MySQL索引原理解析:数据结构与查询优化
版权申诉
148 浏览量
更新于2024-09-12
收藏 419KB PDF 举报
"本文主要探讨了MySQL索引的底层实现原理,强调了索引作为数据结构对于提升数据库查询效率的重要性。文章提到了基本的顺序查找算法的局限性,并介绍了二分查找和二叉树查找等更高效的算法。通过示例说明了如何利用索引来加速数据检索,特别提到了二叉查找树和二叉排序树的概念,以及它们在实际数据库系统中的应用局限性。"
在MySQL中,索引是关键的性能优化工具,它是一种特殊的数据结构,用于加速对数据库表中数据的访问。索引的本质在于它并不存储数据本身,而是存储数据的引用,这些引用指向数据的实际位置,使得数据库系统能够通过特定的数据结构来实现快速查找。官方定义索引为帮助MySQL高效获取数据的数据结构,这表明了其核心作用是优化查询性能。
在没有索引的情况下,查询数据通常依赖于顺序查找,这种方法在数据量大的情况下效率极低,因为它的复杂度是线性的,即O(n)。为了提高查询速度,数据库系统引入了更高级的查找算法,如二分查找和二叉树查找。然而,这些算法的效率依赖于特定的数据结构。例如,二分查找需要数据预先排序,而二叉树查找则要求数据组织成二叉查找树。
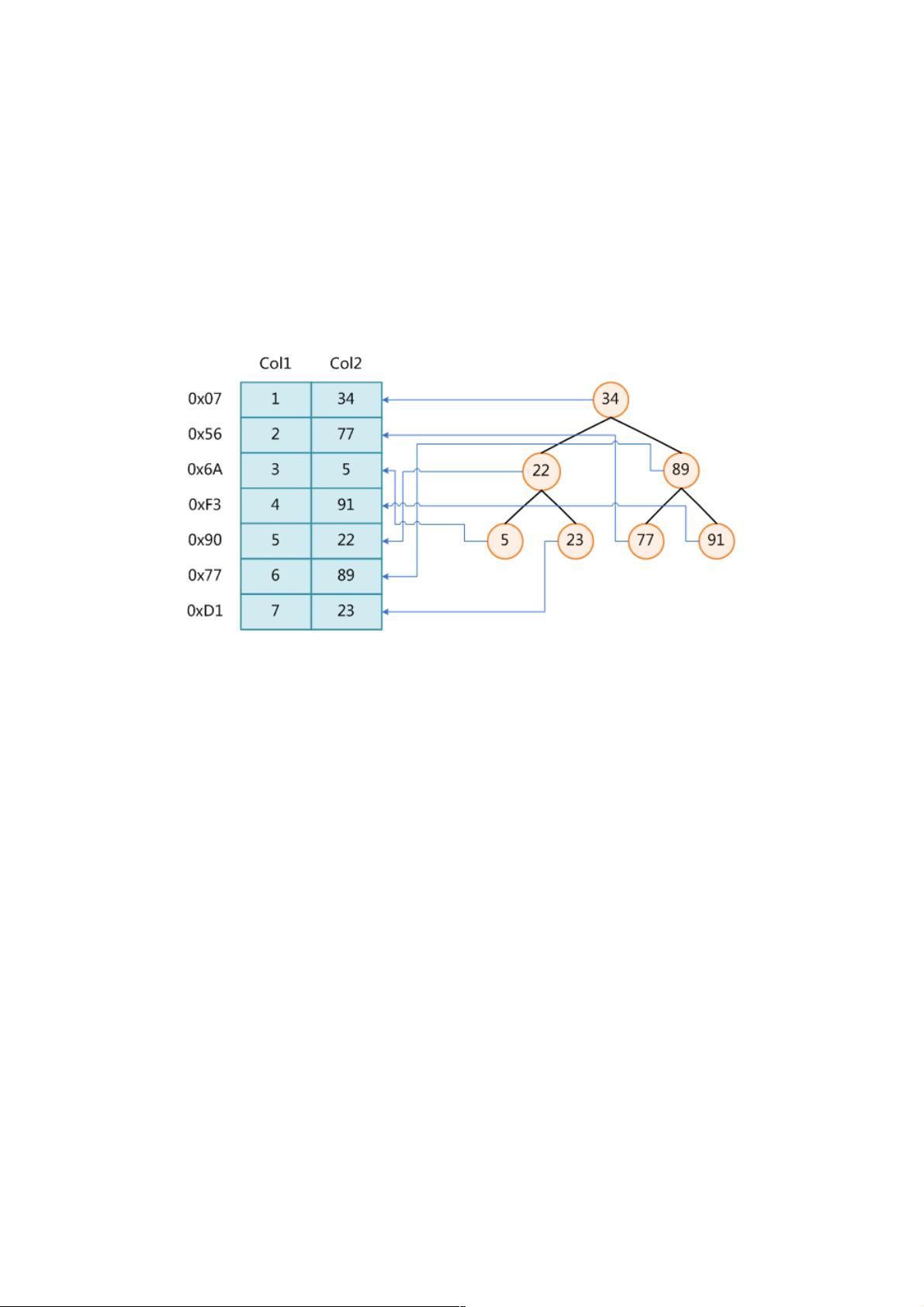
以一个简单的例子来说明,假设有一个包含两列七条记录的表,为了加速对第二列(Col2)的查找,可以创建一个二叉查找树,其中每个节点包含索引键值和指向对应数据记录物理地址的指针。通过这样的索引,可以在对数时间内O(log2n)找到目标数据,大大提升了查询效率。
然而,实际的数据库系统如MySQL并不常用二叉查找树,而是选择更适合大量数据存储的B树(B-Trees)或其他变体,如B+树。B树是一种自平衡的多路搜索树,它能够保持数据排序,并允许在对数时间内完成查找、插入和删除操作,尤其适合用于大型数据库和文件系统,因为它可以有效减少磁盘I/O操作。
二叉排序树(Binary Sort Tree),又称为二叉查找树,是一种特殊的二叉树,其特点是左子树的所有节点值小于根节点,右子树所有节点值大于根节点,且左右子树都是二叉排序树。尽管这种数据结构在查找上表现良好,但由于其不平衡性可能导致查找效率降低,尤其是在数据动态变化较大的场景下。
MySQL的索引底层实现原理涉及到多种数据结构,尤其是B树家族,它们能够确保即使在数据量巨大时也能保持高效的查找性能。理解这些原理有助于优化数据库设计,从而提升整体系统的查询效率。
MySQL索引底层实现原理索引底层实现原理
索引的本质
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本
质:索引是数据结构。
我们知道,数据库查询是数据库的最主要功能之一。我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从
查询算法的角度进行优化。最基本的查询算法当然是顺序查找(linear search),这种复杂度为O(n)的算法在数据量很大时显
然是糟糕的,好在计算机科学的发展提供了很多更优秀的查找算法,例如二分查找(binary search)、二叉树查找(binary
tree search)等。如果稍微分析一下会发现,每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据
有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能
同时将两列都按顺序进行组织),所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某
种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
看一个例子:
上图展示了一种可能的索引方式。左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址(注意逻辑上相邻的
记录在磁盘上也并不是一定物理相邻的)。为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含
索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找在O(logn2)O(log2n)的复杂度内获取到相应数
据。
虽然这是一个货真价实的索引,但是实际的数据库系统几乎没有使用二叉查找树或其进化品种红黑树(red-black tree)实现
的,原因会在下文介绍。
二叉排序树
在介绍B树之前,先来看另一棵神奇的树——二叉排序树(Binary Sort Tree),首先它是一棵树,“二叉”这个描述已经很明显
了,就是树上的一根树枝开两个叉,于是递归下来就是二叉树了(下图所示),而这棵树上的节点是已经排好序的,具体的排
序规则如下:
若左子树不空,则左子树上所有节点的值均小于它的根节点的值
若右子树不空,则右字数上所有节点的值均大于它的根节点的值
它的左、右子树也分别为二叉排序数(递归定义)
下载后可阅读完整内容,剩余7页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-01-19 上传
2023-04-23 上传
2023-06-07 上传
2023-04-18 上传
2023-02-23 上传

weixin_38733281
- 粉丝: 2
- 资源: 953
 我的内容管理
展开
我的内容管理
展开







最新资源
- 搜索引擎--原理、技术与系统
- Hibernate开发指南
- Ajax经典案例开发大全
- GDB完全中文手册GDB调试
- JThread manual
- mapinfo用户指南
- Spring入门教程
- 7 Development Projects with the 2007 Microsoft Office System and Windows SharePoint Services 2007.pdf
- Delphi高手突破(官方版).pdf
- 中国DTMF制式来电显示国标
- 软件工程方面的学习课件参考
- IIS6缓冲区超过其配置限制
- 一种新的基于随机hough变换的椭圆检测算法
- Linux0.11内核完全注释.pdf
- eclipse 教程
- linux 18B20驱动程序
