Apache Spark 2.4新特性解析:深度学习集成与性能提升
158 浏览量
更新于2024-08-28
收藏 484KB PDF 举报
"Apache Spark 2.4是2.x系列的第五个版本,主要特性包括新的调度模型、增强的Spark SQL高阶函数、原生AVRO数据源、PySpark的热切评估模式、Spark on K8S对PySpark和R的支持、Structured Streaming的改进以及性能优化等。"
Apache Spark 2.4版本的发布标志着这个大数据处理框架的又一次重大更新。其中,新引入的调度模型—— Barrier Scheduling,是针对分布式深度学习训练的一项重要改进。这一模型允许用户将训练过程更好地整合到Spark的stage架构中,极大地简化了复杂的分布式训练工作流程,使得数据科学家可以更加高效地利用Spark进行大规模机器学习任务。
在数据处理能力方面,Spark SQL得到了显著提升。新增的35个高阶函数扩展了对数组和映射类型的操作,使得在SQL查询中处理复杂数据结构变得更加便捷。这对于数据分析人员来说是一个巨大的福音,因为他们现在可以更方便地进行数据清洗、转换和建模工作。
此外,Spark 2.4引入了基于Databricks的spark-avro模块,提供了原生的AVRO数据源支持。AVRO是一种流行的序列化格式,广泛应用于数据存储和交换,这项改进意味着用户可以直接在Spark中高效地读写AVRO格式的数据,无需额外的库或转换步骤。
对于Python开发者,PySpark新增了热切的评估模式(eager evaluation mode)。这一模式特别适合教学和调试,因为它能立即执行所有操作,帮助开发者快速理解代码的行为并找出潜在问题。
在Spark运行于Kubernetes(K8S)环境时,2.4版本开始支持PySpark和R,同时提供了客户端模式(client mode)。这使得K8S上的数据科学工作流程更加灵活,用户可以在熟悉的开发环境中进行工作,而无需关心底层集群的管理。
Structured Streaming,Spark的流处理组件,也在2.4中得到了增强。例如,它支持了有状态操作符的连续处理,这使得在实时数据流处理中处理和维护状态数据成为可能,这对于构建复杂的实时分析应用至关重要。
Apache Spark 2.4还针对内置数据源进行了性能优化,如Parquet文件格式的嵌套模式修剪(schema pruning),这可以减少不必要的数据读取,提高查询速度。此外,Spark 2.4也开始支持Scala 2.12,以适应不断发展的编程语言环境。
Apache Spark 2.4通过提供更强大的调度、更丰富的SQL功能、优化的性能和更广泛的语言支持,进一步巩固了其作为大数据处理和分析首选平台的地位。这些改进不仅提升了开发者的效率,也增强了Spark在实时和批处理场景中的竞争力。
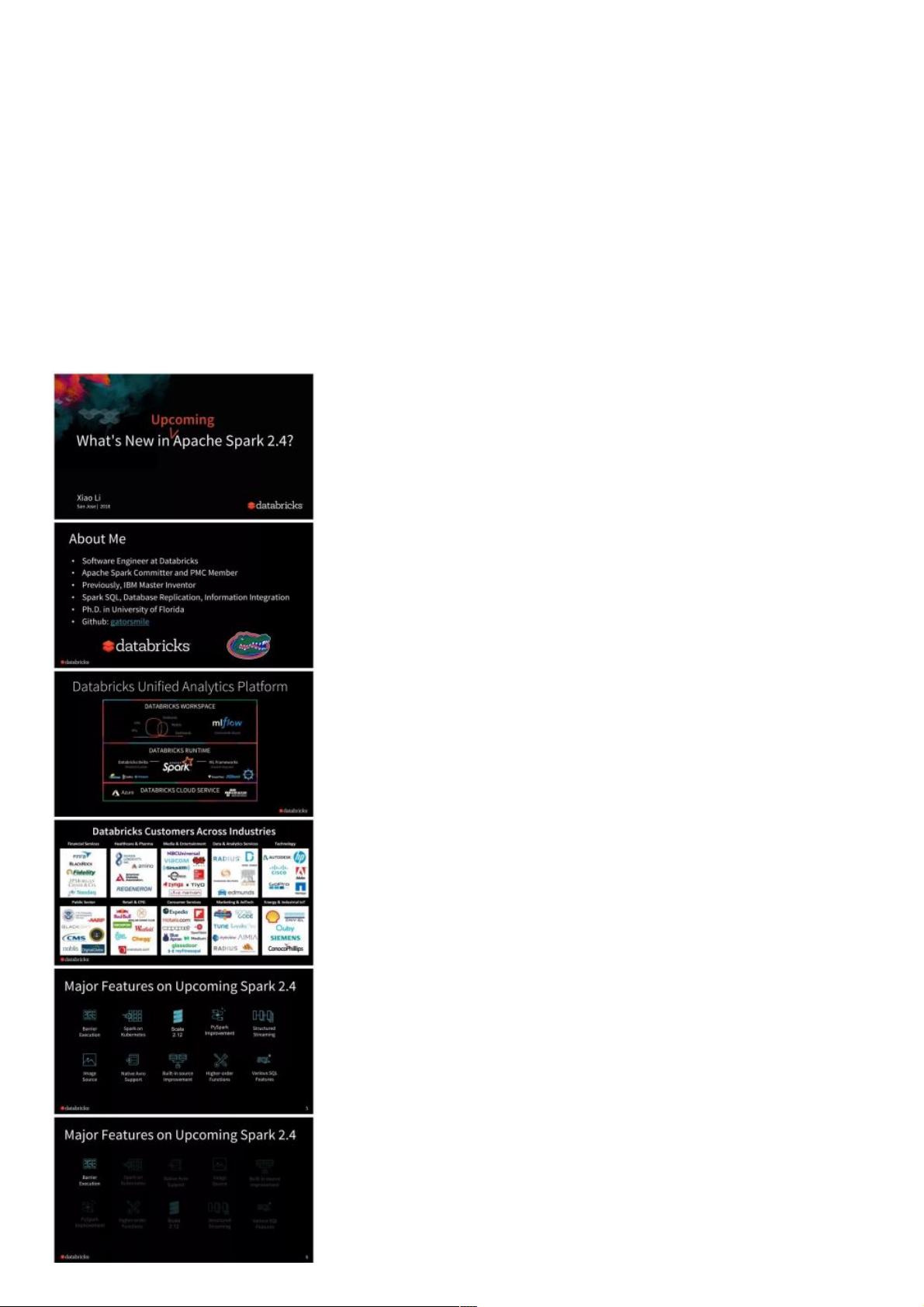
2018即将推出的即将推出的Apache Spark 2.4都有哪些新功能都有哪些新功能
本文来自于2018年09月19日在 Adobe Systems Inc 举行的Apache Spark Meetup。
即将发布的 Apache Spark 2.4 版本是 2.x 系列的第五个版本。 本文对Apache Spark 2.4 的主要功能和增强功能进行了概述。
新的调度模型(Barrier Scheduling),使用户能够将分布式深度学习训练恰当地嵌入到 Spark 的 stage 中,以简化分布式训
练工作流程。
添加了35个高阶函数,用于在 Spark SQL 中操作数组/map。
新增一个新的基于 Databricks 的 spark-avro 模块的原生 AVRO 数据源。
PySpark 还为教学和可调试性的所有操作引入了热切的评估模式(eager evaluation mode)。
Spark on K8S 支持 PySpark 和 R ,支持客户端模式(client-mode)。
Structured Streaming 的各种增强功能。 例如,连续处理(continuous processing)中的有状态操作符。
内置数据源的各种性能改进。 例如,Parquet 嵌套模式修剪(schema pruning)。
支持 Scala 2.12。
点击 示说网 ,即可下载此PPT。
下载后可阅读完整内容,剩余6页未读,立即下载
2023-09-09 上传
110 浏览量
2019-05-09 上传
200 浏览量
326 浏览量
211 浏览量
141 浏览量
118 浏览量
263 浏览量

weixin_38613681
- 粉丝: 3
- 资源: 933
 我的内容管理
展开
我的内容管理
展开







最新资源
- jungle-rails:丛林项目
- piazza-api:Piazza内部API的非官方客户端
- hadoopstu.7z
- 2014学校德育工作年度计划
- matlab的slam代码-openslam_cekfslam:来自OpenSLAM.org的cekfslam存储库
- Zendi-crx插件
- svg.path:SVG路径对象和解析器
- 朱宏林.github.io
- Fivlytics - Fiverr Seller Assistant-crx插件
- 基于代码变更分析的过时需求识别
- tomcat windwos 7\8
- Hot-Restaurant-App
- VB.net 2010 读写txt文件
- pcdoctor
- java版sm4源码-spring-security-family:关于如何在微服务系统中使用spring-security的demo&分享
- iiam:IIAM App正在开发中!
