EM算法详解:非完整数据的参数估计利器
下载需积分: 50 | DOCX格式 | 58KB |
更新于2024-07-18
| 100 浏览量 | 举报
**算法原理**
EM(Expectation-Maximization)算法,由Dempster、Laird和Rubin在1977年提出,主要用于处理非完整或缺失数据的参数极大似然估计。该算法的特点是通过迭代的方式在存在隐性变量的模型中估计参数,即使数据不完全,也能找到最接近真实分布的参数值。其核心思想可以比喻为食堂分菜的例子:通过不断调整分配,使得两个碗中的菜尽可能平均。
**算法推导与Jensen不等式**
在算法推导过程中,关键概念之一是Jensen不等式,它是优化理论中的一个基础工具。Jensen不等式表明,如果一个函数f满足凸性条件,即其一阶偏导数存在且二阶偏导数非负(Hessian矩阵半正定),则函数关于其均值的函数值不会小于函数本身。在EM算法中,这个特性帮助我们确保在每次迭代过程中,通过期望(E)步骤得到的参数估计会导向全局最优解。
**应用领域**
EM算法在机器学习和数据挖掘中广泛应用,特别是在数据聚类(如Gaussian Mixture Models,GMM)中,通过处理缺失数据,提升模型的准确性和鲁棒性。在GMM中,算法重新审视了混合高斯模型的参数估计问题,特别是当观测数据包含未观测到的隐性成分时。
**Python实现**
学习EM算法时,Python是一个很好的实践平台。Python中有许多库,如scikit-learn,提供了现成的GMM实现,初学者可以通过这些库理解并实现EM算法。从初始化分布参数开始,逐步进行E步(计算隐变量的期望)和M步(更新参数以最大化似然函数),通过反复迭代直至收敛。
**总结**
EM算法是解决含有隐变量问题的重要工具,其在实际应用中的价值在于能够处理缺失数据,提高模型的适应性。学习过程中,理解Jensen不等式的直观解释以及算法的迭代过程至关重要。通过Python编程实践,能够加深对该算法的理解和掌握。
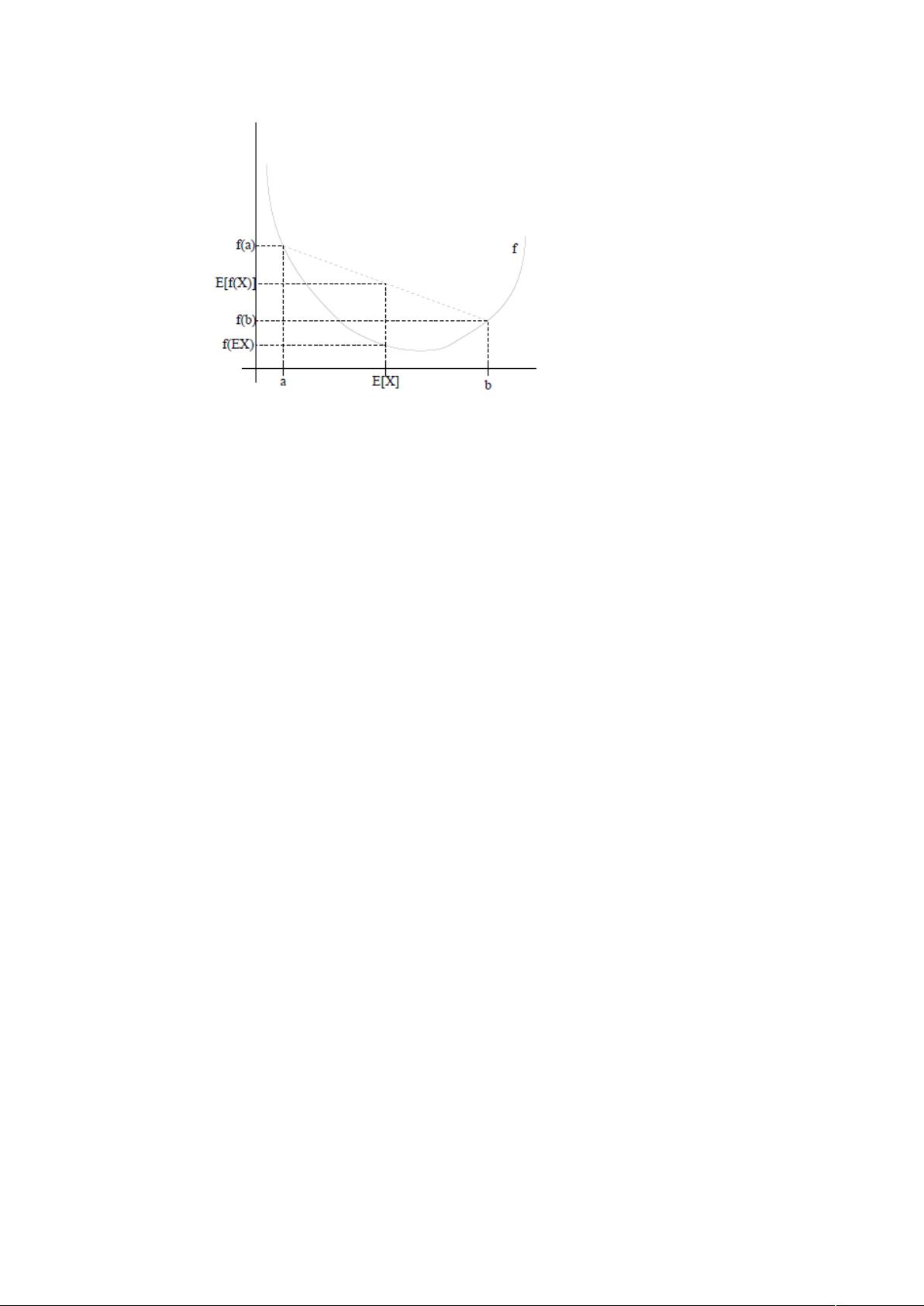
图中,实线 f 是凸函数,X 是随机变量,有 0.5 的概率是 a,有 0.5 的概
率是 b。(就像掷硬币一样)。X 的期望值就是 a 和 b 的中值了,图中可以看
到
E [f (X )]≥ f (EX )
成立。
当 f 是(严格)凹函数当且仅当-f 是(严格)凸函数。
Jensen 不等式应用于凹函数时,不等号方向反向,也就是
E [f (X )]≤ f (EX )
。
2. EM 算法
给定的训练样本是{x
(1)
,…,x
(m)
},样例间独立,我们想找到每个样例隐含
的类别 z,能使得 p(x,z)最大。p(x,z)的最大似然估计如下:
L
(
θ
)
=
∑
i=1
m
log p
(
x ;θ
)
¿
∑
i=1
m
log
∑
z
p(x , z;θ)
第一步是对极大似然取对数,第二步是对每个样例的每个可能类别 z 求联
合分布概率和。但是直接求
θ
一般比较困难,因为有隐藏变量 z 存在,但是一般
确定了 z 后,求解就容易了。
剩余18页未读,继续阅读
相关推荐






GDMU_Dong
- 粉丝: 67
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- kindergarten
- 基于VB实现ACCESS汽车租凭管理系统(论文+系统).rar
- 软件测试工程师面试题及答案(全)文档集
- 最好用的JAVA代码混淆工具proguard-7.0.0.zip
- mixlib-cli:用于创建命令行应用程序的混合-为参数说明和处理提供了简单的DSL
- Flutter_Localizations:一个示例flutter应用程序,演示了如何使用本地化来支持2种语言
- 自平衡智能小车第二版-电路方案
- zstack.zip
- 基于MATLAB的遗传算法工具箱(51个MATLAB工具+源代码).zip
- Weights-Initialization-in-Nueral-Networks:神经网络中的权重初始化技术
- 20200917-头豹研究院-汽车应用系列深度研究:2019年中国经营性汽车租赁行业应用概览.rar
- CICD_automation
- 变频器 SINAMICS G120D,配备控制单元 CU240D-2.zip
- 耶鲁大学人脸识别数据集
- sinatra-book:正式回购到sinatrasinatra-book教程+食谱
- DFRobot_DS323X
