前端异常监控与性能优化实践
185 浏览量
更新于2024-08-28
收藏 823KB PDF 举报
"前端性能与异常上报是前端开发中重要的监控和优化环节,涉及异常捕获和性能统计。对于后台开发,记录日志是常态,包括try...catch错误捕获和接口调用时间记录,方便问题排查。前端方面,异常监控和性能统计同样关键,尤其是在WebGL渲染、页面逻辑等方面,需要确保用户体验并量化优化效果。"
前端性能监控主要关注以下几个方面:
1. **接口调用性能**:前端会记录每个接口调用的响应时间和错误情况,以便分析性能瓶颈,优化加载速度。
2. **页面渲染时间**:优化页面渲染速度,减少白屏时间,提高用户体验。通过性能监控可以追踪渲染过程,评估优化策略的效果。
3. **WebGL渲染**:在涉及到3D图形渲染时,性能监控尤为重要,包括渲染失败、解析失败等问题的及时发现和解决。
4. **异常捕获**:包括接口调用异常和页面逻辑错误。接口调用异常需要上报客户端信息,如操作系统、浏览器版本和请求参数。页面逻辑错误则需要堆栈信息和错误位置,便于定位和修复。
5. **全局异常捕获**:利用`window.onerror`事件或`addEventListener`监听全局异常,收集异常信息并上报到日志服务器。
6. **用户环境模拟**:为了更全面地理解真实用户环境,需要考虑到不同设备、网络条件下的性能表现,确保测试数据的准确性和全面性。
异常上报通常包括以下步骤:
1. **安装错误监听器**:使用`window.onerror`或添加事件监听器,捕捉未被捕获的错误。
2. **收集信息**:获取错误的详细信息,如错误消息、文件路径、行号、列号以及堆栈跟踪。
3. **封装上报**:将收集到的信息整理成结构化的数据,如JSON格式,方便服务器解析。
4. **异步上报**:为了避免阻塞页面加载,异常上报应采用异步方式,如使用`fetch`或`XMLHttpRequest`。
5. **错误分类与处理**:根据错误类型和严重程度进行分类,设置不同的处理策略,如立即通知开发者、记录待后续处理等。
6. **性能指标收集**:记录页面加载时间、DOM构建时间、首字节时间(TTFB)、首屏渲染时间等,用于评估性能。
7. **持续监控与优化**:结合日志数据分析,持续改进前端性能,确保应用稳定性和用户体验。
通过这些方法,前端开发者可以更好地了解应用的运行状态,及时发现并解决问题,提升产品的稳定性和用户满意度。在实际项目中,可以利用现有的开源库和工具,如Sentry、LogRocket等,来辅助实现前端性能监控和异常上报。
前端性能与异常上报前端性能与异常上报
概述
对于后台开发来说,记录日志是一种非常常见的开发习惯,通常我们会使用 try...catch代码块来主动捕获错误、对于每次接口
调用,也会记录下每次接口调用的时间消耗,以便我们监控服务器接口性能,进行问题排查。
刚进公司时,在进行 Node.js的接口开发时,我不太习惯每次排查问题都要通过跳板机登上服务器看日志,后来慢慢习惯了这
种方式。
举个例子:
以下代码经常会出现在用 Node.js的接口中,在接口中会统计查询 DB所耗时间、亦或是统计 RPC服务调用所耗时间,以便监
测性能瓶颈,对性能做优化;又或是对异常使用 try ... catch主动捕获,以便随时对问题进行回溯、还原问题的场景,进行
bug的修复。
而对于前端来说呢?可以看以下的场景。
最近在进行一个需求开发时,偶尔发现 webgl渲染影像失败的情况,或者说影像会出现解析失败的情况,我们可能根本不知道
哪张影像会解析或渲染失败;又或如最近开发的另外一个需求,我们会做一个关于 webgl渲染时间的优化和影像预加载的需
求,如果缺乏性能监控,该如何统计所做的渲染优化和影像预加载优化的优化比例,如何证明自己所做的事情具有价值呢?可
能是通过测试同学的黑盒测试,对优化前后的时间进行录屏,分析从进入页面到影像渲染完成到底经过了多少帧图像。这样的
数据,可能既不准确、又较为片面,设想测试同学并不是真正的用户,也无法还原真实的用户他们所处的网络环境。回过头来
发现,我们的项目,虽然在服务端层面做好了日志和性能统计,但在前端对异常的监控和性能的统计。对于前端的性能与异常
上报的可行性探索是有必要的。
异常捕获
对于前端来说,我们需要的异常捕获无非为以下两种:
接口调用情况;
页面逻辑是否错误,例如,用户进入页面后页面显示白屏;
对于接口调用情况,在前端通常需要上报客户端相关参数,例如:用户OS与浏览器版本、请求参数(如页面ID);而对于页
面逻辑是否错误问题,通常除了用户OS与浏览器版本外,需要的是报错的堆栈信息及具体报错位置。
异常捕获方法
全局捕获
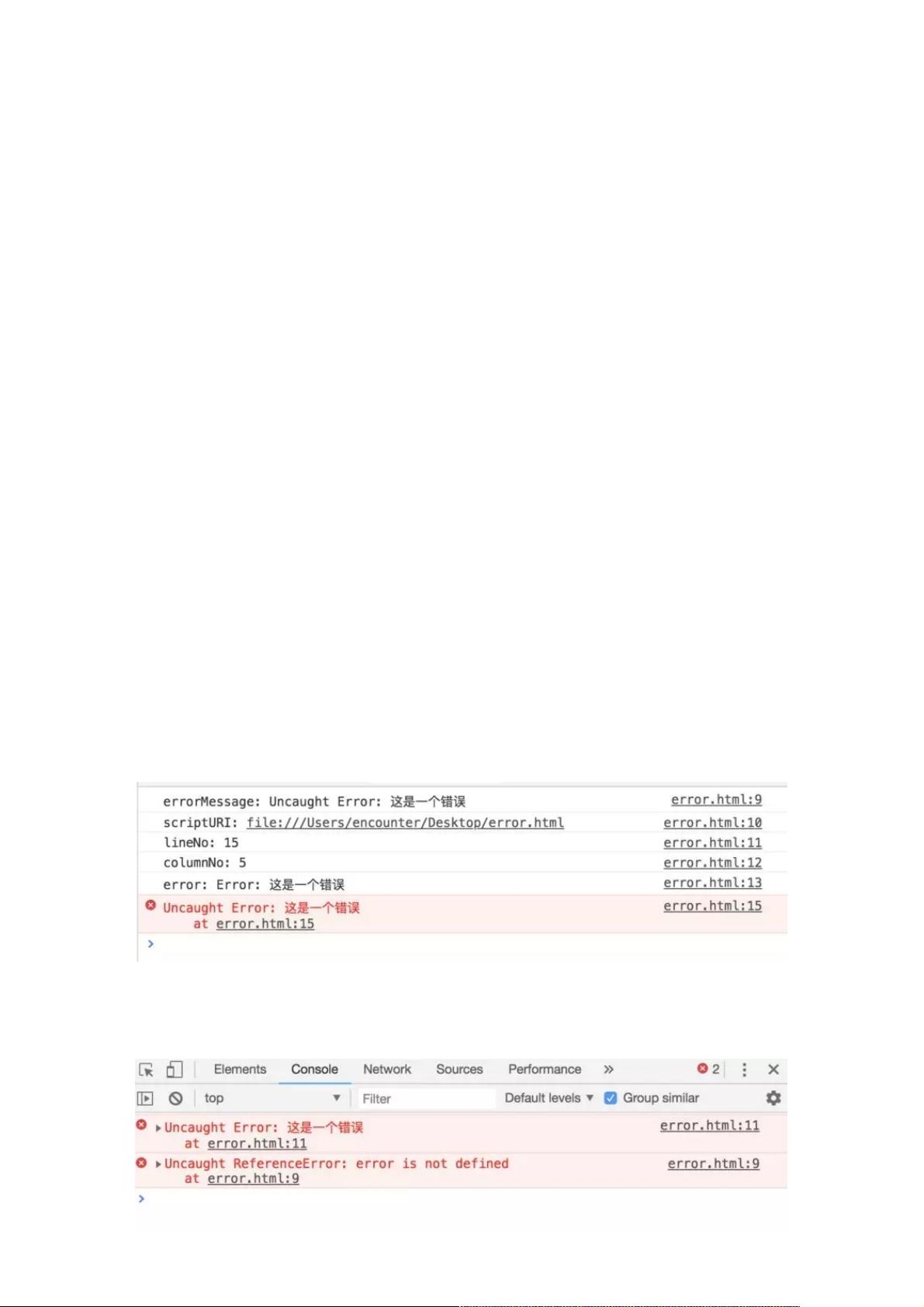
可以通过全局监听异常来捕获,通过 window.onerror或者 addEventListener,看以下例子:
通过 window.onerror事件,可以得到具体的异常信息、异常文件的URL、异常的行号与列号及异常的堆栈信息,再捕获异常
后,统一上报至我们的日志服务器。
亦或是,通过 window.addEventListener方法来进行异常上报,道理同理:
下载后可阅读完整内容,剩余5页未读,立即下载
393 浏览量
129 浏览量
265 浏览量
156 浏览量
159 浏览量
338 浏览量
156 浏览量
269 浏览量
281 浏览量

weixin_38554781
- 粉丝: 6
- 资源: 884
 我的内容管理
展开
我的内容管理
展开







最新资源
- 图像特征选取检测.rar
- adindrabkin.github.io
- suspicious-sierra:Sierra网络活动列表
- CustoPoly:Android 游戏类似于大富翁,但具有政治腐败主题。 最初存储在 https
- ssh-tutorial:SSH教程
- tondeuse à barbe-crx插件
- Cerita-Kita-Semua:动手Github Kelompok 12
- 供应链运作参考模型PPT
- 电子功用-基于光伏发电功率预测的防窃电监测方法
- Kindle, Nook and Kobo Book Deals-crx插件
- atividade_signo_carlos.Vitor
- 供应链管理与实践PPT课件
- VAP (Video Access Point):VAP 是一个无线接入点,用于分发音频/视频信号-开源
- 热电堆前置放大电路解析.rar
- github-slideshow:由机器人提供动力的培训资料库
- 企业物资与供应管理诊断PPT
