Lucene源码解析:从原理到实践
需积分: 26 88 浏览量
更新于2024-07-24
收藏 4.73MB PDF 举报
"Lucene 原理与代码分析完整版"
Lucene 是一个高性能、全文本搜索库,它被广泛用于构建自定义搜索引擎或者在应用中实现文本搜索功能。这篇资料详细介绍了Lucene的原理与代码分析,虽然不是最新版本,但其核心机制大体不变,对于理解Lucene的工作原理依然十分有价值。
全文检索的基本原理是Lucene的核心所在。首先,索引是全文检索的基础,它将原始的非结构化文本转换为结构化的数据结构,以便于快速查找。索引中存储了文档的词汇信息,包括每个词在哪些文档中出现过以及在文档中的位置等。
索引的创建分为四个步骤:
1. 将原文档转化为Document对象,Document包含了文档的所有字段和内容。
2. 使用Tokenizer将文档内容切分成词元Token,这是词法分析的过程,它识别出有意义的词汇单元。
3. 通过LinguisticProcessor对词元进行语言相关的处理,如词形还原或词性标注。
4. 最后,Indexer将词元转换为Term,并建立字典和PostingList(文档倒排索引),其中字典按字母顺序排列,相同Term合并成链表。
搜索索引时,用户输入的查询语句会经过类似的处理:
1. 词法分析、语法分析和语言处理,确保查询语句被正确解析。
2. 搜索引擎根据处理后的查询与索引进行匹配,找到包含所有查询词的文档。
3. 计算文档与查询的相关性,通常是通过Term权重和向量空间模型(VSM)来完成,权重考虑了词频、位置等因素。
4. 最后,按照相关性对搜索结果进行排序,返回给用户。
Lucene的总体架构包括多个组件,如Analyzer用于文本分析,IndexWriter负责索引的创建和更新,Searcher用于执行查询,Reader提供对索引的读取等。此外,Lucene的索引文件格式包括了一系列的基本概念、类型和规则,如前缀后缀规则、差值规则和或然跟随规则,这些都是为了优化磁盘存储和检索效率。
代码分析篇将深入到Lucene的源码层面,解释这些组件的实现细节,帮助开发者了解如何通过编程接口来操作Lucene,实现自定义的搜索功能。
这份资源提供了全面的Lucene原理介绍和源码分析,对于想要深入理解Lucene并开发相关应用的开发者来说是一份宝贵的参考资料。

16
到相同的转换。
语言处理组件(linguistic processor)的结果称为词(Term)。
在我们的例子中,经过语言处理,得到的词(Term)如下:
“student”,“allow”,“go”,“their”,“friend”,“allow”,“drink”,“beer”,“my”,“friend”,“jerry”,
“go”,“school”,“see”,“his”,“student”,“find”,“them”,“drink”,“allow”。
也正是因为有语言处理的步骤,才能使搜索 drove,而 drive 也能被搜索出来。
第四步
第四步第四步
第四步:
::
:将得到的词
将得到的词将得到的词
将得到的词(Term)传给索引组件
传给索引组件传给索引组件
传给索引组件(Indexer)。
。。
。
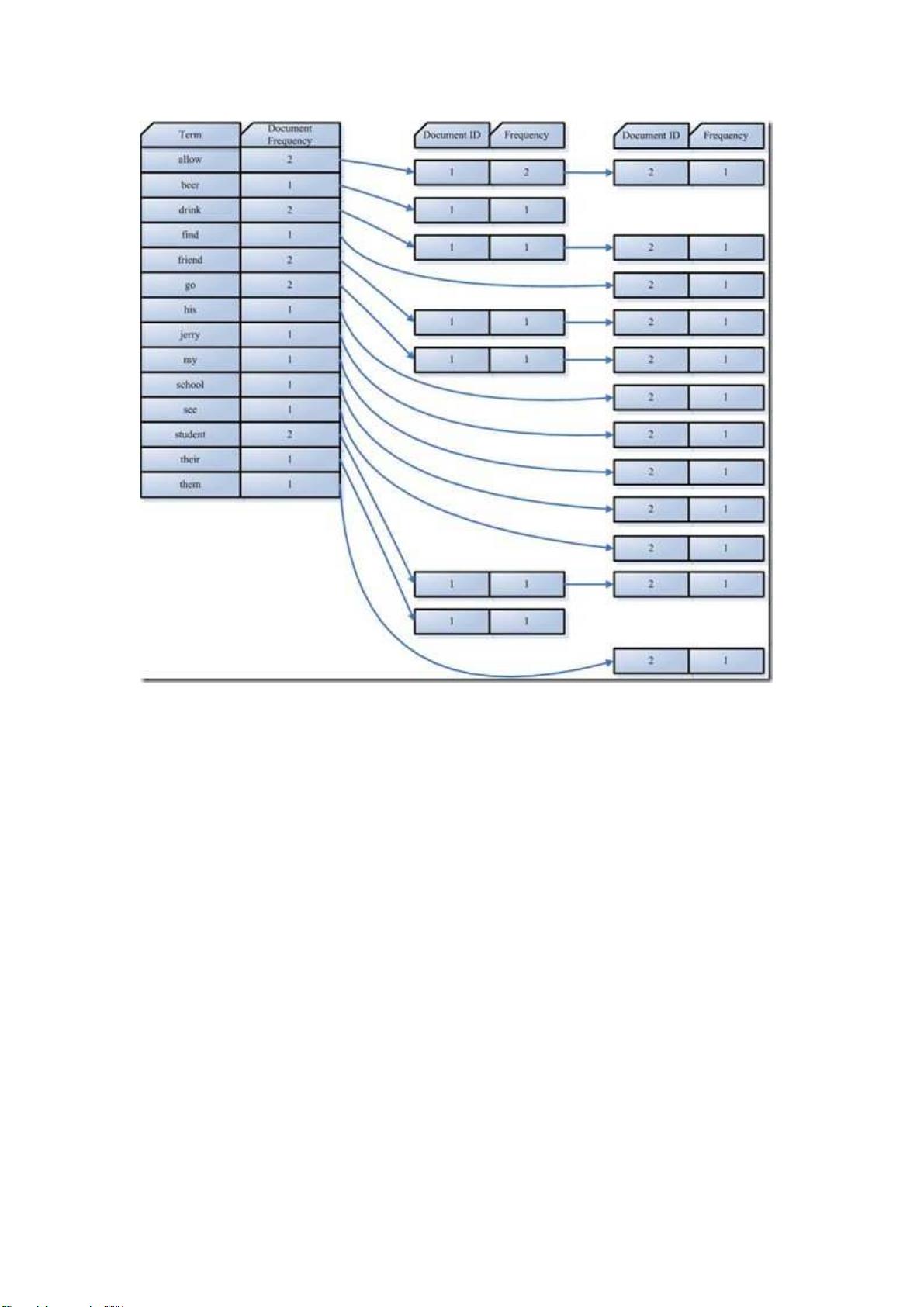
索引组件(Indexer)主要做以下几件事情:
1. 利用得到的词
利用得到的词利用得到的词
利用得到的词(Term)创建一个字典
创建一个字典创建一个字典
创建一个字典。
。。
。
在我们的例子中字典如下:
Term Document ID
student 1
allow 1
go 1
their 1
friend 1
allow 1
drink 1
beer 1
my 2
friend 2


剩余526页未读,继续阅读
2012-11-04 上传
2010-11-17 上传
2018-04-19 上传
2022-08-04 上传
2024-10-18 上传
2024-10-18 上传

孙晓飞
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 磁性吸附笔筒设计创新,行业文档精选
- Java Swing实现的俄罗斯方块游戏代码分享
- 骨折生长的二维与三维模型比较分析
- 水彩花卉与羽毛无缝背景矢量素材
- 设计一种高效的袋料分离装置
- 探索4.20图包.zip的奥秘
- RabbitMQ 3.7.x延时消息交换插件安装与操作指南
- 解决NLTK下载停用词失败的问题
- 多系统平台的并行处理技术研究
- Jekyll项目实战:网页设计作业的入门练习
- discord.js v13按钮分页包实现教程与应用
- SpringBoot与Uniapp结合开发短视频APP实战教程
- Tensorflow学习笔记深度解析:人工智能实践指南
- 无服务器部署管理器:防止错误部署AWS帐户
- 医疗图标矢量素材合集:扁平风格16图标(PNG/EPS/PSD)
- 人工智能基础课程汇报PPT模板下载
