图像文本识别进展:技术挑战与模型综述
需积分: 9 67 浏览量
更新于2024-07-18
1
收藏 2.88MB PDF 举报
自然场景文本检测识别技术综述
自然场景文本检测识别(NSTR)是一项关键的计算机视觉任务,它涉及在未经过优化的图像中准确识别和定位各种复杂形式的文本。OCR技术的传统应用主要集中在扫描文档上的文字识别,但NSTR的挑战在于处理自然场景中的多样化因素,如多语言混杂、变形文字、光照变化、纹理干扰等。
在技术挑战方面,NSTR需要解决的对象包括倾斜、艺术字、不规则形状、低对比度和模糊的文字,以及复杂的背景环境。这些因素使得模型必须具备高度的鲁棒性和适应性,能够识别不同尺寸、字体和颜色的文本,同时在各种光照条件下保持准确性。
文章首先介绍了应用背景,强调了NSTR与传统OCR的区别,后者更侧重于结构化文档,而NSTR则需要处理更广泛的场景和不确定性。应用领域广泛,包括但不限于自动驾驶、安防监控、搜索引擎优化和社交媒体分析等,其中,图像中的产品标签、广告文字、地图路标等都是常见的应用场景。
在模型构建过程中,常用的特征提取基础网络如VGG16(在CTPN中被选中)、ResNet、FCN和Densenet等都扮演着关键角色。这些网络通过深度学习的方式提取图像特征,但选择哪个网络取决于模型的性能需求和计算资源。每个网络都有其优缺点,需要根据具体任务调整以适应不同的场景和复杂度。
文本边框检测模型的发展是NSTR的一个重要分支,如CTPN、 EAST(Efficient and Accurate Scene Text Detector)等,它们旨在精确定位文本区域。而文字内容识别模型则是关注于识别已检测到的文本区域内的字符序列,这通常结合了深度神经网络如LSTM(长短期记忆网络)或Transformer来提高识别精度。
近年来,端到端的图文识别模型逐渐兴起,如MTCNN(Multi-task Cascaded Convolutional Networks)与CRNN(Convolutional Recurrent Neural Network)的结合,这种模型直接将文本检测和识别任务整合在一起,显著提升了整体性能。
最后,文中提到了几个重要的大型公开数据集,如ICDAR(International Conference on Document Analysis and Recognition)系列比赛的数据集,它们对于训练和评估NSTR模型至关重要,提供了丰富的实际场景样本供研究人员进行模型训练和性能比较。
总结来说,自然场景文本检测识别技术是一个快速发展的领域,不断涌现的新模型和算法旨在应对复杂环境中的文本识别挑战,而随着深度学习和大数据的支持,未来的NSTR技术有望实现更高的准确性和实用性。
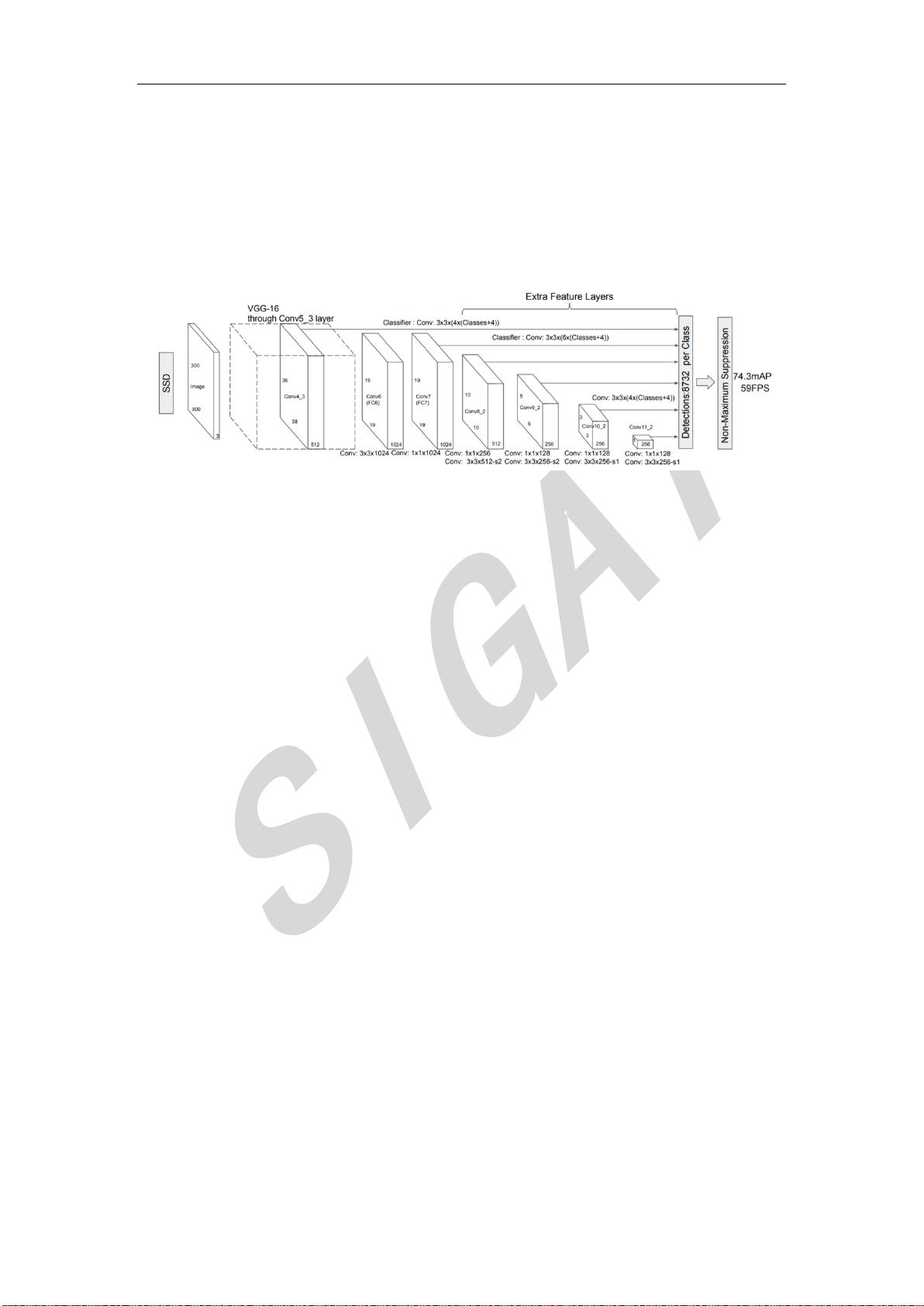
止到目前仍是主要的目标检测框架之一,相比 Faster RCNN 有着明显的速度优势。如下图所
示,SSD 是一种 one stage 算法,直接预测被检测对象的边框和得分。检测过程中,SSD 算
法利用多尺度思想进行检测,在不同尺度的特征图(feature maps)上产生与目标物体长宽比例
接近的多个默认框(Default boxes),进行回归与分类。最后利用非极大值抑制(Non-maximum
suppression)得到最终的检测结果。训练过程中,SSD 采用 Hard negative mining 策略进行训
练,使正负样本比例保持为 1:3,同时使用多种数据增广(Data augmentation)方式进行训练,
提高模型性能。
(摘自 arxiv: 1512.02325, “SSD: Single Shot MultiBox Detector”)
3. 文本检测模型
文本检测模型的目标是从图片中尽可能准确地找出文字所在区域。
但是,视觉领域常规物体检测方法(SSD, YOLO, Faster-RCNN 等)直接套用于文字检测
任务效果并不理想, 主要原因如下:
相比于常规物体,文字行长度、长宽比例变化范围很大。
文本行是有方向性的。常规物体边框 BBox 的四元组描述方式信息量不充足。
自然场景中某些物体局部图像与字母形状相似,如果不参考图像全局信息将有误报。
有些艺术字体使用了弯曲的文本行,而手写字体变化模式也很多。
由于丰富的背景图像干扰,手工设计特征在自然场景文本识别任务中不够鲁棒。
针对上述问题根因,近年来出现了各种基于深度学习的技术解决方案。它们从特征提取、
区域建议网络(RPN)、多目标协同训练、Loss 改进、非极大值抑制(NMS)、半监督学习等角
度对常规物体检测方法进行改造,极大提升了自然场景图像中文本检测的准确率。例如:
CTPN 方案中,用 BLSTM 模块提取字符所在图像上下文特征,以提高文本块识别精度。
RRPN 等方案中,文本框标注采用 BBOX +方向角度值的形式,模型中产生出可旋转的
文字区域候选框,并在边框回归计算过程中找到待测文本行的倾斜角度。
DMPNet 等方案中,使用四边形(非矩形)标注文本框,来更紧凑的包围文本区域。
SegLink 将单词切割为更易检测的小文字块,再预测邻近连接将小文字块连成词。
TextBoxes 等方案中,调整了文字区域参考框的长宽比例,并将特征层卷积核调整
为长方形,从而更适合检测出细长型的文本行。
FTSN 方案中,作者使用 Mask-NMS 代替传统 BBOX 的 NMS 算法来过滤候选框。
WordSup 方案中,采用半监督学习策略,用单词级标注数据来训练字符级文本检测
模型。
下面用近年来出现的多个模型案例,介绍如何应用上述各方法提升图像文本检测的效果。
3.1 CTPN 模型
CTPN 是目前流传最广、影响最大的开源文本检测模型,可以检测水平或微斜的文本行。
文本行可以被看成一个字符 sequence,而不是一般物体检测中单个独立的目标。同一文本
剩余20页未读,继续阅读
2990 浏览量
834 浏览量
233 浏览量
140 浏览量
256 浏览量
146 浏览量
2024-12-05 上传
194 浏览量

SIGAI_csdn
- 粉丝: 2353
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建纯PHP电子商务网上商店教程
- Unity实现动态天空:白天黑夜交替效果教程
- meteor-spin.js:打造流星效果的旋转动画库
- 王码86版打字软件深度评测
- 掌握ArcGIS Android SDK v2进行移动二次开发
- STM32与DS18B20温度传感数据在12864屏幕显示
- TypeScript与Vue.js的完美结合及静态类型获取方法
- 惠普hp laserjet pro mfp m128fn官方驱动下载
- 深入了解HTML基础之wdd330教程
- 无需登录的文件上传神器UploadNow
- 兼容IE9的simplehint CSS提示信息实现
- Android 4.3蓝牙4.0模块实战:三个demo应用整合
- SLF4J日志框架1.7.6版本详解
- 打造个性recyclerView动画组件
- InsydeFlash 6.20:笔记本BIOS更新的利器
- MELP语音编解码器源码分析:2400Kbps的语音处理
