AlphaGo成长路径:深度解析MCTS与估值网络
需积分: 5 123 浏览量
更新于2024-07-19
2
收藏 2.55MB PPTX 举报
AlphaGo养成记是一份关于谷歌DeepMind开发的AlphaGo人工智能围棋程序的详细介绍,作者贾良跃通过整理网络资源和自己的理解,将复杂的算法概念简化讲解。AlphaGo的实现核心围绕以下几个关键组件:
1. **Policy Network (走棋网络)**: 这部分负责模拟决策过程,根据当前棋局状态生成下一个落子的概率分布。走棋网络是一个深度神经网络,它接收棋盘状态的19x19矩阵(或拉成的361维向量)作为输入,预测每个位置的走子概率。
2. **Fast Rollout (快速走子)**: 快速走子策略加速了MCTS(蒙特卡洛树搜索)的过程,通过预先模拟多个可能的后续步骤,减少实际计算的时间,提高搜索效率。
3. **Value Network (估值函数)**: 估值函数用于估算每一步棋后棋局的整体价值,帮助MCTS判断哪些路径更优。这通常也是一个神经网络,通过对棋盘状态的评估给出胜率或优势程度。
4. **Monte Carlo Tree Search (MCTS)**: MCTS是AlphaGo的核心算法,它是一种基于随机模拟的搜索技术,通过构建决策树来探索潜在的走子路径。平均广度(节点数量)约250,深度为150,体现了围棋的复杂性。MCTS在树的根节点开始,逐步扩展并回溯,直到达到叶节点(终局),通过估值函数和快走策略不断迭代优化。
5. **决策过程**: 下围棋的过程被设计为一个多分类问题,每个位置都是一个独立的决策节点,需要选择一个概率最高的位置落子。实际上,这是一个361维的分类问题,对应361个二分类器,每个分类器对每个位置打分。
6. **学习阶段**: 在模型训练阶段,DeepMind团队利用深度学习技术,如神经网络,将棋盘状态映射到走棋概率和估值函数的参数。他们发现利用棋盘的二维结构(矩阵)作为输入,有助于模型更好地理解游戏。
AlphaGo的养成记展示了如何通过结合深度学习、MCTS等先进技术,解决围棋这类复杂决策问题,并在实际下棋过程中展现出了强大的预测和决策能力。这个项目不仅展示了人工智能在围棋领域的突破,也体现了深度学习在解决高维决策问题上的潜力。
6
School of Mechanical Engineering @ BIT
AlphaGa
输入: 当前棋局的
落子情
况
模型: 决策模型
输出: 指导人下一
步的落子
条件:
总共就 19×19=361
个位置
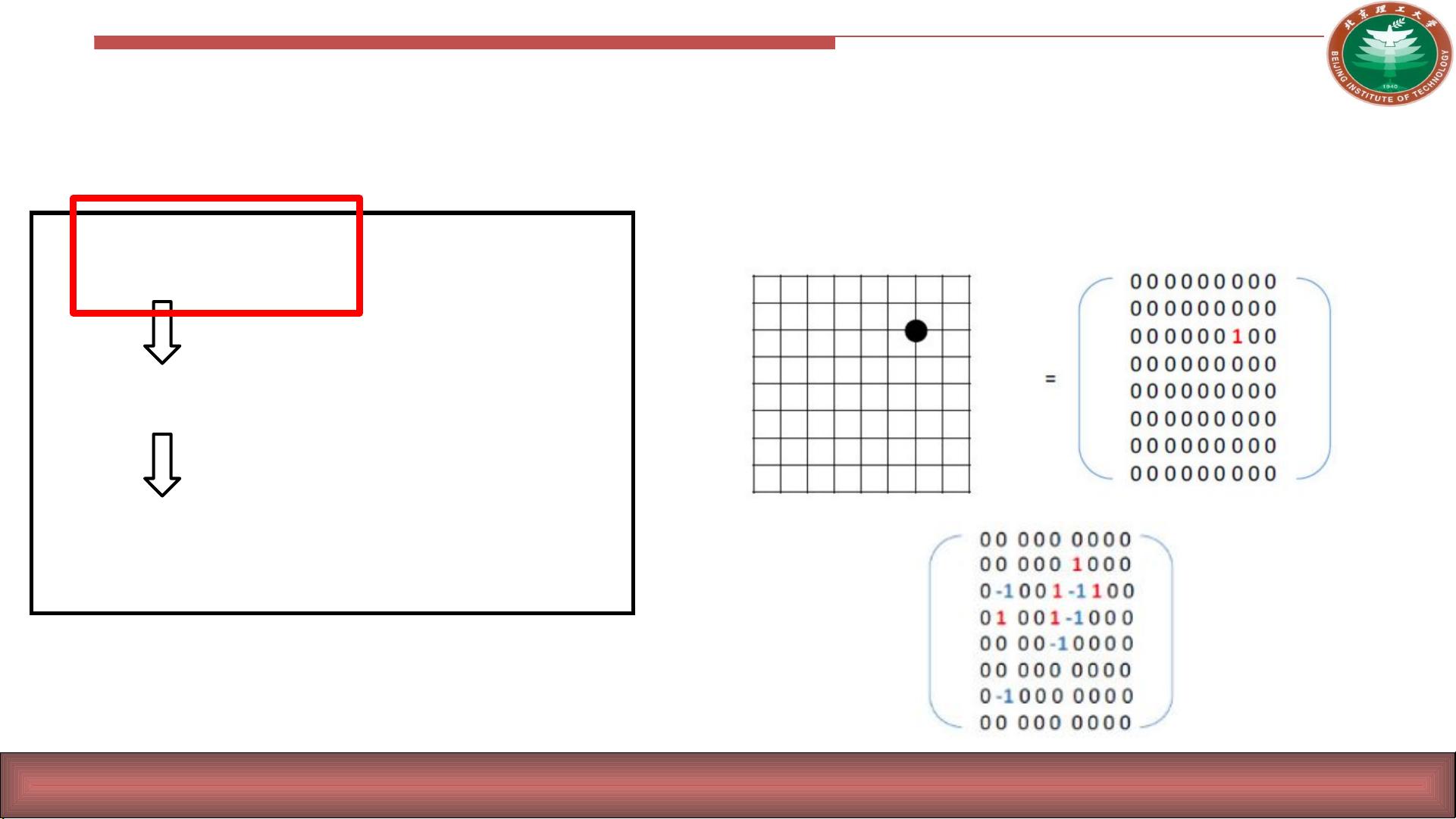
学习阶段——输入
当前局面,可以用一个 361*1 的向量表示。用 s 表示
理论上说,只输入这些特征就可以了。如下图就是演示用
矩阵表示棋局状态的情况,而矩阵拉长就是一个向量了:
可以用 1 表示黑子, -1 表示白字, 0 表示
无子
剩余26页未读,继续阅读
2019-10-16 上传
138 浏览量
2016-06-26 上传
2018-05-27 上传
2022-09-21 上传
2017-01-06 上传

小龙快跑jly
- 粉丝: 14
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Elasticsearch核心改进:实现Translog与索引线程分离
- 分享个人Vim与Git配置文件管理经验
- 文本动画新体验:textillate插件功能介绍
- Python图像处理库Pillow 2.5.2版本发布
- DeepClassifier:简化文本分类任务的深度学习库
- Java领域恩舒技术深度解析
- 渲染jquery-mentions的markdown-it-jquery-mention插件
- CompbuildREDUX:探索Minecraft的现实主义纹理包
- Nest框架的入门教程与部署指南
- Slack黑暗主题脚本教程:简易安装指南
- JavaScript开发进阶:探索develop-it-master项目
- SafeStbImageSharp:提升安全性与代码重构的图像处理库
- Python图像处理库Pillow 2.5.0版本发布
- mytest仓库功能测试与HTML实践
- MATLAB与Python对比分析——cw-09-jareod源代码探究
- KeyGenerator工具:自动化部署节点密钥生成
