语料库语言学研究:背景、问题与进展
需积分: 0 118 浏览量
更新于2024-07-01
收藏 823KB PDF 举报
"2018211958 孙淼 自然语言理解1"
这篇资源主要探讨了自然语言理解的研究背景、模型方法以及相关的问题,特别是语料库的收集与整理在这一领域的关键作用。作者孙淼来自合肥工业大学计算机与信息学院,这是一份关于实验报告课程的作业,日期为10月10日。
一、研究背景
语料库是自然语言处理中的基础资源,它包含了大量实际的语言数据,用于语言学、计算机科学等多个领域的研究。随着计算机技术的进步,语料库的建设和应用变得越来越广泛。例如,北京语言学院和清华大学都建立了大规模的汉语语料库,推动了词法、句法、语义和语用研究的发展。然而,语料库建设面临着设计规范、产权保护等多方面的问题。
二、模型方法
虽然没有具体描述模型方法,但自然语言理解通常涉及的模型包括机器学习模型(如深度学习的神经网络模型)和统计模型(如N-gram模型)。这些模型通过学习语料库中的数据,能够理解和生成人类语言,实现自动翻译、情感分析、问答系统等功能。
三、语料库建设问题
1. 规范问题:语料库的加工需要遵循一定的标准和规范,如GB13000.1字符集、TEI、CES和SGML等。但实际操作中,分词标准的统一和文本属性的规范化仍有待完善。
2. 产权保护:随着语料库的重要性日益凸显,产权保护成为亟待解决的问题。目前尚缺乏专门针对语料库知识产品的法律法规,这可能影响到语料库的长期建设和可持续发展。
四、系统设计与演示分析
这部分内容未给出详细信息,但通常系统设计会涉及到数据预处理、模型构建、训练过程以及系统性能评估。系统演示与分析则会展示系统的实际应用效果和潜在的改进空间。
五、对课程的感想、意见和建议
这部分可能包含了作者对课程的个人反馈,包括课程内容的实用性、教学方法、实验环节的设计等方面,但具体内容未给出。
这份资源突出了语料库在自然语言理解中的核心地位,以及当前语料库建设所面临的挑战。它强调了规范性和产权保护在推动语料库科学发展中的重要性,同时也暗示了模型方法在解决这些问题上的潜力。
5
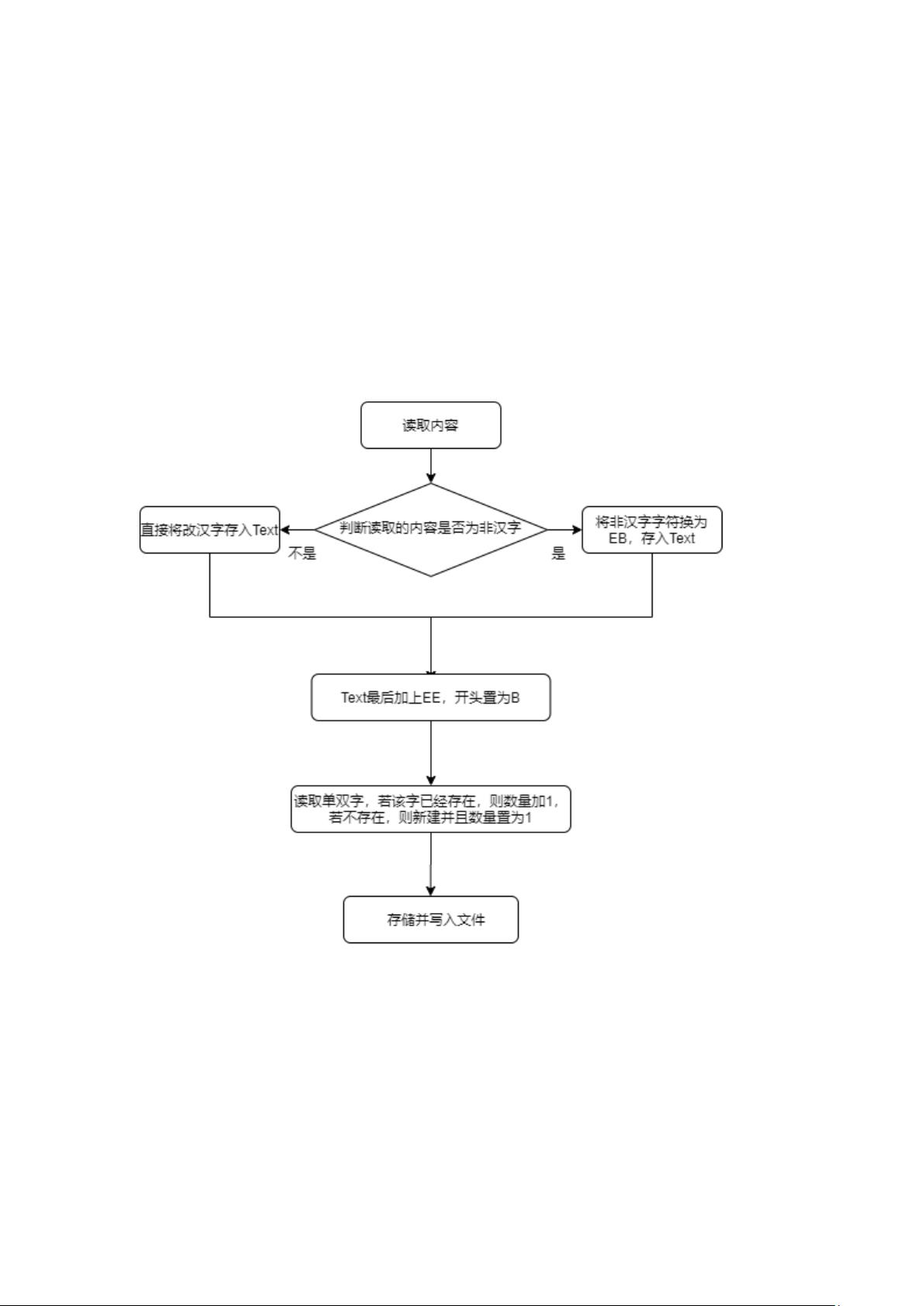
跳过并继续读取下一行,若大于 5 字符,则判定为词,此时通过规定
的正则表达式剔除出非汉字字符并在非字符出处分段,此后,对得到
的字符串进行滑动窗口式的挨个存取,单字和双字都进行存储,若该
字不存在,则新建该词并置数量为 1,若存在,则数量加 1,存储完
毕后,分别写入文件 sword.txt(表示单字)和 dword.txt(表示双
字)
首先,我对新闻语料库 news.txt 进行读取,读取到的汉字直接
存入 Text,读取到的非汉字字符以 EB 的形式存入 Text,并将 Text 开
头置 B,结尾置 EE,以使得读取的双字形式符合 N-gram 文法的定义。
最后,对得到的 Text 进行滑动窗口式的挨个存取,单字和双字
都进行存储,若该字不存在,则新建该词并置数量为 1,若存在,则

剩余32页未读,继续阅读
点击了解资源详情
110 浏览量
点击了解资源详情
2022-08-08 上传
2022-08-08 上传
2022-08-03 上传
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传

以墨健康道
- 粉丝: 34
 我的内容管理
展开
我的内容管理
展开







最新资源
- ASP.NET集成支付宝即时到账支付流程详解
- C++递推法在解决三道经典算法问题中的应用
- Qt_MARCHING_CUBES算法在面绘制中的应用
- 传感器原理与应用课程习题解答指南
- 乐高FLL2017-2018任务挑战解析:饮水思源
- Jquery Ui婚礼祝福特效:经典30款小型设计
- 紧急定位伴侣:蓝光文字的位置追踪功能
- MATLAB神经网络实用案例分析大全
- Masm611: 安全高效的汇编语言调试工具
- 3DCurator:彩色木雕CT数据的3D可视化解决方案
- 聊天留言网站开发项目全套资源下载
- 触摸屏适用的左右循环拖动展示技术
- 新型不连续导电模式V_2控制Buck变换器研究分析
- 用户自定义JavaScript脚本集合分享
- 易语言实现非主流方式获取网关IP源码教程
- 微信跳一跳小程序前端源码解析
