CliqueNet:深度学习中的交替更新群集网络
需积分: 31 58 浏览量
更新于2024-09-09
2
收藏 1.33MB PDF 举报
“深度学习参考文献:改进信息流的深度网络结构——交替更新的团网络(CliqueNet)”
深度学习是现代人工智能领域的核心部分,它通过模拟人脑神经元网络来处理复杂的数据和任务。这篇文献《具有交替更新团的卷积神经网络》探讨了一种新的深度学习架构——CliqueNet,旨在改善网络中的信息流,从而缓解训练难度并提高参数利用率。
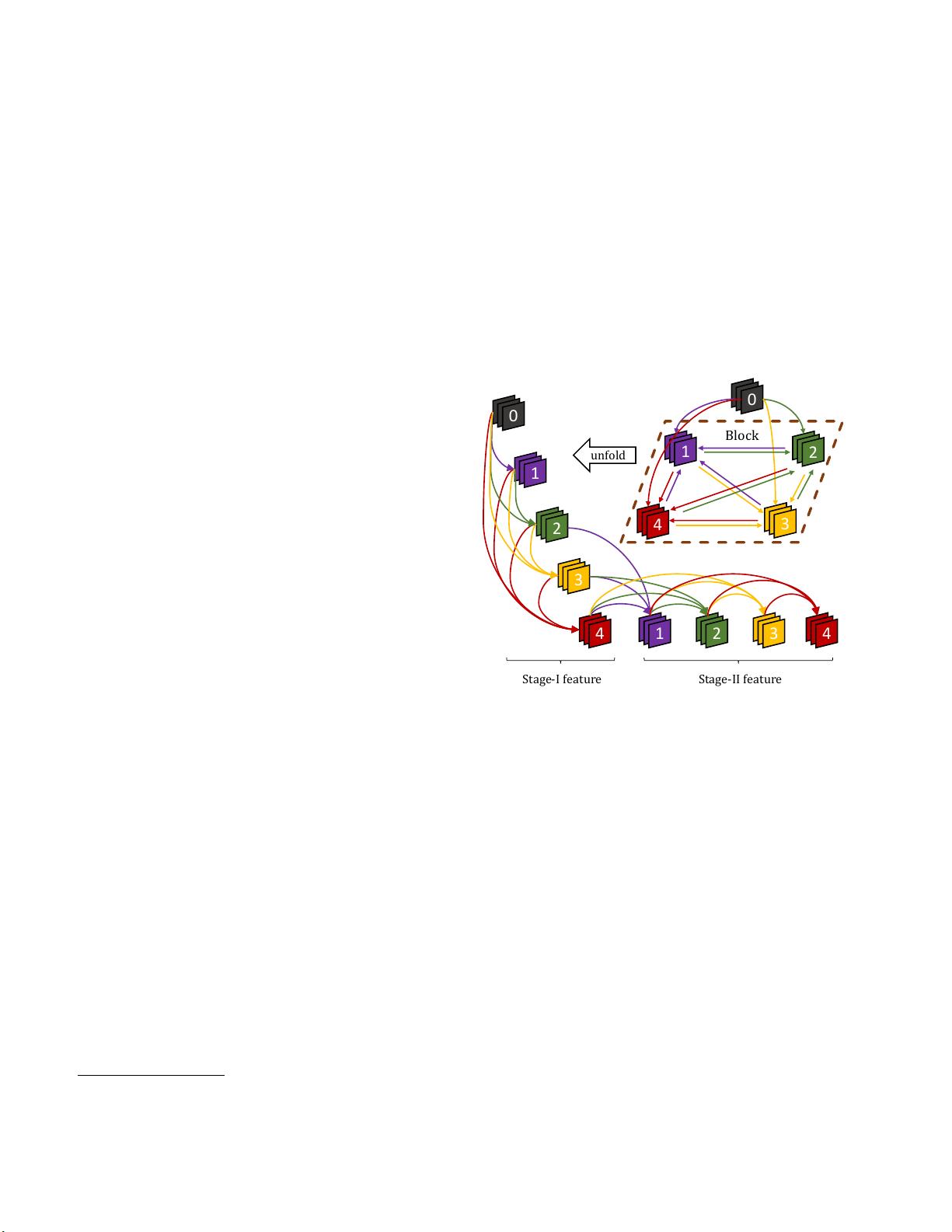
传统的卷积神经网络(CNN)通常采用前向传播的方式,其中信息从输入层逐层传递到输出层。然而,CliqueNet引入了不同寻常的设计,即在同一个块内的任何两层之间既有前向连接也有后向连接。这种设计使得层与层之间形成了一个循环结构,所有层都被更新交替进行。这一特性使得每一层既是其他层的输入,也是其他层的输出,最大化了层间的信息交互。
在CliqueNet的传播过程中,新更新的层被拼接起来,用于重新更新先前已经更新过的层,这允许参数的复用,进一步提高了效率。这种设计有助于增强网络的学习能力,因为它促进了信息的双向流动,使得网络能够更有效地捕获特征,并且可能减少梯度消失或梯度爆炸的问题,这是深度学习中常见的训练挑战。
CliqueNet的创新之处在于其独特的结构和更新机制。通过这种方式,网络可以更加灵活地调整其内部表示,适应不同的数据模式,同时保持模型的稳定性和准确性。文献中可能进一步探讨了CliqueNet在图像识别、语义分割、物体检测等任务上的性能,并与其他主流的深度学习架构进行了比较。
此外,作者还可能讨论了CliqueNet的训练策略,包括优化器的选择、损失函数的设计以及如何调整网络参数以适应不同的数据集。他们可能也分析了CliqueNet在计算资源需求和训练时间上的表现,以评估其在实际应用中的可行性。
这篇文献对深度学习领域提出了一个新颖的网络结构,它通过增强信息流和参数复用来优化深度学习模型的训练过程,对于提升模型的性能和训练效率具有重要意义。这对于深度学习的研究者和实践者来说,提供了探索和优化现有网络结构的新思路。
Convolutional Neural Networks with Alternately Updated Clique
Yibo Yang
1,2
, Zhisheng Zhong
2
, Tiancheng Shen
1,2
, Zhouchen Lin
2,3, ∗
1
Academy for Advanced Interdisciplinary Studies, Peking University
2
Key Laboratory of Machine Perception (MOE), School of EECS, Peking University
3
Cooperative Medianet Innovation Center, Shanghai Jiao Tong University
{ibo,zszhong,tianchengShen,zlin}@pku.edu.cn
Abstract
Improving information flow in deep networks helps to
ease the training difficulties and utilize parameters more
efficiently. Here we propose a new convolutional neu-
ral network architecture with alternately updated clique
(CliqueNet). In contrast to prior networks, there are both
forward and backward connections between any two layers
in the same block. The layers are constructed as a loop and
are updated alternately. The CliqueNet has some unique
properties. For each layer, it is both the input and output of
any other layer in the same block, so that the information
flow among layers is maximized. During propagation, the
newly updated layers are concatenated to re-update previ-
ously updated layer, and parameters are reused for mul-
tiple times. This recurrent feedback structure is able to
bring higher level visual information back to refine low-
level filters and achieve spatial attention. We analyze the
features generated at different stages and observe that using
refined features leads to a better result. We adopt a multi-
scale feature strategy that effectively avoids the progressive
growth of parameters. Experiments on image recognition
datasets including CIFAR-10, CIFAR-100, SVHN and Ima-
geNet show that our proposed models achieve the state-of-
the-art performance with fewer parameters
1
.
1. Introduction
In recent years, the structure and topology of deep neural
networks have attracted significant research interests, since
the convolutional neural network (CNN) based models have
achieved huge success in a wide range of tasks of computer
vision. A notable trend of those CNN architectures is that
the layers are going deeper, from AlexNet [23] with 5 con-
volutional layers, the VGG network and GoogleLeNet with
19 and 22 layers, respectively [32, 36], to recent ResNets
[13] whose deepest model has more than one thousand
layers. However, inappropriately designed deep networks
∗
Corresponding author
1
Code address: http://github.com/iboing/CliqueNet
0
1
2
3
4 1
2 3 4
Stage-I feature
Stage-II feature
unfold
1
2
3
4
0
Block
Figure 1. An illustration of a block with 4 layers. Any layer is
both the input and output of another one. Node 0 denotes the input
layer of this block.
would make it hard for latter layer to access the gradient in-
formation from previous layers, which may cause gradient
vanishing and parameter redundancy problems [17, 18].
Successfully adopted in ResNet [13] and Highway Net-
work [34], skip connection is an efficient way to make
top layers accessible to the information from bottom lay-
ers, and ease the network training at the same time, due
to its relief of the gradient vanishing problem. The resid-
ual block structure in ResNet [13] also inspires a series
of ResNet variations, including ResNext [40], WRN [41],
PolyNet [44], etc. To further activate the gradient and in-
formation flow in networks, DenseNet [17] is a newly pro-
posed structure, where any layer in a block is the output of
all preceding layers, and the input of all subsequent layers.
Recent studies show that the skip connection mechanism
can be extrapolated as a recurrent neural network (RNN)
or LSTM [14], when weights are shared among different
layers [27, 5, 21]. In this way, the deep residual network
下载后可阅读完整内容,剩余9页未读,立即下载
2020-10-20 上传
2020-06-13 上传
2017-11-01 上传
2022-08-04 上传
2024-05-12 上传
2023-05-25 上传
2024-04-28 上传
2021-08-18 上传

Lucian_s
- 粉丝: 2
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- AIserver-0.0.9-py3-none-any.whl.zip
- VC++使用SkinMagic换肤的简单实例
- 电信设备-轧机用四列圆柱滚子轴承喷油塞.zip
- devgroups:世界各地的大量开发者团体名单
- 用户级线程包
- xxl-job-executor:与xxl-job-executor的集成
- Java---Linker
- WebServer:基于模拟Proactor的C ++轻量级web服务器
- SkinPPWTL.dll 实现Windows XP的开始菜单(VC++)
- AIOrqlite-0.1.3-py3-none-any.whl.zip
- d3-playground:我在 Ember.js 中使用 D3 的冒险
- elastic_appsearch
- machine-learning-papers-summary:机器学习论文笔记
- 润滑脂
- osm-grandma:QBUS X OSM | OSM-GRANDMA Granny Revive脚本| 高质量RP | 100%免费
- Excel表格+Word文档各类各行业模板-节目主持人报名表.zip
