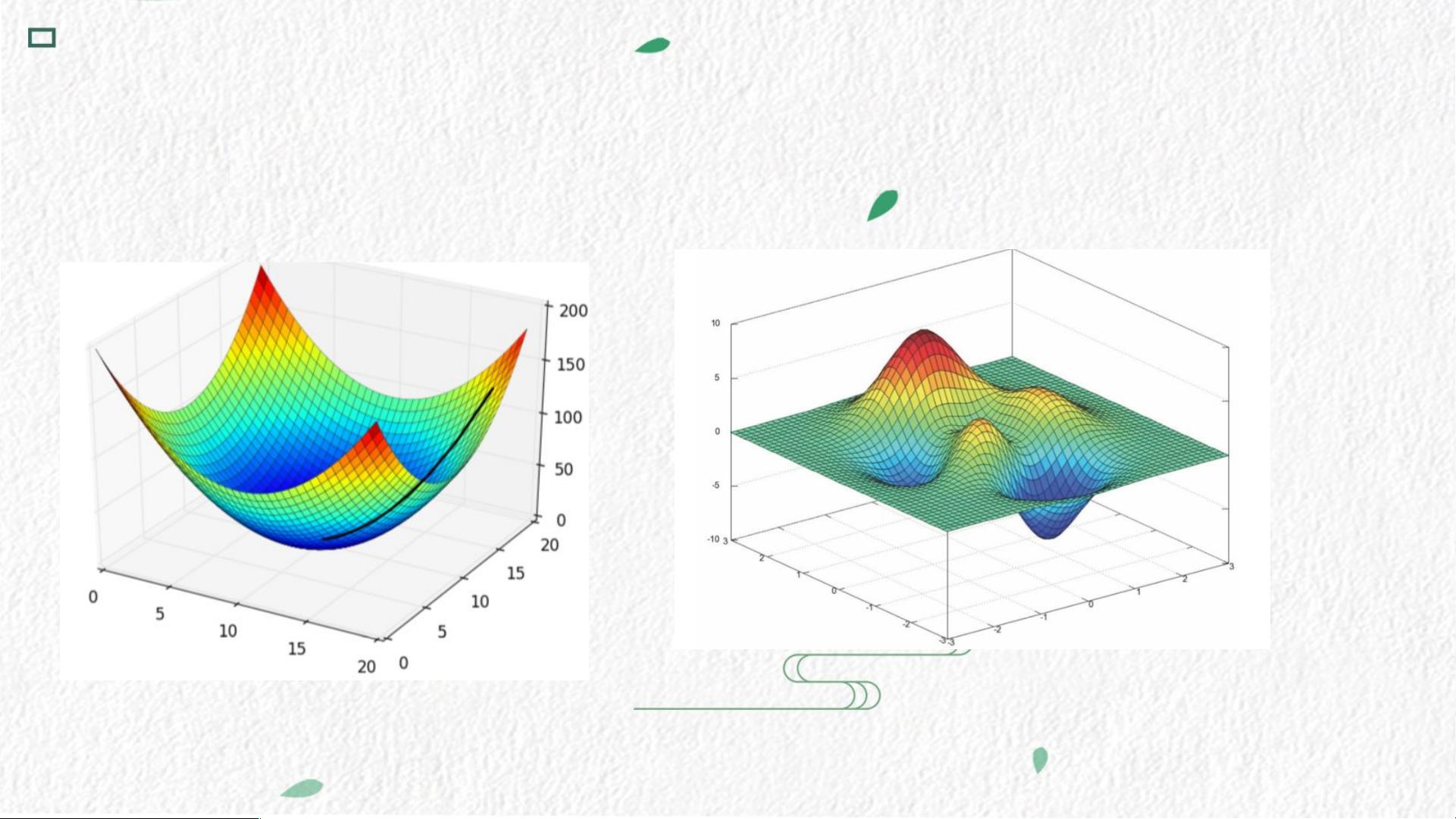
上面两个栗子都是一维的情况,那么高维空间呢?
下面是二维空间里凸函数与非凸函数的两个栗子
多元函数就涉及到求偏导数,非凸的问题还要进一步求海森矩阵过滤掉鞍
点和极大值点
下载后可阅读完整内容,剩余20页未读,立即下载
778 浏览量
1035 浏览量
758 浏览量
613 浏览量
789 浏览量
2024-10-30 上传
507 浏览量

房默笙
- 粉丝: 42
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- ORA-12154:TNS:无法解析指定的连接标识符
- 拟物化暗黑财务记账应用界面sketch素材_figma素材_xd素材.zip
- 适合女生使用清新彩条PPT模板.rar
- 易语言源码易语言核心分割源码.rar
- nouyeng_v26.zip_matlab例程_matlab_
- volatility-forecasting
- 打印机驱动 LaserJet_CP2025
- 喜羊羊与灰太狼PPT模板.rar
- 如何将IP转换为URL NAME(主机名)
- jfdz5-barbarossa-app
- puiniu.zip_模式识别(视觉/语音等)_matlab_
- API取窗口信息例程.rar
- 航空公司工作总结汇报PPT模板.rar
- 打印机驱动 HP LaserJet M1213nf
- jlang-toolkit
- 某广播电影电视集团招标文件书





















