Swin Transformer:层次化视觉Transformer与Shifted窗口方法
需积分: 0 191 浏览量
更新于2024-08-03
1
收藏 942KB DOCX 举报
"Swin Transformer是基于Transformer架构的层次化视觉模型,用于解决视觉实体尺度变化和高分辨率像素问题。该模型结合Shifted Window方法,提高了计算效率并适用于各种视觉任务,如图像分类、目标检测和语义分割。"
Swin Transformer是2021年在IEEE/CVF国际计算机视觉会议上提出的一种创新的视觉Transformer模型,旨在克服将Transformer模型从自然语言处理领域移植到计算机视觉领域的困难。传统Transformer模型在处理图像时面临的主要挑战是视觉元素的大小变化和像素级别的分辨率,与处理单词序列时的固定长度和较低分辨率相比。Swin Transformer通过引入层次结构和Shifted Window机制,有效地解决了这些问题。
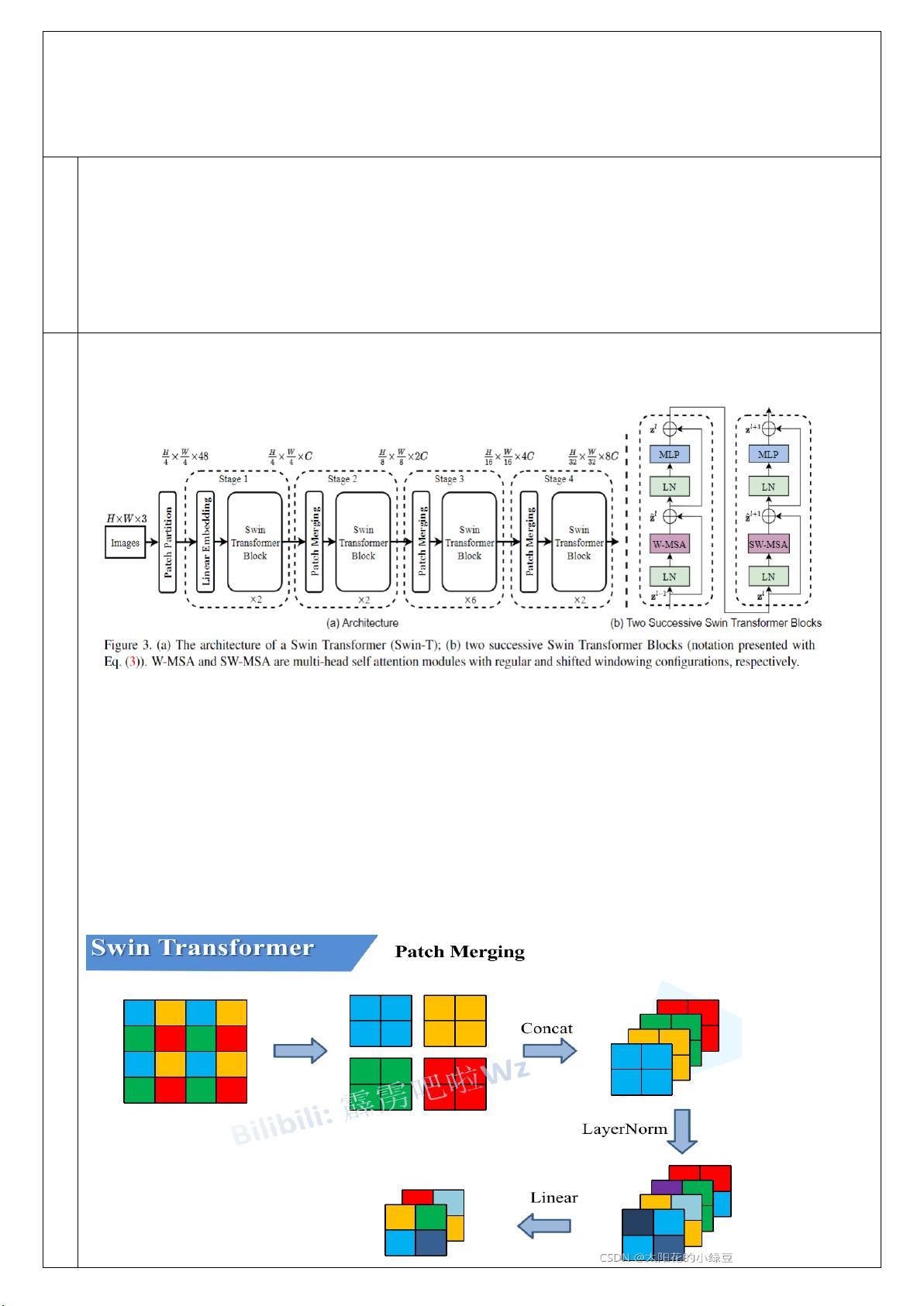
模型的核心思想是将输入图像分割成不重叠的patch,每个patch被视为一个单独的token,其特征由原始像素的RGB值串联而成。这些tokens经过线性嵌入层的投影,形成高维特征表示。不同于标准Transformer,Swin Transformer保持了层次化的结构,每个层次(Stage)处理不同尺度的信息。在层次间,通过Patch Merging层实现下采样,减少了token的数量,同时增加了特征的表达能力。
Patch Merging层的工作原理是将相邻的像素区域组合成更大的patch,然后在深度维度上堆叠这些patch,通过层归一化(LayerNorm)进一步增强表示。这种设计允许模型在不同的分辨率级别上捕获信息,有效地模拟了图像的局部和全局上下文。
Shifted Window机制是Swin Transformer的另一个关键创新,它避免了Transformer自注意力计算的全图连接,转而使用滑动窗口策略。在每个窗口内,计算自注意力,而在窗口之间,通过shift操作来引入跨窗口的信息交换。这种方法既保持了Transformer捕捉长距离依赖的能力,又显著降低了计算复杂度,使得模型更适应大规模图像数据的处理。
在实际应用中,Swin Transformer已被证明在多个视觉任务上表现出色,包括ImageNet图像分类、COCO目标检测和ADE20K语义分割等。由于其高效的计算和强大的表征能力,Swin Transformer已成为计算机视觉领域的一个重要进展,对后续研究和实践产生了深远影响。
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
会议:2021 IEEE/CVF International Conference on Computer Vision (ICCV)
收录时间:2021-10-01
研
究
背
景
和
思
路
这篇论文的研究背景是针对将 Transformer 模型从语言领域应用到计算机视觉领域所面临的挑战,
如视觉实体的度变化和像素分辨率高于文本中的单词等问题。为了解决这些问题,作者提了一种
名为 Swin Transformer 的层次化视觉 Transformer 模型,并用了 Shifted window 方法计算其表示。
该模型具有灵活性,可以在不同尺度下进行建模,并且与广泛的视觉任务兼容,包括图像、目标
检测和语义分割等。Shifted window 方法的优势在于其计算效率高,而且于所有的 MLP 架构都有
益。
模
型
及
算
法
分
析
它首先通过补丁分割模块(Patch Partition)将输入的 RGB 图像分割成不重叠的 patch。每个 patch 都被视为一个
“token”,其特征被设置为原始像素 RGB 值的串联。在我们的实现中,我们使用 4 × 4 的 patch size,因此
每个 patch 的特征维度为 4 × 4 × 3 = 48。在这个原始值特征上应用线性嵌入层,将其投影到任意维度(表示
为 C)。Transformer 块保持 token 的数量 (H/4 × W/4 ),以及线性嵌入称为“阶段 1”。
Patch Merging:在每个 Stage 中首先要通过一个 Patch Merging 层进行下采样(Stage1 除外)。例如输入 Patch
Merging 的是一个 4x4 大小的单通道特征图(feature map),Patch Merging 会将每个 2x2 的相邻像素划分为一个
patch,然后将每个 patch 中相同位置(同一颜色)像素给拼在一起就得到了 4 个 feature map。接着将这四个 feature
map 在深度方向进行 concat 拼接,然后在通过一个 LayerNorm 层。最后通过一个全连接层在 feature map 的深
度方向做线性变化,将 feature map 的深度由 C 变成 C/2。通过这个简单的例子可以看出,通过 Patch Merging 层
后,feature map 的高和宽会减半,深度会翻倍。
下载后可阅读完整内容,剩余4页未读,立即下载
2022-05-29 上传
2022-02-22 上传
2023-08-11 上传
2023-04-14 上传
2023-07-07 上传
2023-08-24 上传
2024-12-22 上传
2024-12-22 上传
2024-12-22 上传

ʚF【O】ɞ
- 粉丝: 24
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- play-bootstrap:用于Bootstrap的Play框架库
- koa-fetchr:Fetchr 的中间件和 Koa 的兼容性包装器
- 基于GA遗传优化的TSP最短路径计算仿真
- TPV2-P2:还有一个理由不雇用我
- pepper-metrics:Pepper Metrics是一个工具,它可以帮助您使用RED方法收集运行时性能,然后将其输出为日志时间序列数据,默认情况下,它使用prometheus作为数据源,使用grafana作为UI
- 演讲少-项目开发
- LuaLSP:支持魔兽世界API的Lua语言服务器协议
- spsstonybrook.github.io
- MySpider:Java网络爬虫MySpider,特点是组件化,可插拔式的,可以根据一套接口实现你自己自定义的网络爬虫需求(本人JavaSE的温习项目,适合java新人)
- 基于ATtiny13的键控简单调光器-电路方案
- h2-h3-automated-measurement:自动测量h2和h3的工具
- pcb2gcode:此存储库已停产,开发仍在继续
- compass:Compass是一个轻量级的嵌入式分布式数据库访问层框架
- privacy-terms-observatory:隐私权条款天文台是已发布的隐私权和热门网站条款的存档
- 美团双buffer分布式ID生成系统
- *(星号)-项目开发
