操作系统内存管理:Chapter 8 Main Memory
版权申诉
139 浏览量
更新于2024-07-03
收藏 1.56MB PPT 举报
"操作系统英文教学课件:Chapter 8 Main Memory.ppt,涵盖了内存管理的各种组织方式、技术,包括分页和分段等"
在计算机操作系统中,内存管理是至关重要的一个部分,它确保了程序的有效运行和内存资源的高效利用。这份Chapter 8 Main Memory的教学课件详细探讨了内存管理的多个方面,由Silberschatz、Galvin和Gagne三位专家在2005年第七版的《操作系统概念》中阐述。
首先,背景介绍涉及到内存硬件的组织方式,这包括了程序如何从磁盘加载到内存并放置在进程中以便运行。主内存(RAM)和寄存器是CPU可以直接访问的唯一存储空间。寄存器的访问速度极快,通常在一个CPU时钟周期内即可完成,而主内存则需要多个时钟周期,这导致了访问速度上的显著差异。为了弥补这一差距,引入了缓存(Caching)技术,它位于主内存和CPU寄存器之间,能够存储常用数据,提高数据访问速度。
8.3节中明确了课程目标,即深入讲解内存硬件的不同组织形式以及各种内存管理技术,如交换(Swapping)、覆盖(Overlay)、连续内存分配(Contiguous Memory Allocation)、分页(Paging)和分段(Segmentation)。这些技术各有特点,适应不同的系统需求和场景。
交换技术允许操作系统将不活跃的进程暂时从内存移出到磁盘,释放内存空间给其他进程,提高系统资源利用率。覆盖则是早期处理内存限制的一种方法,通过精心设计,让程序的不同部分在需要时才载入内存。连续内存分配则要求每个进程在内存中占据连续的空间,虽然简单,但易受碎片问题影响。
8.4节讨论了基本的硬件基础,强调了CPU对内存和寄存器的依赖,以及缓存作为提升性能的关键角色。缓存利用了局部性原理,即程序倾向于连续访问同一块内存区域,因此将最近访问或频繁访问的数据保存在快速存储中,可以显著减少等待时间。
分页和分段是两种内存管理策略。分页将内存划分为固定大小的页,进程的地址空间也相应地分割为页,通过页表映射内存中的位置。这种机制有利于内存保护和碎片管理,但增加了地址转换的复杂性。分段则允许更灵活的内存分配,根据程序逻辑结构划分段,每个段有自己的地址空间,提供了更好的模块性和共享能力,但也可能导致更大的内存碎片。
这份教学课件深入浅出地讲解了操作系统如何管理和优化内存资源,对于理解内存管理的基本原理和技术有极大的帮助,是学习操作系统课程的重要参考资料。
8.11
Silberschatz, Galvin and Gagne ©2005
Operating System Concepts – 7
th
Edition, Feb 22, 2005
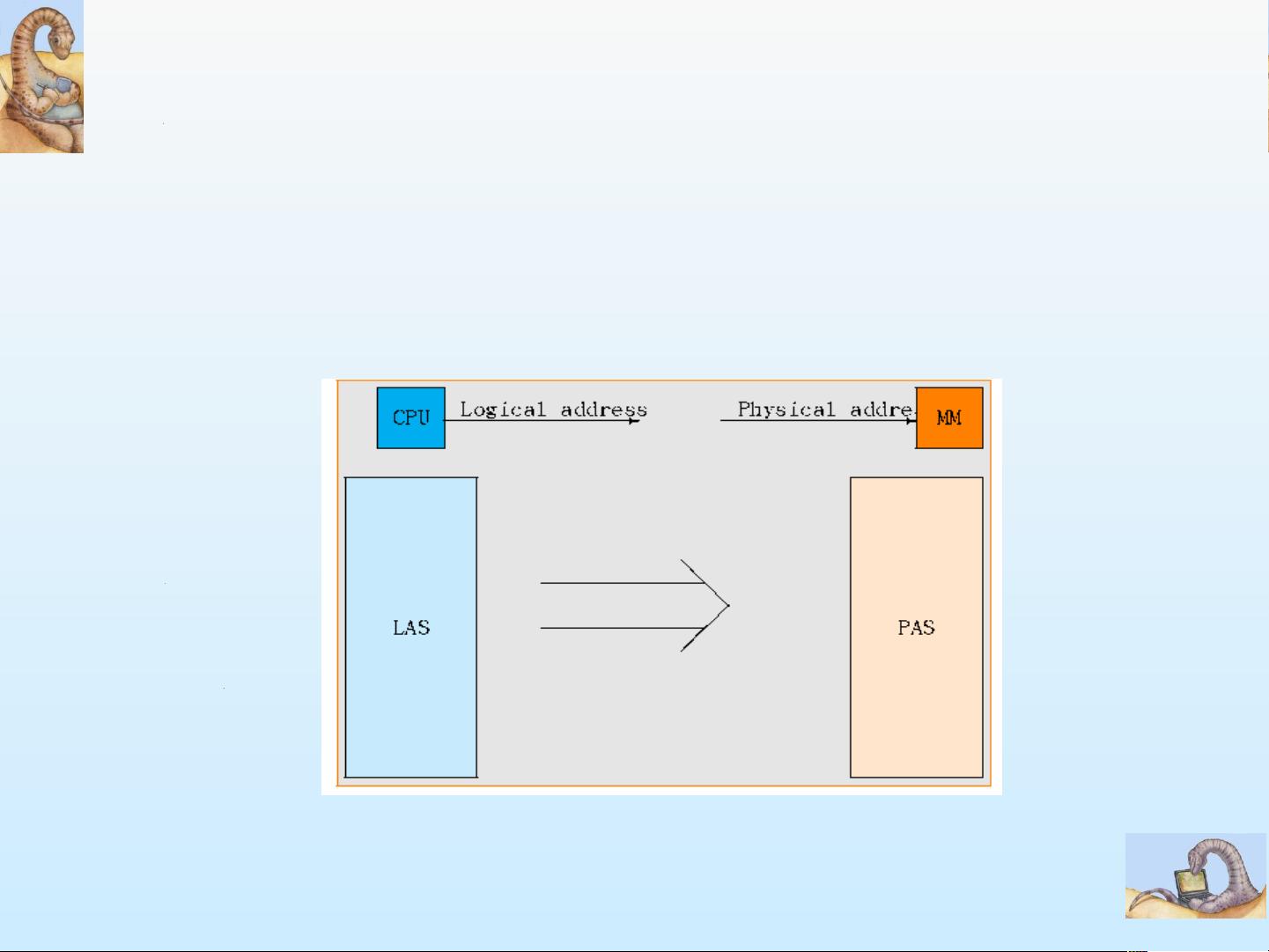
Logical vs. Physical Address Space
Logical address space:
the set of all logical addrs generated by a program
Physical address space:
the set of all physical addrs
WHEN can the absolute address can be decided?


剩余63页未读,继续阅读
2023-06-10 上传
2023-05-26 上传
2023-06-02 上传
2023-06-02 上传
2023-06-10 上传
2023-02-14 上传
2023-05-05 上传

wxg520cxl
- 粉丝: 25
- 资源: 3万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- JDK 17 Linux版本压缩包解压与安装指南
- C++/Qt飞行模拟器教员控制台系统源码发布
- TensorFlow深度学习实践:CNN在MNIST数据集上的应用
- 鸿蒙驱动HCIA资料整理-培训教材与开发者指南
- 凯撒Java版SaaS OA协同办公软件v2.0特性解析
- AutoCAD二次开发中文指南下载 - C#编程深入解析
- C语言冒泡排序算法实现详解
- Pointofix截屏:轻松实现高效截图体验
- Matlab实现SVM数据分类与预测教程
- 基于JSP+SQL的网站流量统计管理系统设计与实现
- C语言实现删除字符中重复项的方法与技巧
- e-sqlcipher.dll动态链接库的作用与应用
- 浙江工业大学自考网站开发与继续教育官网模板设计
- STM32 103C8T6 OLED 显示程序实现指南
- 高效压缩技术:删除重复字符压缩包
- JSP+SQL智能交通管理系统:违章处理与交通效率提升
