Pandas基础教程:Series与DataFrame详解
PDF格式 | 200KB |
更新于2024-08-31
| 91 浏览量 | 举报
"Pandas使用"
Pandas是Python中用于数据分析的核心库,它是基于NumPy构建的,因其强大的功能和易用性而深受喜爱。Pandas提供了两种独特且强大的数据结构:Series和DataFrame,使得数据处理变得更为高效和便捷。
**Series** 是Pandas的基本数据结构之一,类似于一维数组或列表,但具有更丰富的功能。Series可以存储各种类型的数据,如整数、浮点数、字符串等,并且每个元素都有一个与之关联的索引。默认情况下,索引是从0开始的整数序列,但用户可以自定义索引。Series的操作类似于列表和字典的结合,可以通过索引来访问和修改元素。例如:
```python
s = pd.Series([9, 3, 8], index=['a', 'b', 'c'])
```
在Series中,可以通过索引`s['a']`获取或修改特定位置的值。此外,Series还支持许多高级操作,如过滤、排序、统计计算等。
**DataFrame** 是Pandas的另一个核心数据结构,可以视为二维表格型数据,包含行和列,类似于电子表格或数据库表。DataFrame由多个Series组成,每个Series对应一列,并共享相同的索引。DataFrame提供了丰富的数据操作方法,如合并、连接、切片、聚合函数等,使得数据分析变得更加直观和高效。
例如,创建一个简单的DataFrame:
```python
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]}, index=['row1', 'row2', 'row3'])
```
在这个DataFrame中,'A'和'B'是列名,'row1'、'row2'、'row3'是行索引。通过`df['A']`可以访问列'A',而`df.loc['row1']`可以获取第一行的所有数据。
Pandas的一个显著优势是其“自动对齐”特性。当两个Series或DataFrame进行操作时,即使它们的索引不完全匹配,Pandas也会尝试对齐它们的索引,只处理有共同索引的部分,从而简化了数据操作。
Pandas还提供了数据读写功能,支持多种数据格式如CSV、Excel、SQL数据库等,方便数据导入导出。此外,它还集成了许多数据清洗和预处理的功能,如缺失值处理、数据转换等,使得数据准备阶段的工作更加顺畅。
Pandas是Python中用于数据分析的不可或缺的工具,它的设计理念是使数据操作直观、快速且易于理解,极大地提升了数据科学家和分析师的工作效率。无论是在学术研究还是商业应用中,Pandas都能提供强大而灵活的支持。
Pandas使用使用
Pandas 是基于 NumPy 的一个非常好用的库,正如名字一样,人见人爱。之所以如此,就在于不论是读取、处理数据,用它
都非常简单。
基本的数据结构
Pandas 有两种自己独有的基本数据结构。读者应该注意的是,它固然有着两种数据结构,因为它依然是 Python 的一个库,
所以,Python 中有的数据类型在这里依然适用,也同样还可以使用类自己定义数据类型。只不过,Pandas 里面又定义了两种
数据类型:Series 和 DataFrame,它们让数据操作更简单了。
以下操作都是基于:
为了省事,后面就不在显示了。并且如果你跟我一样是使用 ipython notebook,只需要开始引入模块即可。
Series
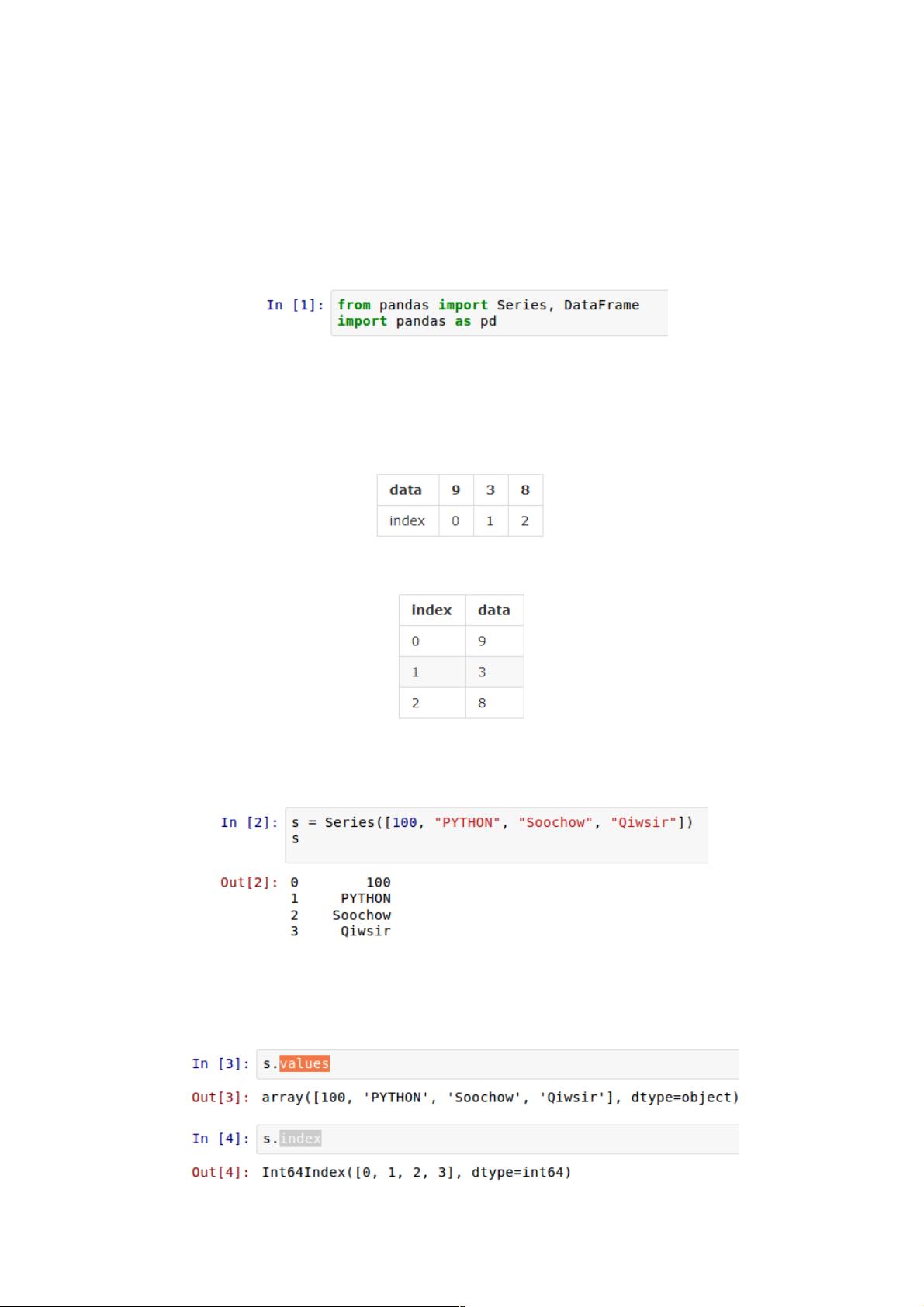
Series 就如同列表一样,一系列数据,每个数据对应一个索引值。比如这样一个列表:[9, 3, 8],如果跟索引值写到一起,就
是:
这种样式我们已经熟悉了,不过,在有些时候,需要把它竖过来表示:
上面两种,只是表现形式上的差别罢了。
Series 就是“竖起来”的 list:
另外一点也很像列表,就是里面的元素的类型,由你任意决定(其实是由需要来决定)。
这里,我们实质上创建了一个 Series 对象,这个对象当然就有其属性和方法了。比如,下面的两个属性依次可以显示 Series
对象的数据值和索引:
列表的索引只能是从 0 开始的整数,Series 数据类型在默认情况下,其索引也是如此。不过,区别于列表的是,Series 可以
自定义索引:
下载后可阅读完整内容,剩余3页未读,立即下载
相关推荐




160 浏览量


weixin_38577551
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Subclipse 1.8.2版:Eclipse IDE的Subversion插件下载
- Spring框架整合SpringMVC与Hibernate源码分享
- 掌握Excel编程与数据库连接的高级技巧
- Ubuntu实用脚本合集:提升系统管理效率
- RxJava封装OkHttp网络请求库的Android开发实践
- 《C语言精彩编程百例》:学习C语言必备的PDF书籍与源代码
- ASP MVC 3 实例:打造留言簿教程
- ENC28J60网络模块的spi接口编程及代码实现
- PHP实现搜索引擎技术详解
- 快速香草包装技术:速度更快的新突破
- Apk2Java V1.1: 全自动Android反编译及格式化工具
- Three.js基础与3D场景交互优化教程
- Windows7.0.29免安装Tomcat服务器快速部署指南
- NYPL表情符号机器人:基于Twitter的图像互动工具
- VB自动出题题库系统源码及多技术项目资源
- AndroidHttp网络开发工具包的使用与优势
