高分辨率多视图立体网络:快速三维重建
需积分: 0 84 浏览量
更新于2024-08-03
收藏 4.17MB PDF 举报
"HighRes-MVSNet:一种用于高分辨率图像密集型3D重建的快速多视图立体网络"
本文介绍的HighRes-MVSNet是一种基于深度学习的端到端架构,专为从高分辨率图像中进行密集三维重建设计。当前,许多研究集中在提高重建质量上,但HighRes-MVSNet的主要关注点在于减少内存需求,以便更好地利用高分辨率图像提供的丰富信息。这一方法在处理大量数据时具有显著优势,尤其是在高分辨率场景下,传统的立体匹配和3D重建技术可能会因内存限制而效率低下。
HighRes-MVSNet的工作流程可能包括以下几个关键步骤:
1. **特征提取**:网络首先对输入的高分辨率图像进行特征提取,通常使用卷积神经网络(CNN)来捕捉图像的细节和上下文信息。
2. **多视图融合**:利用多个视图的信息,网络通过立体匹配技术融合来自不同角度的图像特征,这有助于提高深度估计的准确性。
3. **内存优化策略**:为了处理高分辨率数据,HighRes-MVSNet可能采用了特定的内存管理策略,如分块处理、金字塔结构或层次化预测,这些策略可以有效地减少内存占用,同时保持重建的质量。
4. **深度图生成**:通过上述步骤,网络最终能够生成一个连续的深度图,表示每个像素在3D空间中的位置。
5. **三维重建**:深度图结合相机参数,可以进一步转化为三维点云或网格模型,完成整个3D重建过程。
该工作得到了欧洲创新与技术研究所(EIT)RawMaterials项目18004和欧盟地平线2020研究与创新计划下的RESIST项目( Grant 769066)的支持,这表明其在实际应用和科研领域的广泛潜力。
在实际应用中,HighRes-MVSNet可能应用于建筑、地理信息系统、自动驾驶汽车、虚拟现实等领域,为高精度的环境建模和场景理解提供技术支持。由于其对内存效率的重视,该方法尤其适用于资源有限的设备,如无人机或移动设备上的实时3D重建任务。
HighRes-MVSNet通过深度学习和内存优化,解决了高分辨率图像在多视图立体匹配中的挑战,实现了高效且高质量的3D重建。这不仅提高了重建的速度,而且扩大了深度学习在高分辨率3D重建应用中的适用范围。
Received December 21, 2020, accepted December 30, 2020, date of publication January 11, 2021,
date of current version January 21, 2021.
Digital Object Identifier 10.1109/ACCESS.2021.3050556
HighRes-MVSNet: A Fast Multi-View Stereo
Network for Dense 3D Reconstruction
From High-Resolution Images
RAFAEL WEILHARTER AND FRIEDRICH FRAUNDORFER , (Member, IEEE)
Institute of Computer Graphics and Vision, Graz University of Technology, 8010 Graz, Austria
Corresponding author: Rafael Weilharter (rafael.weilharter@icg.tugraz.at)
This work was supported in part by the European Institute of Innovation and Technology (EIT) RawMaterials under Project 18004, and in
part by the RESilient transport InfraSTructure to extreme events (RESIST) Project through the European Union’s Horizon 2020 Research
and Innovation Program under Grant 769066.
ABSTRACT We propose an end-to-end deep learning architecture for 3D reconstruction from
high-resolution images. While many approaches focus on improving reconstruction quality alone, we pri-
marily focus on decreasing memory requirements in order to exploit the abundant information provided by
modern high-resolution cameras. Towards this end, we present HighRes-MVSNet, a convolutional neural
network with a pyramid encoder-decoder structure searching for depth correspondences incrementally over
a coarse-to-fine hierarchy. The first stage of our network encodes the image features to a much smaller
resolution in order to significantly reduce the memory requirements. Additionally, we limit the depth search
range in every hierarchy level to the vicinity of the previous prediction. In this manner, we are able to produce
highly accurate 3D models while only using a fraction of the GPU memory and runtime of previous methods.
Although our method is aimed at much higher resolution images, we are still able to produce state-of-the-art
results on the Tanks and Temples benchmark and achieve outstanding scores on the DTU benchmark.
INDEX TERMS Convolutional neural network, dense 3D reconstruction, multi-view stereo.
I. INTRODUCTION
Multi-View Stereo (MVS) attempts to reconstruct a highly
detailed 3D model of an observed scene from images with
different viewpoints. The prerequisites are known intrinsic
and extrinsic camera parameters which can be obtained via
Structure from Motion (SfM) (see Fig. 1). MVS has been
a well studied problem for decades and traditional meth-
ods based on geometric context [2], [6], [7], [26] achieved
great success when reconstructing scenes with Lambertian
surfaces, especially in terms of accuracy. However, they
struggle with the reconstruction of low-textured, specular,
and reflective regions and in terms of completeness. Further-
more, they usually take a very long time to establish the 3D
correspondence and larger scenes can take several hours to
process.
To address these issues more recent approaches [12], [15]
use deep Convolutional Neural Networks (CNNs) which
are several times faster while also improving the overall
The associate editor coordinating the review of this manuscript and
approving it for publication was Mehul S. Raval .
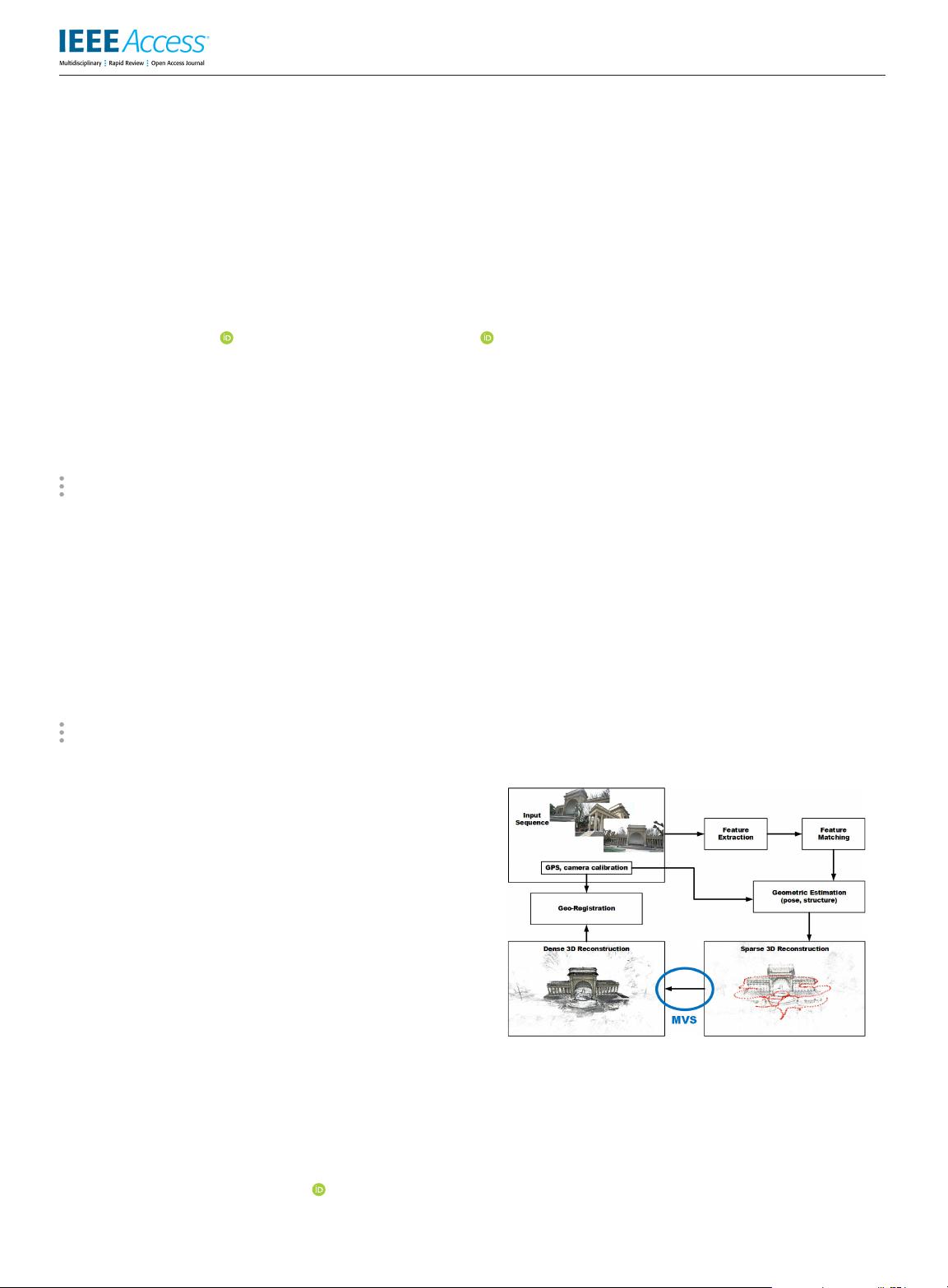
FIGURE 1. Overview of the Structure from Motion pipeline. MVS attempts
to create a denser, more appealing 3d model from sparse reconstruction
information.
3D reconstruction quality of a scene. This can be mostly
attributed to the fact that learning-based methods can incor-
porate global semantic information such as specular and
reflective priors for more robust matching. Furthermore, if the
11306
This work is licensed under a Creative Commons Attribution 4.0 License. For more information, see https://creativecommons.org/licenses/by/4.0/
VOLUME 9, 2021
下载后可阅读完整内容,剩余9页未读,立即下载
781 浏览量
点击了解资源详情
563 浏览量
164 浏览量
2021-07-08 上传
163 浏览量
258 浏览量
2021-05-30 上传

R-G-B
- 粉丝: 1923
 我的内容管理
展开
我的内容管理
展开







最新资源
- 32位TortoiseSVN_1.7.11版本下载指南
- Instant-gnuradio:打造定制化实时图像和虚拟机GNU无线电平台
- PHP源码工具PHProxy v0.5 b2:多技术项目源代码资源
- 最新版PotPlayer单文件播放器: 界面美观且功能全面
- Borland C++ 必备库文件清单与安装指南
- Java工程师招聘笔试题精选
- Copssh:Windows系统的安全远程管理工具
- 开源多平台DimReduction:生物信息学的维度缩减利器
- 探索Novate:基于Retrofit和RxJava的高效Android网络库
- 全面升级!最新仿挖片网源码与多样化电影网站模板发布
- 御剑1.5版新功能——SQL注入检测体验
- OSPF的LSA类型详解:网络协议学习必备
- Unity3D OBB下载插件:简化Android游戏分发流程
- Android网络编程封装教程:Retrofit2与Rxjava2实践
- Android Fragment切换实例教程与实践
- Cocos2d-x西游主题《黄金矿工》源码解析
