深入理解Kafka:高吞吐分布式消息系统设计揭秘
152 浏览量
更新于2024-08-29
收藏 613KB PDF 举报
Kafka是一种高效、分布式的消息传递系统,由LinkedIn开发并逐渐成为Apache的开源项目。其设计原则注重高吞吐量和低延迟,使其在大数据处理和日志收集等领域表现出色。本文将深入探讨Kafka的核心组件及其工作原理。
首先,Kafka的核心组成部分包括:
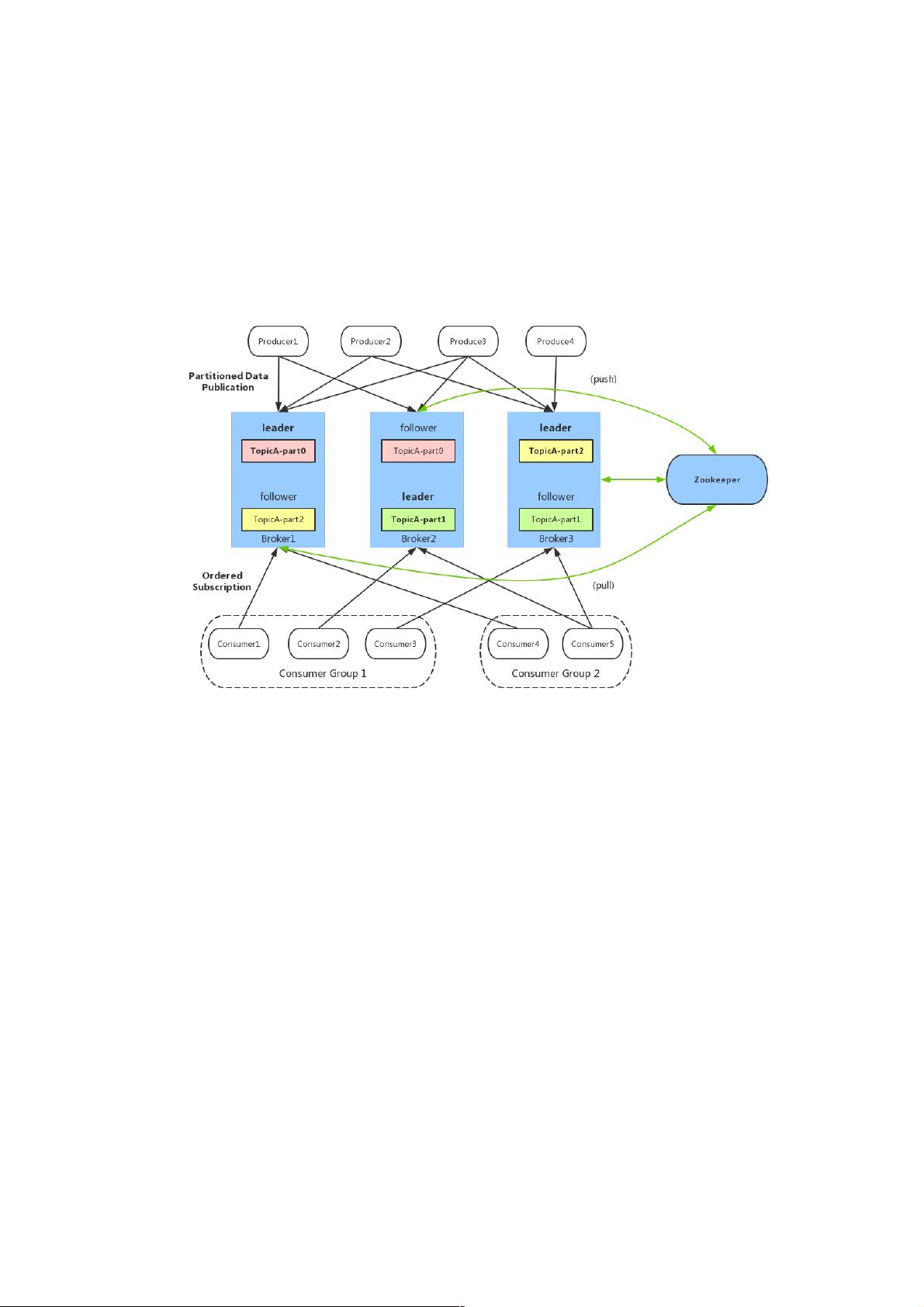
1. **Broker**:Kafka服务器,也称为节点,负责存储和转发消息。它们通过Zookeeper协调,确保数据的一致性和可靠性。每个主题(Topic)被划分为多个分区(Partition),每个分区独立存储数据,这样可以实现水平扩展。
2. **Topic**:消息分类的逻辑容器,类似数据库的表,用于组织和分发数据。Kafka允许创建多主题,每个主题可以有多个分区。
3. **Partition**:topic的逻辑划分,分区是有序的、可复制的消息序列,通过编号标识。每个分区都有自己的索引(offset),它是消息的唯一标识符,记录了消息在分区中的顺序。
4. **Offset**:消息在partition中的位置标识,它不是物理位置,而是逻辑上的一个递增值,确保消息的顺序和唯一性。
5. **Producer**:消息生产者,负责发送数据到Kafka。生产者可以设置消息的分区策略,如轮询或随机分配。
6. **Consumer**:消息消费者,接收并处理从Kafka发出的消息。消费者通常组成Consumer Group,这样可以在消费过程中实现负载均衡和容错。
7. **Zookeeper**:Kafka的分布式协调服务,维护集群状态,如broker列表、topic配置等,以及重要的元数据管理,如partition leader选举和负载均衡。
在数据存储方面,Kafka采用了文件系统来持久化消息。每个分区的数据独立存储在一个文件中,文件名遵循 `<topic_name>-<partition_id>` 的格式。消息本身由三个部分组成:offset(逻辑位置)、message size(消息大小)和data(消息内容)。这些消息按照顺序写入文件,并通过offset进行索引。
Kafka的设计允许在不影响实时处理性能的情况下处理大量数据,通过分区和复制机制实现了高可用性和容错性。同时,它支持实时和批量处理,使得它在流处理和日志收集场景中成为理想的选择。通过理解这些核心概念,开发者可以更好地利用Kafka构建高效的分布式通信系统。
Kafka设计原理设计原理
一、Kafka简介
Kafka是一种高吞吐量、分布式、基于发布/订阅的消息系统,最初由LinkedIn公司开发,使用Scala语言编写,目前是Apache
的开源项目。
跟RabbitMQ、RocketMQ等目前流行的开源消息中间件相比,Kakfa具有高吞吐、低延迟等特点,在大数据、日志收集等应用
场景下被广泛使用。
本文主要简单介绍Kafka的设计原理。
二、Kafka架构
基本概念:
broker:Kafka服务器,负责消息存储和转发
topic:消息类别,Kafka按照topic来分类消息
partition:topic的分区,一个topic可以包含多个partition,topic消息保存在各个partition上
offset:消息在日志中的位置,可以理解是消息在partition上的偏移量,也是代表该消息的唯一序号
Producer:消息生产者
Consumer:消息消费者
Consumer Group:消费者分组,每个Consumer必须属于一个group
Zookeeper:保存着集群broker、topic、partition等meta数据;另外,还负责broker故障发现,partition leader选举,负载均衡
等功能
三、Kafka设计原理
3.1 数据存储设计
partition以文件形式存储在文件系统,目录命名规则:<topic_name>-<partition_id>,例如,名为test的topic,其有3个
partition,则Kafka数据目录中有3个目录:test-0, test-1, test-2,分别存储相应partition的数据。
partition的数据文件
partition中的每条Message包含了以下三个属性:
1.offset
2.MessageSize
下载后可阅读完整内容,剩余8页未读,立即下载
2023-12-25 上传
2022-08-03 上传
2018-06-25 上传
点击了解资源详情
2021-01-27 上传
2018-03-18 上传
2017-04-19 上传
2022-07-09 上传
2022-05-07 上传

weixin_38746738
- 粉丝: 4
- 资源: 931
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新代数控API接口实现CNC数据采集技术解析
- Java版Window任务管理器的设计与实现
- 响应式网页模板及前端源码合集:HTML、CSS、JS与H5
- 可爱贪吃蛇动画特效的Canvas实现教程
- 微信小程序婚礼邀请函教程
- SOCR UCLA WebGis修改:整合世界银行数据
- BUPT计网课程设计:实现具有中继转发功能的DNS服务器
- C# Winform记事本工具开发教程与功能介绍
- 移动端自适应H5网页模板与前端源码包
- Logadm日志管理工具:创建与删除日志条目的详细指南
- 双日记微信小程序开源项目-百度地图集成
- ThreeJS天空盒素材集锦 35+ 优质效果
- 百度地图Java源码深度解析:GoogleDapper中文翻译与应用
- Linux系统调查工具:BashScripts脚本集合
- Kubernetes v1.20 完整二进制安装指南与脚本
- 百度地图开发java源码-KSYMediaPlayerKit_Android库更新与使用说明
