Python爬虫实战:X房网二手房信息抓取与MySQL存储
100 浏览量
更新于2024-08-29
收藏 332KB PDF 举报
"本文主要介绍了如何使用Python进行网络爬虫,以X房网的二手房信息为例,涵盖了爬取步骤、URL分析、HTML解析以及XPath语句的使用,并提及了数据存储到MySQL数据库的方法。"
在Python爬虫实践中,案例3讲述了如何从X房网抓取特定城市和小区的二手房信息。首先,我们需要理解URL的结构,这是爬虫定位网页的基础。对于不同的城市,URL通常以该城市的拼音缩写开头,例如南京的URL以"nj"表示,马鞍山的URL以"mas"表示。通过这种方式,我们可以构造出目标城市的URL。
接着,要获取特定小区的信息,URL中会有小区名称的编码形式。以"rs"开头,后面跟着小区名称的二进制编码。可以使用JavaScript的`decodeURI()`函数来解码这些URL,从而获取实际的小区名称,如"钢城花园"。
至于不同页面的URL,通常会在某个特定的标识符后加上页码,如"pg2"或"pg3",表示第2页或第3页。这样,我们可以通过更改页码来遍历所有页面的数据。
在爬取过程中,我们需要研究HTML页面的结构,找出包含所需信息的部分。XPath是一种强大的XML和HTML路径语言,用于选取节点。在X房网的案例中,可能需要用到XPath来选取房源的价格、面积、户型等关键信息。例如,使用XPath语句`//div[@class='info']`可能可以定位到包含房源详细信息的元素。
编写好XPath语句后,就可以开始编写Python代码了。一般会使用requests库来发送HTTP请求,获取网页内容;BeautifulSoup或者lxml库来解析HTML,提取所需数据。在Python代码中,使用`input()`函数接收用户输入的城市名、小区名称和页数,然后根据这些参数动态构造URL。
最后一步是将爬取到的数据存储到MySQL数据库。Python的pymysql库可以帮助我们连接数据库,执行SQL语句进行插入操作。确保在爬虫程序中处理好异常,避免因网络问题或数据库错误导致程序中断。
在MySQL中,我们可以编写查询语句,根据用户的需求,如价格范围、面积大小等条件,检索已存储的二手房数据。
这个案例不仅复习了Python爬虫的基本流程,还涉及到URL解析、HTML解析、XPath的运用以及数据库操作等多方面技能,对于提升爬虫开发能力非常有帮助。在实际应用中,还需要考虑反爬策略、数据清洗和持久化等问题,以确保爬虫的稳定性和数据的准确性。
利用利用pyhton爬虫爬虫(案例案例3)–X房网的小房子们房网的小房子们
写了个小案例,顺便复习一下以前学的知识点。
PS:复试之前绝不写爬虫案例了(对于现在的我来说,费脑又花时间),再写我吃XX.
文章目录文章目录爬取爬取X房网二手房信息爬取步骤房网二手房信息爬取步骤URL特征查看特征查看HTML页面源代码页面源代码Xpath语句开始敲语句开始敲python代码代码mysql数据查询数据查询
爬取爬取X房网二手房信息房网二手房信息
要求要求:由用户输入需要的城市名、小区名称和页数,爬取相关信息,再将结果存入mysql
备注备注:用input方法输入城市名称,小区名称和页数。
爬取步骤爬取步骤
查看URL特征
研究HTML页面结构
编写xpath语句
敲python代码(将数据存入数据库)
在mysql中按条件查询数据
URL特征特征
①不同城市URL地址特征
南京二手房URL:
https://nj.lianjia.com/ershoufang/
马鞍山二手房URL:
https://mas.lianjia.com/ershoufang/
可以看到不同城市的url特征非常明显,比如南京的拼音首字母为nj,再看看它的URL.特征显而易见。
②不同小区URL地址特征
珍珠园二手房URL:
https://mas.lianjia.com/ershoufang/rs%E7%8F%8D%E7%8F%A0%E5%9B%AD/
钢城花园二手房URL:
https://mas.lianjia.com/ershoufang/rs%E9%92%A2%E5%9F%8E%E8%8A%B1%E5%9B%AD/
我们判断rs后是小区名称的二进制形式,我们解码试试:
输入:decodeURI('https://mas.lianjia.com/ershoufang/rs%E9%92%A2%E5%9F%8E%E8%8A%B1%E5%9B%AD/')
输出:"https://mas.lianjia.com/ershoufang/rs钢城花园/"
嗯!判断正确呢。
③不同页面URL地址特征
钢城花园二手房第2页URL:
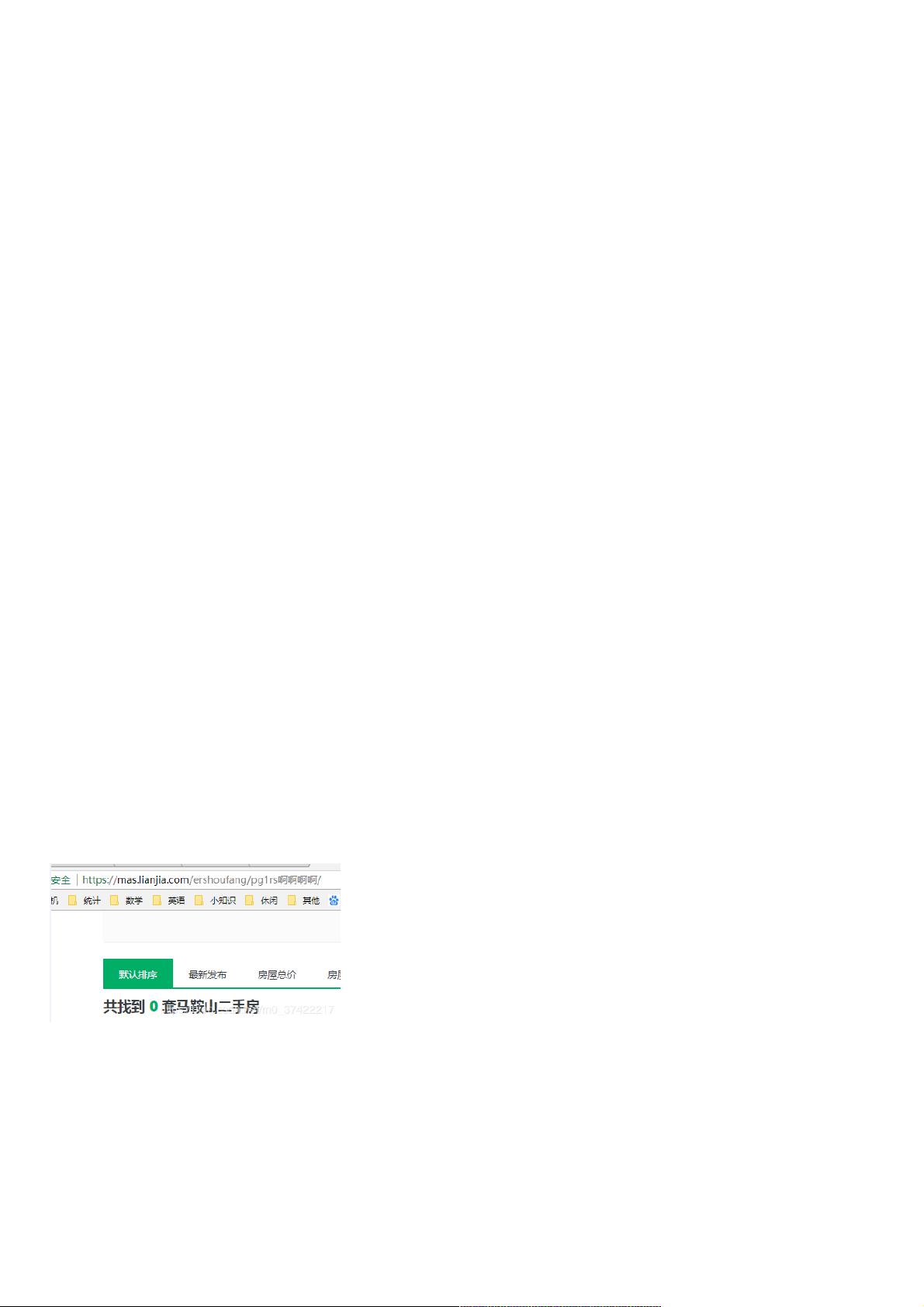
https://mas.lianjia.com/ershoufang/pg2rs%E9%92%A2%E5%9F%8E%E8%8A%B1%E5%9B%AD/
钢城花园二手房第3页URL:
https://mas.lianjia.com/ershoufang/pg3rs%E9%92%A2%E5%9F%8E%E8%8A%B1%E5%9B%AD/
我们判断pgk代表第k页。
值得注意的是,如果我们在url中写入一个不存在的小区名,该网站,也会返回一个页面,但是不出意外的话,页面内没有二手房数据:
所以,我们在之后写python代码时要加一个判断。
查看查看HTML页面源代码页面源代码
我们打开页面的源代码:
下载后可阅读完整内容,剩余4页未读,立即下载
2023-09-11 上传
2018-06-28 上传
2021-01-20 上传
2023-03-14 上传
2021-07-01 上传
2020-12-24 上传
2016-01-12 上传
2016-01-13 上传
2024-03-27 上传

weixin_38571449
- 粉丝: 5
- 资源: 944
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
