谷歌新策略Mixture-of-Denoisers:统一NLP范式,挑战GPT3
版权申诉
137 浏览量
更新于2024-08-04
收藏 2.31MB PDF 举报
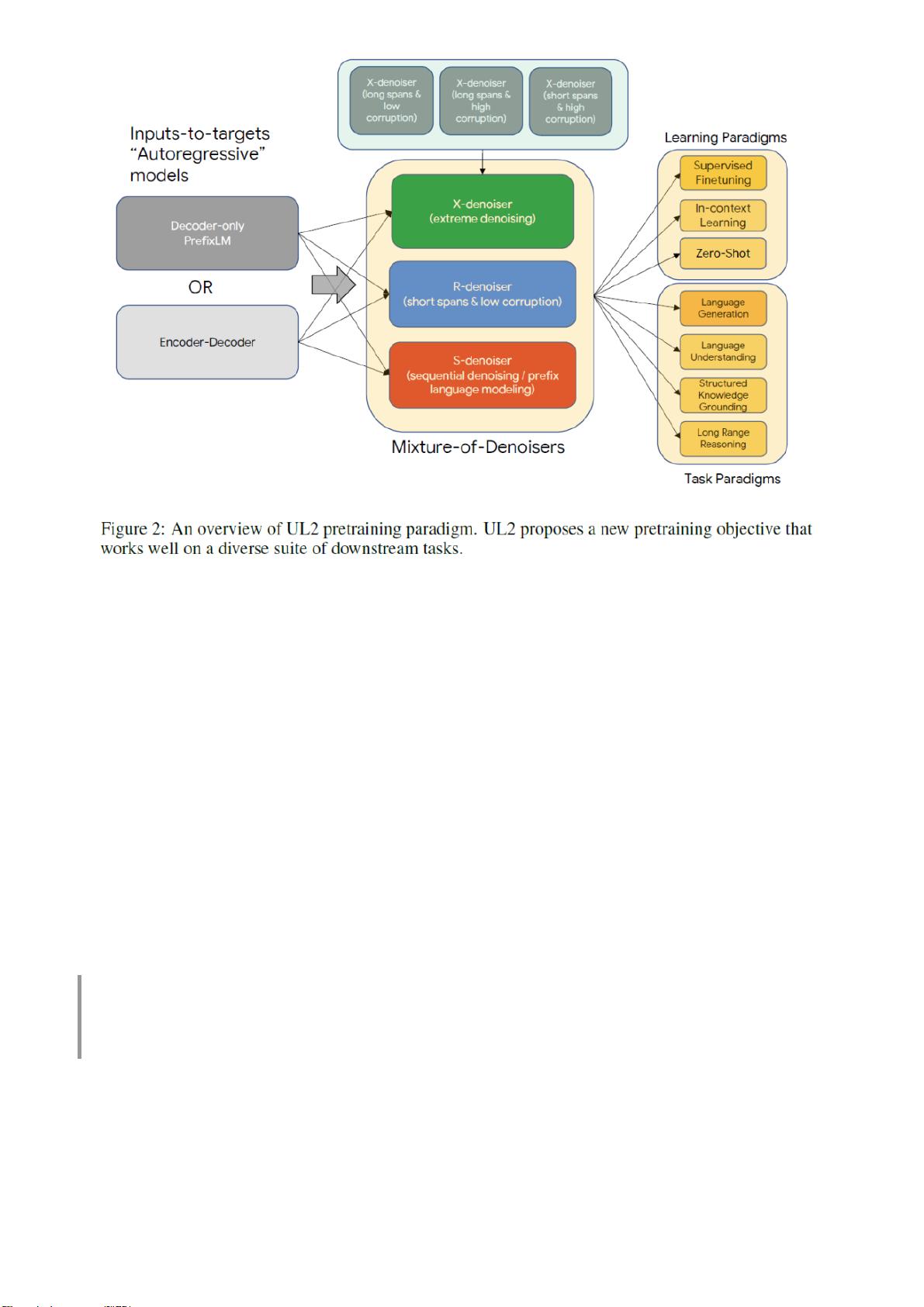
"谷歌团队提出的新策略Mixture-of-Denoisers在自然语言处理(NLP)领域取得了重大突破,成功击败了GPT-3,并在50个不同的State-of-the-Art(SOTA)任务中刷新了记录。这一创新方法旨在统一现有的多种NLP预训练范式,整合了包括decoder-only、encoder-decoder、span corruption和language model在内的不同模型,以适应各种类型的下游任务。通常,预训练模型分为三类:单向的CausalLM(如GPT)、双向的span corruption(如T5)和前缀文本建模的PrefixLM。Mixture-of-Denoisers通过混合不同的去噪器策略,实现了对各种上下文关系的有效建模,从而提升了模型的泛化能力和性能。"
在当前的NLP研究中,预训练模型已经成为了核心,而预训练和微调的不同范式则各自有着独特的优点和适用场景。Google的研究团队针对这一现状,提出了Mixture-of-Denoisers的框架,该框架通过混合多种去噪策略,使得模型能够同时利用不同类型的上下文信息,增强模型的适应性和性能。这一创新可能意味着NLP领域的一个重要转折点,因为之前的各种预训练范式通常是独立的,而Mixture-of-Denoisers提供了更加灵活且全面的方法。
Mixture-of-Denoisers的核心思想是结合了不同的预训练任务,比如解码器仅依赖左 context 的CausalLM任务,编码器-解码器架构的span corruption任务,以及只看前缀的PrefixLM任务。通过混合这些任务,模型可以学习到更广泛的语言理解模式,从而在多种任务中表现出色。据报告所示,这一新策略在50个不同的NLP任务上超越了GPT-3,证明了其强大的泛化能力和效率。
这一进步不仅对于提高NLP模型的性能具有重要意义,而且可能为未来的模型设计提供新的方向。研究人员和开发者现在可以利用Mixture-of-Denoisers来构建更强大的预训练模型,这些模型能够更好地处理各种复杂的语言任务,包括但不限于问答系统、机器翻译、文本生成、情感分析和语义理解等。
Mixture-of-Denoisers展示了在NLP领域统一预训练范式的可能性,有望推动模型设计的标准化和效率提升,进一步加速AI技术的发展。随着这一技术的深入研究和应用,我们有望见证NLP模型在理解人类语言方面取得更大的进步。
2023/6/28 22:31
击败GPT3,刷新50个SOTA!谷歌全面统一NLP范式
https://mp.weixin.qq.com/s/oMUASBSKe3xgGVLuQz7MGg
3/14
瞬间清醒!
Go ogle 的 Yi Tay (and Mostafa) 团队提 出了 一个 新的 策略 Mixture-of-Denoisers, 统一 了
各大预 训 练 范 式 。
重新思考现在的预训练精调,我们有各种各样的预训练范式: decoder-only or encoder-d
ecoder , span corruption or language model , 等等, 不同的范式建模了不同的上下文
关系,也正是因为如此,不 同 的 预 训 练 范 式 适 配 不 同 类 型 的 下 游 任 务 。例如,基于双向上下
文 的 预 训 练 (span corruption , 如 T5) 更 加 适 用 于 fact completion , 基 于 单 向 上 文
(P refixLM/LM,如GPT等)更加适用于 open ended. 也就是说,具 体 的 下 游 任 务 类 型 需 要 选
用 特 定 的 预 训 练 策 略 ...
准确地说,常见有三套范式:单向文本建模的CausalLM(i.e. LM),双向文本建模的 span
corruption, 前缀文本建模的 PrefixLM.
这是大一统吗?感觉只能是小一统,总感觉还缺少一味菜!
今天,Google 把这道菜补上了!那就是:Mixture-of-Denoisers
先来感受一下效果:
剩余13页未读,继续阅读
2023-10-18 上传
2023-05-18 上传
2023-05-27 上传
2024-03-07 上传
2023-09-16 上传
2023-05-13 上传
2023-03-29 上传
2023-06-15 上传
2023-05-11 上传

地理探险家
- 粉丝: 1236
- 资源: 5535
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握数学建模:层次分析法详细案例解析
- JSP项目实战:广告分类系统v2.0完整教程
- 如何在没有蓝牙的PC上启用并使用手机蓝牙
- SpringBoot与微信小程序打造游戏助手完整教程
- 高效管理短期借款的Excel明细表模板
- 兄弟1608/1618/1619系列复印机维修手册
- 深度学习模型Sora开源,革新随机噪声处理
- 控制率算法实现案例集:LQR、H无穷与神经网络.zip
- Java开发的HTML浏览器源码发布
- Android闹钟程序源码分析与实践指南
- H3C S12500R升级指南:兼容性、空间及版本过渡注意事项
- Android仿微信导航页开门效果实现教程
- 深度研究文本相似度:BERT、SentenceBERT、SimCSE模型分析
- Java开发的zip压缩包查看程序源码解析
- H3C S12500S系列升级指南及注意事项
- 全球海陆掩膜数据解析与应用
