华中科技大学机器学习讲义:监督学习与k近邻算法详解
需积分: 0 21 浏览量
更新于2024-07-01
收藏 2.9MB PDF 举报
本讲义是华中科技大学计算机科学与技术学院机器学习与数据挖掘实验室编撰的机器学习内部讲义,由何琨老师编纂,适用于本科生教学。讲义内容覆盖了机器学习的基础概念和关键算法,分为五章:
1. 引言部分介绍了机器学习的基本概念,包括其定义、历史以及主要的学习算法类型,如监督学习、无监督学习和强化学习。
2. 监督学习章节详细讨论了监督学习方法,包括标签空间和特征向量的概念,以及如何通过损失函数来衡量模型预测的准确性。举例说明了损失函数的作用,并强调了泛化能力在模型选择中的重要性。此外,还讲解了训练集和测试集的划分,以及数据划分的方法。
3. 第三章重点讲解了k近邻算法,涉及基本假设、分类规则、距离函数的选择,以及k值的影响。同时,讨论了维数灾难问题,即在高维空间中寻找最佳决策边界时的挑战。k-平均聚类算法也作为补充提及。
4. 感知机是第四章的核心内容,介绍了感知机分类模型的工作原理、感知机算法和其收敛性的探讨。
5. 贝叶斯方法与概率估计是后续章节的主题,涉及到联合概率分布、最大似然估计(MLE)和边际最大后验估计(MAP),这些都是构建基于概率模型的重要工具。
这门讲义不仅提供理论知识,还结合实例帮助理解,旨在为学生深入理解机器学习的核心思想和技术打下坚实基础。何琨老师鼓励读者对讲义提出改进意见,持续更新和完善内容。
何琨 @ 华中科技大学
R
d
是 d 维特征空间
x
i
是第 i 个样本的特征向量
y
i
是第 i 个样本的标签
c 是标签空间
数据点 (x
i
, y
i
)来源于一些分布 P(X, Y),我们想要学习函数 h,对于新的点 (x, y) ∼ P,
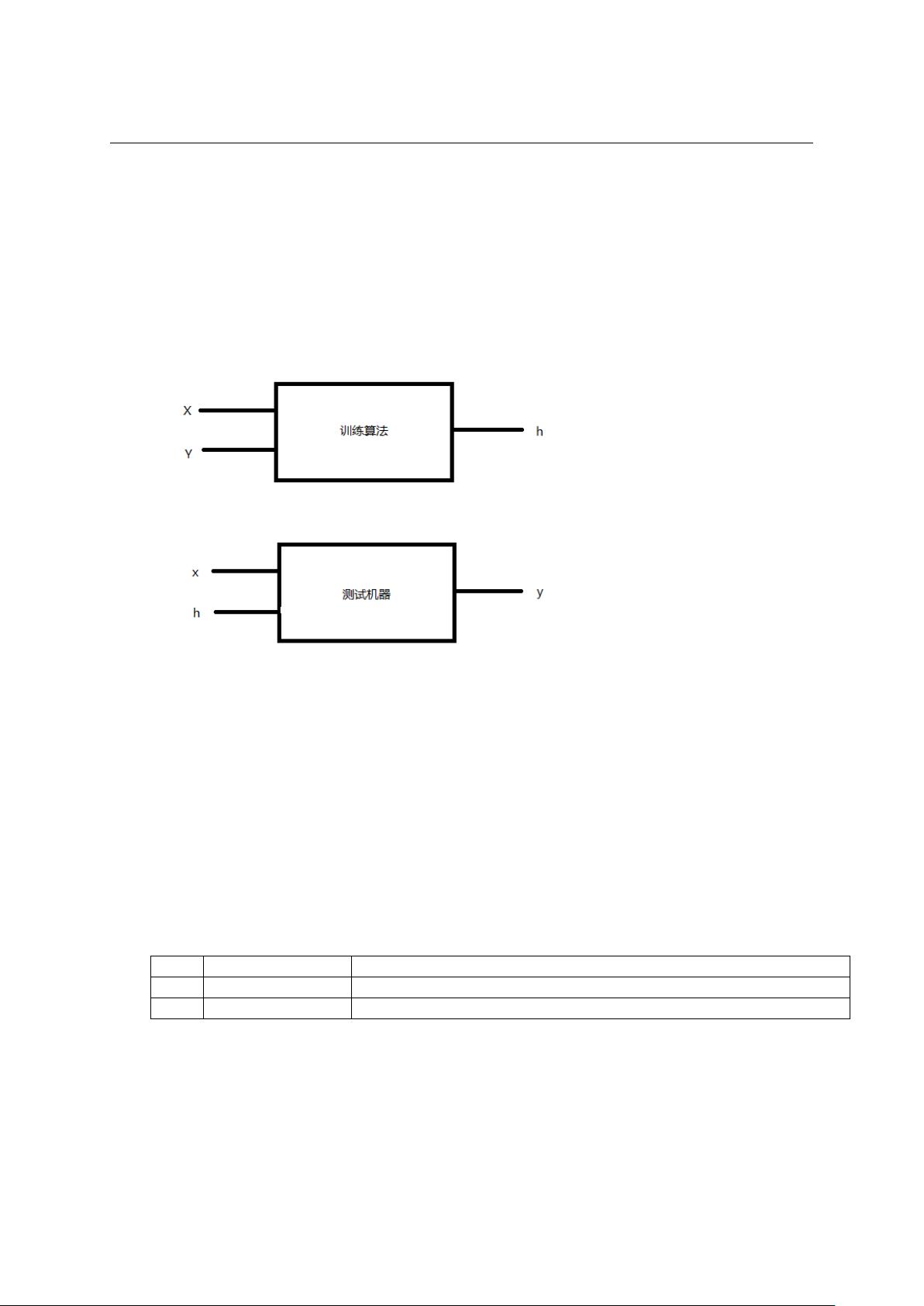
有较高的概率使得 h(x) = y 或者 h(x) ≈ y。监督学习的整体模型如下:
图 2–1 监督学习
Figure 2–1 supervised learning
其中函数 h 属于假想集 H,假想集包括多种函数,如线性分类函数、决策树、人工
神经网络、SVM 等等。一个成功的机器学习实例都是基于某个假设。
下面,对于 X 和 Y 举一些例子。
2.2.1 标签空间实例
对于标签空间 c 有以下几种情形:
二分类 c =
{
0, 1
}
orc =
{
−1, +1
}
如垃圾邮件过滤,一封邮件是垃圾邮件 (+1) 或者不是 (-1)
多分类 c =
{
0, 1, . . . , K
}(
K ≥ 2
)
如脸分类器,一个人可以是 K 身份中的一个 (例如,“1”表示奥巴马,“2”表示布什)
回归 c = R 如预测未来的温度和人的身高
2.2.2 特征向量实例
我们称 x
i
为特征向量,d 维中的每一维表示第 i 个样本的一个特征,以下为几个例
子。
6




剩余117页未读,继续阅读
2022-08-03 上传
2025-01-09 上传
2025-01-09 上传

张盛锋
- 粉丝: 31
- 资源: 297
 我的内容管理
展开
我的内容管理
展开







最新资源
- Stickman Hangman Game in JavaScript with Source Code.zip
- 饭准备的诺拉api
- gopacket:提供Go的封包处理能力
- theme-agnoster
- service_marketplace:Accolite大学项目一个以用户友好且可扩展的方式连接客户和服务提供商的平台
- ssm酒厂原料管理系统毕业设计程序
- backstitch:适用于您现有React UI的Web组件API
- AutoGreen
- Query Server TCL-开源
- MMG.rar_MMG
- Site Bookmark App using JavaScript Free Source Code.zip
- css-essentials-css-issue-bot-9000-nyc03-seng-ft-051120
- Xshell-Personal6.0.0204p.zip
- govim是用Go编写的Vim8的Go开发插件-Golang开发
- Ticker
- xcrczpky.zip_三维路径规划
