Apache Flume:高效日志采集系统
需积分: 10 128 浏览量
更新于2024-07-09
收藏 1.1MB PDF 举报
"本章详细介绍了Apache Flume在Hadoop大数据平台中的应用,作为数据采集的重要工具,Flume提供了一种分布式、高可靠且高可用的解决方案,用于收集、聚合和传输大规模日志数据。Flume由Cloudera公司发起,现已成为Apache软件基金会的顶级项目。它使用Java实现,内置事务机制确保数据传输的可靠性。Flume包含Event、Agent、Source、Channel和Sink等核心概念,其中Event是基本的消息单位,Agent是工作在JVM进程中的转发实体,Source从外部获取数据并放入Channel,Channel作为中间缓存,Sink则负责将数据写入目标存储。Flume支持多种架构模型,包括单Agent、多Agent、多路数据流和Sink组数据流模型,适应不同场景的需求。"
在Hadoop大数据处理中,数据采集是基础步骤,Apache Flume作为一个强大的工具,被广泛应用于日志数据的采集。Flume的设计目标是有效地处理海量的日志数据,将这些数据从分散的数据源集中收集到统一的数据中心,便于后续分析和处理。其设计理念包括分布式的部署方式,确保即使在部分节点故障时仍能保持服务的连续性;高可靠性则通过事务机制来保证,使得数据在传输过程中不会丢失;高可用性体现在Flume可以通过配置多个Agent和Sink来构建冗余和备份,以防止单点故障。
Flume的核心组成部分包括以下几个关键概念:
1. **Event**: Event是Flume处理的基本单元,由header和body两部分构成,header存储元数据,body则承载实际的数据内容。
2. **Agent**: Agent是Flume的运行实例,它包含了Source、Channel和Sink。每个Agent可以独立运行,处理一部分数据流任务。
3. **Source**: Source是从外部数据源接收Event的组件,例如网络日志服务器,它可以监听特定端口或者文件,当新的日志数据产生时,将其转化为Event并写入Channel。
4. **Channel**: Channel是一个临时的、可靠的缓冲区,用于存储由Source读入的Event,直到Sink成功处理这些数据。常见的Channel类型有Memory Channel(内存存储)和File Channel(文件存储)。
5. **Sink**: Sink负责从Channel取出Event并将其发送到最终目的地,如HDFS、HBase或日志服务器等。它可以根据需要进行数据的格式转换和过滤。
Flume提供了四种主要的数据流模型架构:
- **单Agent数据流模型**: 在简单场景下,一个Agent可以完成全部采集、处理和传输任务。
- **多Agent数据流模型**: 当数据源分布在不同位置,或者需要进行复杂的数据处理时,可以使用多个Agent协同工作。
- **多路数据流模型**: 允许一个Source向多个Sink发送数据,实现数据的分发。
- **Sink组数据流模型**: 一组Sink共享同一个Channel,提供容错能力,如果某个Sink失败,数据可以被其他Sink接续处理。
这些架构模型的灵活组合使得Flume能够应对各种复杂的日志数据采集需求。在Hadoop 3.x大数据平台上,Flume是构建高效数据管道的关键组件,它简化了日志数据的收集流程,提高了大数据处理的效率和质量。

Hadoop 3.X 大数据平台技术与应用开发
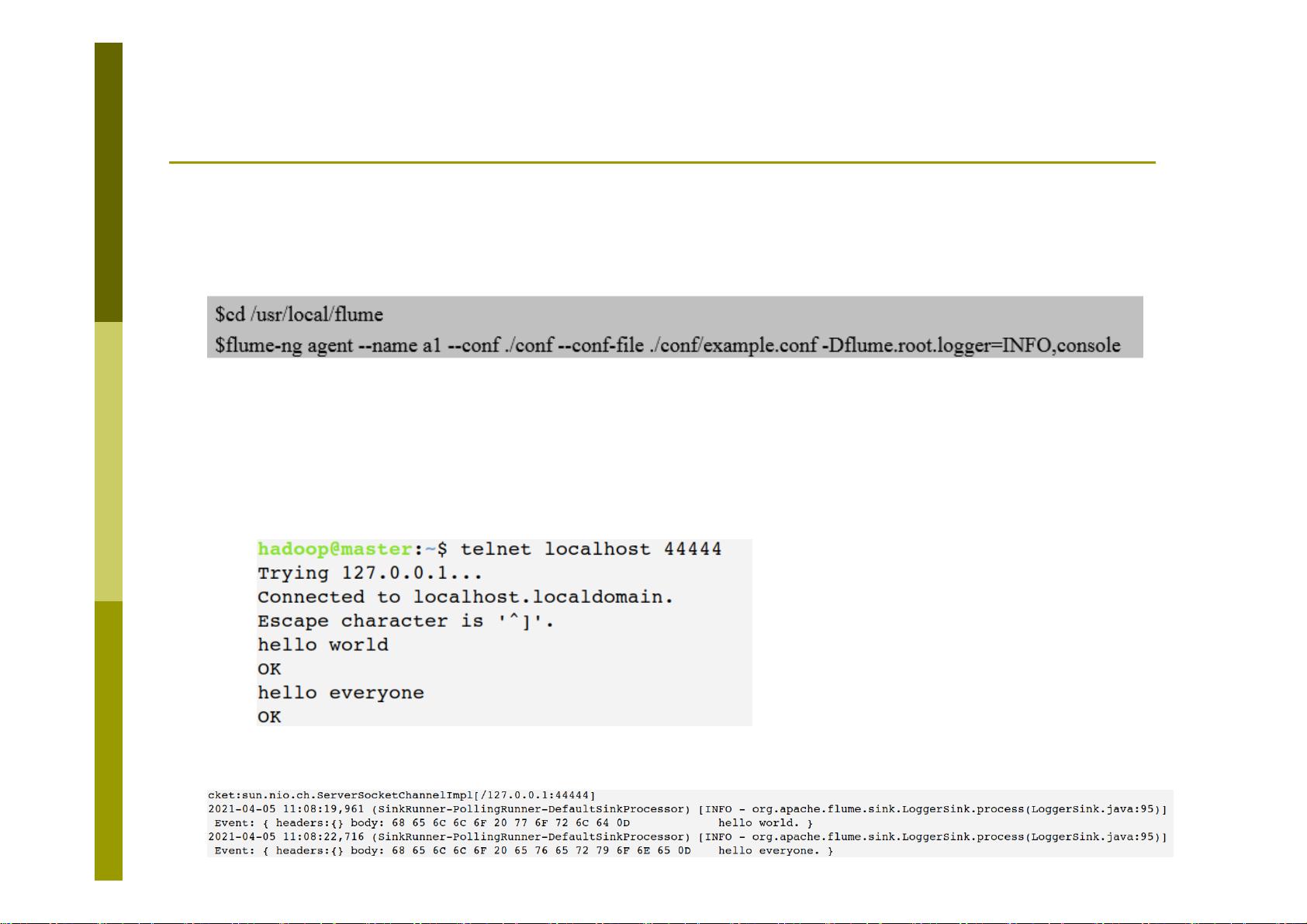
8.2 Flume安装与配置
安装Flume
(5)修改flume-env.sh配置文件
$cd /usr/local/flume/conf
$cp ./flume-env.sh.template ./flume-env.sh
$gedit ./flume-env.sh
写入下列内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_121


剩余83页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-03-12 上传
2021-12-09 上传
2022-11-11 上传
2024-04-09 上传
2022-10-28 上传
2021-11-20 上传

oracle_teacher
- 粉丝: 1
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
