优化SLIDE:现代CPU上深度学习加速策略 - 矢量化、量化、内存优化与更多
66 浏览量
更新于2024-08-25
收藏 584KB PDF 举报
本文档探讨了在现代中央处理器(CPUs)上加速SLIDE深度学习的方法,这是一种基于稀疏哈希表的反向传播实现,旨在提高训练大规模神经网络的速度。SLIDE最初展示了在商业x86架构上,由于能够重用现有硬件和方便的虚拟化,深度学习应用的吸引力正在增强。然而,作者认为SLIDE当前的实现并不充分利用现代CPU的各种优化手段。
首先,文章着重讨论了向量化技术,特别是通过AVX-512(Advanced Vector Extensions)进行并行计算的优势。AVX-512是一种高级矢量化扩展,能够显著提升数据处理能力,使得SLIDE的计算流程可以有效地利用CPU的SIMD(单指令多数据)特性,从而大大提高运算效率。
其次,内存优化也是关键的一部分。作者分析了如何通过改进数据布局、减少不必要的内存访问以及使用更有效的内存管理策略来减少内存带宽消耗。这包括缓存优化、数据流管理和层次化存储策略,以降低延迟并提高整体性能。
此外,文中还提到了量化技术的应用。在深度学习中,量化是降低模型复杂度和计算需求的一种方法,通常通过牺牲一定程度的精度来换取更快的执行速度和更低的内存占用。作者可能研究了如何在保持模型准确性的前提下,将SLIDE中的数值计算进行量化,如使用低精度数据类型或混合精度训练。
最后,结合上述所有优化措施,论文展示了对SLIDE系统的重大改进,实现了高达7倍的性能提升。这表明通过针对CPU特性的定制化优化,深度学习在CPU上的表现可以与GPU竞争,甚至在某些场景中更具优势。
这篇论文提供了一种深度学习框架优化路径,对于CPU平台的开发者和研究人员来说,具有重要的参考价值,尤其是在追求高性能、低成本和易部署的AI应用场景中。通过细致的性能分析和实践,它揭示了如何利用现代CPU的特性来推动深度学习的发展,并为未来的工作提供了新的思路和技术指南。
Accelerating SLIDE Deep Learning on Modern CPUs: Vectorization, Quantizations, Memory Optimizations, and More
3
2
1
4
5
6
Feed-forward Pass
!
"
"
… !
#
"
Buckets (pointers only)
00 … 00
00 … 01
00 … 10
… … … …
11 … 11
!
"
$
… !
#
$
Buckets (pointers only)
00 … 00
00 … 01
00 … 10
… … … …
11 … 11
…
Thread 1 %
&
3
2
1
4
5
6
Hash Tables
Parameters
'
(
&
) '
(
*
) '
(
+
) '
(
,
) '
(
-
) '
(
.
…
Thread 2 %
*
1 4
6
Active Set
1
2
3
4
Query
Shared Memory
2 6
Active Set
1
2
3
4
Query
Activation
Activation
Retrieval
Retrieval
3
2
1
4
5
6
Backpropagation
!
"
"
… !
#
"
Buckets (pointers only)
00 … 00
00 … 01
00 … 10
… … … …
11 … 11
!
"
$
…
!
#
$
Buckets (pointers only)
00 … 00
00 … 01
00 … 10
… … … …
11 … 11
…
Thread 1 %
&
3
2
1
4
5
6
Hash Tables
Parameters
'
(
&
) '
(
*
) '
(
+
) '
(
,
) '
(
-
) '
(
.
…
Thread 2 %
*
1 4
6
Active Set
1
2
3
4
Shared Memory
2 6
Active Set
1
2
3
4
Activation
Activation
Update
Gradient
Gradient
Update
Update
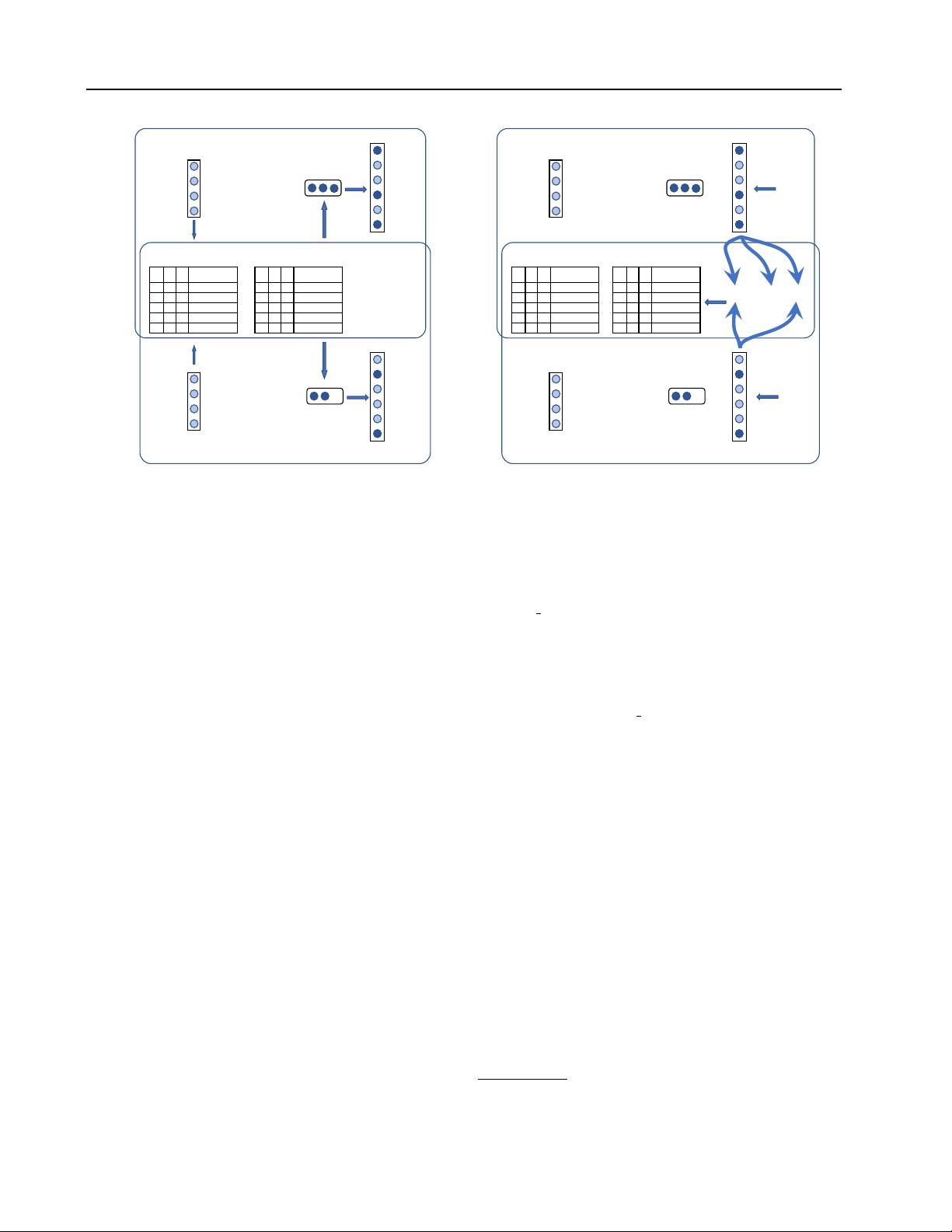
Figure 1.
Illustration of feed-forward and backward pass. Two threads are processing the two data instances
x
1
and
x
2
in parallel with
LSH hash tables and parameters in shared memory space.
updates. For example, on the right-hand side of Fig.1, only
the weights of neurons 1, 4, and 6 for data
x
1
and the
weights of neurons 2 and 6 for data
x
2
are updated. If a
fraction
p
of neurons in one layer is active, the fraction of
weights that would be updated is only
p
2
, which is a sig-
nificant reduction of computation when
p 1
. Afterward,
the hash tables are updated according to the new weights’
values. If the neuron’s buckets in the hash tables need to
be updated, it will be deleted from the current bucket in the
hash table and re-add it. We refer the interested readers to
(Chen et al., 2019) for a detailed review of the algorithm.
HOGWILD Style Parallelism
One unique advantage of
SLIDE is that every data instance in a batch selects a
very sparse and a small set of neurons to process and up-
date. This random and sparse updates open room for HOG-
WILD (Recht et al., 2011) style updates where it is possible
to process all the batch in parallel. SLIDE leverages multi-
core functionality by performing asynchronous data parallel
gradient descent.
3 TARGET CPU PLATFORMS: INTEL CLX
AND INTEL CPX
In this paper, we target two different, recently introduced,
Intel CPUs server to evaluate the SLIDE system and its
effectiveness:
Cooper Lake server (CPX)
(Intel, b) and
Cascade Lake server (CLX)
(Intel, a). Both of these pro-
cessors support AVX-512 instructions. However, only the
CPX machine supports bloat16.
CPX is the new 3rd generation Intel Xeon scalable processor,
which supports AVX512-based BF16 instructions. It has
Intel x86 64 architecture with four 28-core CPU totaling
112 cores capable of running 224 threads in parallel with
hyper-threading. The
L3
cache size is around 39MB, and
L2 cache is about 1MB.
CLX is an older generation that does not support BF16 in-
structions. It has Intel x86 64 architecture with dual 24-core
processors (Intel Xeon Platinum 8260L CPU @ 2.40GHz)
totaling 48 cores. With hyper-threading, the maximum num-
ber of parallel threads that can be run reaches 96. The
L3
cache size is 36MB, and L2 cache is about 1MB.
4 OPPORTUNITIES FOR OPTIMIZATION IN
SLIDE
The SLIDE C++ implementation is open sourced codebase
2
which allowed us to delve deeper into its inefficiencies. In
this section, we describe a series of our efforts in exploiting
the unique opportunities available on CPU to scaling up
SLIDE.
4.1 Memory Coalescing and cache utilization
Most machine learning jobs are memory bound. They re-
quire reading continuous data in batches and then updating
a large number of parameters stored in the main memory.
2
https://github.com/keroro824/HashingDeepLearning
剩余11页未读,继续阅读
2021-03-06 上传
2023-08-26 上传
2024-07-22 上传
2022-10-14 上传
2023-09-04 上传
2023-09-01 上传
2020-12-23 上传
2023-08-30 上传
2023-08-25 上传

假装高冷小姐姐
- 粉丝: 281
- 资源: 948
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
