VECO:多语言预训练模型的灵活性与有效性
版权申诉
PDF格式 | 4.93MB |
更新于2024-07-05
| 58 浏览量 | 举报
7-7+VECO是一项2021年在DataFunSummit上提出的创新性研究,该研究聚焦于“灵活可变的多语言预训练模型”(Variable and Flexible Cross-lingual Pre-training for Language Understanding and Generation)。这一工作由罗福莉及其阿里达摩院-机器智能技术实验室主导,于2021年7月10日的在线峰会上进行了详细的讨论。
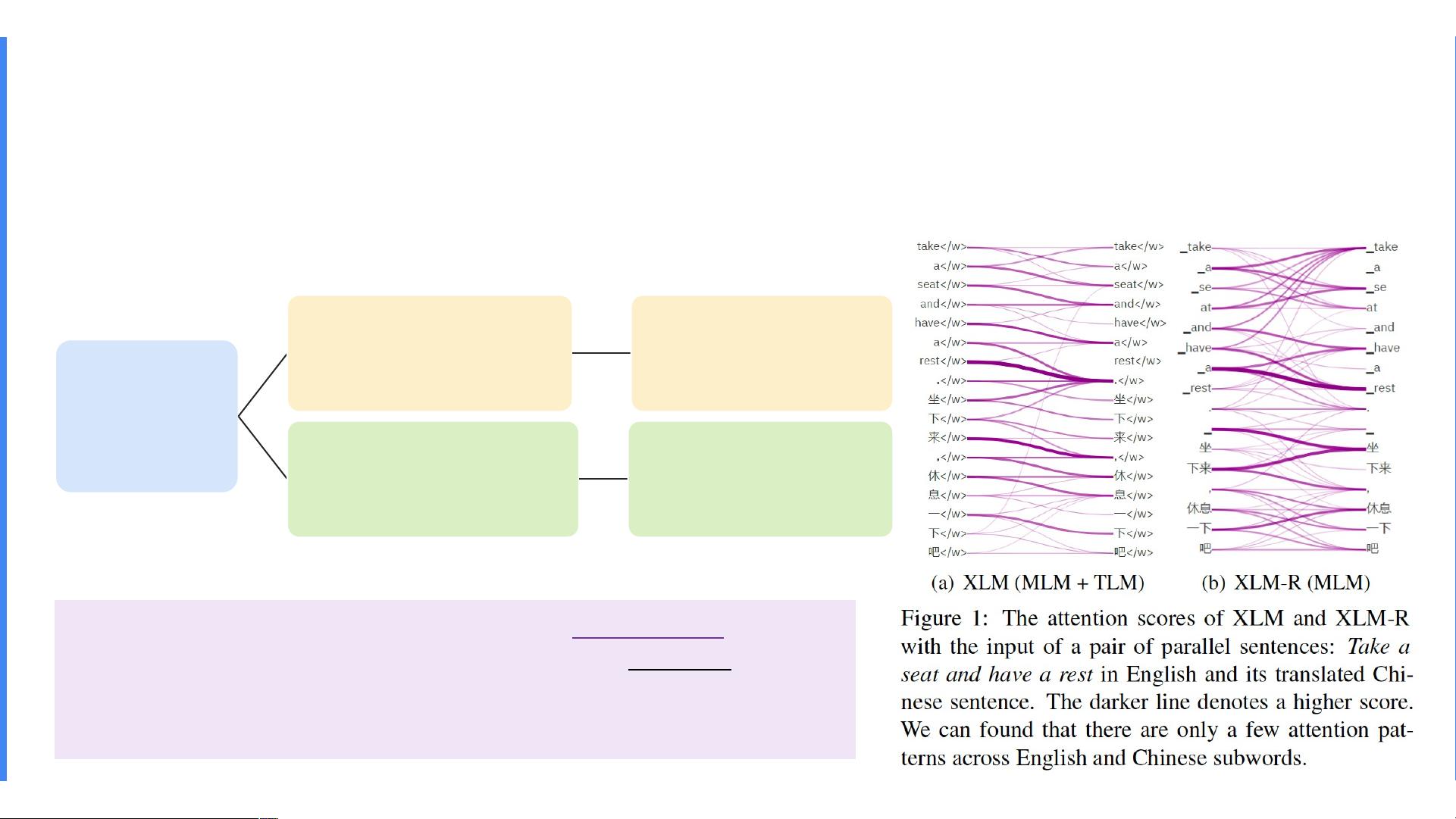
VECO的目标在于解决跨语言预训练中的核心问题,即如何构建统一的多语言表示,使得不同语言的数据可以共享一个词汇表,并通过子词分割来实现。研究者们扩展了传统的英语 masked language modeling (MLM) 方法,将其应用到多语种语料库,旨在捕捉平行数据中句子之间的对应关系。为此,他们提出了Translation Language Modeling (TLM),将两个平行句子作为输入,通过自注意力模块(query、key和value)进行模型训练。
然而,MLM和TLM的一个主要缺点是过于依赖自注意力机制,这可能导致在处理多种语言时存在局限性。VECO的研究者们针对这个问题,提出了全新的方法论,不仅关注预训练任务和模型架构,还探讨了如何联合训练自然语言理解(NLU)和自然语言生成(NLG)的任务,从而实现模型的灵活性。
VECO的主要内容包括以下几个部分:
1. **提出VECO的原因**:阐述了跨语言预训练的背景,强调了构建统一多语言表示的重要性,以及如何通过改进的子词分割和多任务学习来克服传统方法的不足。
2. **预训练任务与模型架构**:探讨了VECO如何设计适应不同语言特性的任务,并可能涉及对Transformer架构的优化,以提高模型在处理多种语言时的性能。
3. **训练方法**:详细解释了VECO的训练过程,可能包括多阶段预训练和微调策略,以及如何利用大规模多语种数据集进行有效学习。
4. **结果展示**:VECO在NLU方面的表现体现在XTREME Leaderboard上,展示了其在多项多语言理解任务上的卓越性能。而在NLG方面,VECO着重展示了在机器翻译任务中的应用和成果。
5. **结论**:总结VECO的优势和贡献,可能会提到它如何提高了多语言模型的泛化能力和效率,以及对未来研究的启示。
VECO代表了一种突破性的尝试,它通过灵活和可变的跨语言预训练方法,为多语言理解和生成任务带来了显著的进步,这在自然语言处理领域具有重要的理论和实践价值。随着VECO的发布,我们期待看到更多基于这种模型的创新应用和发展。
Background of Cross-lingual Pre-training
• From the perspective of pre-training tasks:
6
Aim:
Building unified
representations for
multilingual inputs
Build the shared vocabulary
across languages through
subword tokenization
Extends masked language
modeling (MLM) from
English corpus to
multilingual corpus
Capture the alignment in
parallel data via concatenating
two sentences as input
Translation Language
Modeling (TLM)
Drawback: Both MLM and TLM rely on the self-attention module
(query=key=value) of the Transformer encoder to implicitly enhance
the interdependence between languages, which may lead to few
attention patterns across languages
剩余21页未读,继续阅读
相关推荐




普通网友
- 粉丝: 13w+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Ruby语言集成Mandrill API的gem开发
- 开源嵌入式qt软键盘SYSZUXpinyin可移植源代码
- Kinect2.0实现高清面部特征精确对齐技术
- React与GitHub Jobs API整合的就业搜索应用
- MATLAB傅里叶变换函数应用实例分析
- 探索鼠标悬停特效的实现与应用
- 工行捷德U盾64位驱动程序安装指南
- Apache与Tomcat整合集群配置教程
- 成为JavaScript英雄:掌握be-the-hero-master技巧
- 深入实践Java编程珠玑:第13章源代码解析
- Proficy Maintenance Gateway软件:实时维护策略助力业务变革
- HTML5图片上传与编辑控件的实现
- RTDS环境下电网STATCOM模型的应用与分析
- 掌握Matlab下偏微分方程的有限元方法解析
- Aop原理与示例程序解读
- projete大语言项目登陆页面设计与实现
