Transformer模型解析:词嵌入、注意力机制与自注意力
下载需积分: 0 | PDF格式 | 743KB |
更新于2024-08-05
| 131 浏览量 | 举报
"该资源主要讲述了如何使用Transformer模型进行机器翻译,特别是关注了模型的核心组成部分,包括词嵌入、位置编码、注意力机制以及自注意力机制。"
在机器翻译领域,Transformer模型因其高效和强大的性能而备受关注。Transformer由Encoder和Decoder两部分组成,各自承担着不同的功能。Encoder负责理解输入的源语言序列,而Decoder则生成目标语言的翻译序列。
在Encoder中,首先进行的是词嵌入过程,这是将词汇转换为连续向量的过程。每个单词被表示为一个one-hot向量,通过与预训练的词嵌入矩阵相乘得到512维的词向量,这些词向量包含了语义信息。为了保留句子中的顺序信息,Transformer引入了位置编码。位置编码是通过正弦和余弦函数生成的,使得模型能够区分不同位置的词,即使它们有相同的词向量。
接下来是注意力机制,这是Transformer的关键创新之一。传统的RNN或CNN模型难以并行处理,而注意力机制允许模型同时考虑整个输入序列。它模拟人类阅读时的焦点转移,对输入序列的不同部分分配不同的注意力权重。自注意力机制是注意力机制的一种扩展,它计算当前词与序列中所有其他词的相关性,生成加权和的上下文向量,有助于模型理解整个句子的含义。
Decoder部分的工作原理类似,但还包含了解码过程中的遮蔽机制,以防止直接查看未来要生成的词,确保翻译的序列性。Decoder也通过多层自注意力和编码器-解码器注意力层逐步生成目标语言的翻译。
在训练过程中,使用预处理好的IWSLT'14 De-En数据集,该数据集包含了德语到英语的平行语料,用于监督学习。通过优化损失函数,模型逐渐学习到源语言和目标语言之间的映射关系,从而实现高质量的机器翻译。
Transformer模型利用词嵌入、位置编码、自注意力机制等创新技术,有效地解决了序列到序列学习的问题,尤其在机器翻译任务中表现出色。通过理解这些核心概念,可以深入掌握Transformer的工作原理,并应用于实际的自然语言处理任务。
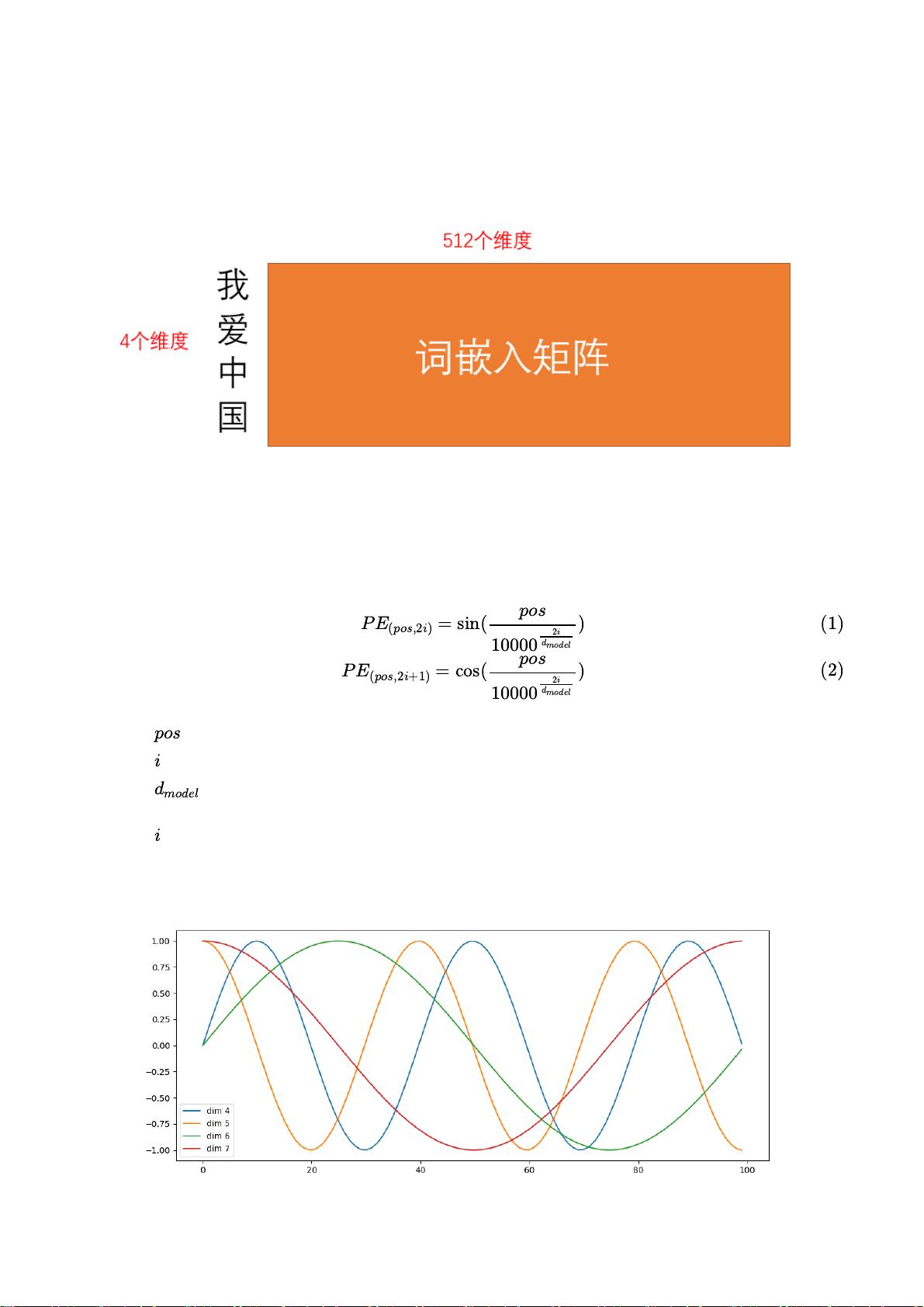
1、Embedding词嵌入
一个单词对应一个one-hot向量,一句话构成一个矩阵,通过与词嵌入矩阵做矩阵乘法获
得为维度为512的词嵌入向量,即这句话的分布式表示。下图以四个字(一个汉字一个单词)
为例,生成了4512的矩阵。
2、位置编码
位置编码公式如下:
:句子中的第几个单词
:词向量的第几维
:词嵌入维度
随着 的增大,正余弦函数的周期不断变大,以此将位置信息编码,输入给模型。图像大
致如下:
PE
(
pos
,2
i
)
= sin(
pos
10000
2
i
d
model
)
PE
(
pos
,2
i
+1)
= cos(
pos
10000
2
i
d
model
)
(1)
(2)
pos
i
d
model
i
剩余11页未读,继续阅读
相关推荐








maXZero
- 粉丝: 32
 我的内容管理
展开
我的内容管理
展开







最新资源
- 久度免费文件代存系统 v1.0:全技术领域源码分享
- 深入解析caseyjpaul.github.io的HTML结构
- HTML5视频播放器的实现与应用
- SSD7练习9完整答案解析
- 迅捷PDF完美转PPT技术:深度识别PDF内容
- 批量截取子网页工具:Python源码分享与使用指南
- Kotlin4You: 探索设计模式与架构概念
- 古典风格茶园茶叶酿制企业网站模板
- 多功能轻量级jquery tab选项卡插件使用教程
- 实现快速增量更新的jar包解决方案
- RabbitMQ消息队列安装及应用实战教程
- 简化操作:一键脚本调用截图工具使用指南
- XSJ流量积算仪控制与数显功能介绍
- Android平台下的AES加密与解密技术应用研究
- Место-响应式单页网站的项目实践
- Android完整聊天客户端演示与实践
