图模型与机器学习:概率表示与条件独立性
需积分: 10 98 浏览量
更新于2024-07-17
收藏 3.82MB PDF 举报
《机器学习与数据挖掘百科全书(第二版)》中文版part4深入探讨了图示模型这一关键概念,这些模型在信息建模、概率推理以及数据分析中起着至关重要的作用。图1展示了图形定义中的三个关键元素:产品规则(定义1),即任何概率分布都可以表示为一个图形模型,其中各变量之间的依赖关系通过边相连;条件独立性(定义3),当两个变量XA和XB在给定XC的条件下相互独立时,表示为XA?XB|XC,意味着它们的联合概率可以分解为各自与XC的条件概率的乘积。
图示模型可以是有向的(如图2左图所示),在这种情况下,箭头指示了因果关系的方向,例如A影响B但反之不成立。无向模型(图2右图)则表示的是更平等的关联,没有方向性。这些模型用于捕捉变量之间的复杂关系,并且在处理高维数据时尤其有用,因为它们允许我们对数据的结构进行抽象,从而高效地计算如特定结果的概率或最可能结果等重要统计特性。
例如,对于一个多变量概率分布,我们可以用向量表示每个随机变量及其取值,如XD = {X1, X2, ..., XN}。通过图的节点和边,我们可以直观地表示出变量间的依赖程度,这对于推断隐含的条件概率以及执行变量的边际化(定义2)至关重要。边际化是指计算单个变量的概率分布,而无需考虑其他变量的值,这对于预测和决策分析非常实用。
在实际应用中,图示模型在诸如计算机视觉中的图像分类、模式识别中的特征选择、经济学中的市场行为分析以及社会科学中的社会网络分析等领域都发挥着核心作用。通过利用分布的结构,我们可以设计高效的算法,如利用分配律将复杂的概率表达式分解为低维度的因子,以便于计算和优化。
《机器学习与数据挖掘百科全书》的这部分内容提供了一个全面的框架,帮助读者理解如何构建和使用图示模型来处理现代大数据背景下的各种问题,并利用这些模型来增强预测性能和解释性。通过掌握这一理论和实践工具,数据分析师和机器学习工程师能够更有效地探索和利用数据中的潜在规律。
600
Greedy Search Approach of Graph Mining
j
— j
j C C
图挖掘的贪婪搜索方法,图3图挖掘的贪婪搜索方法
的迭代应用产生了分层的概念聚类 -
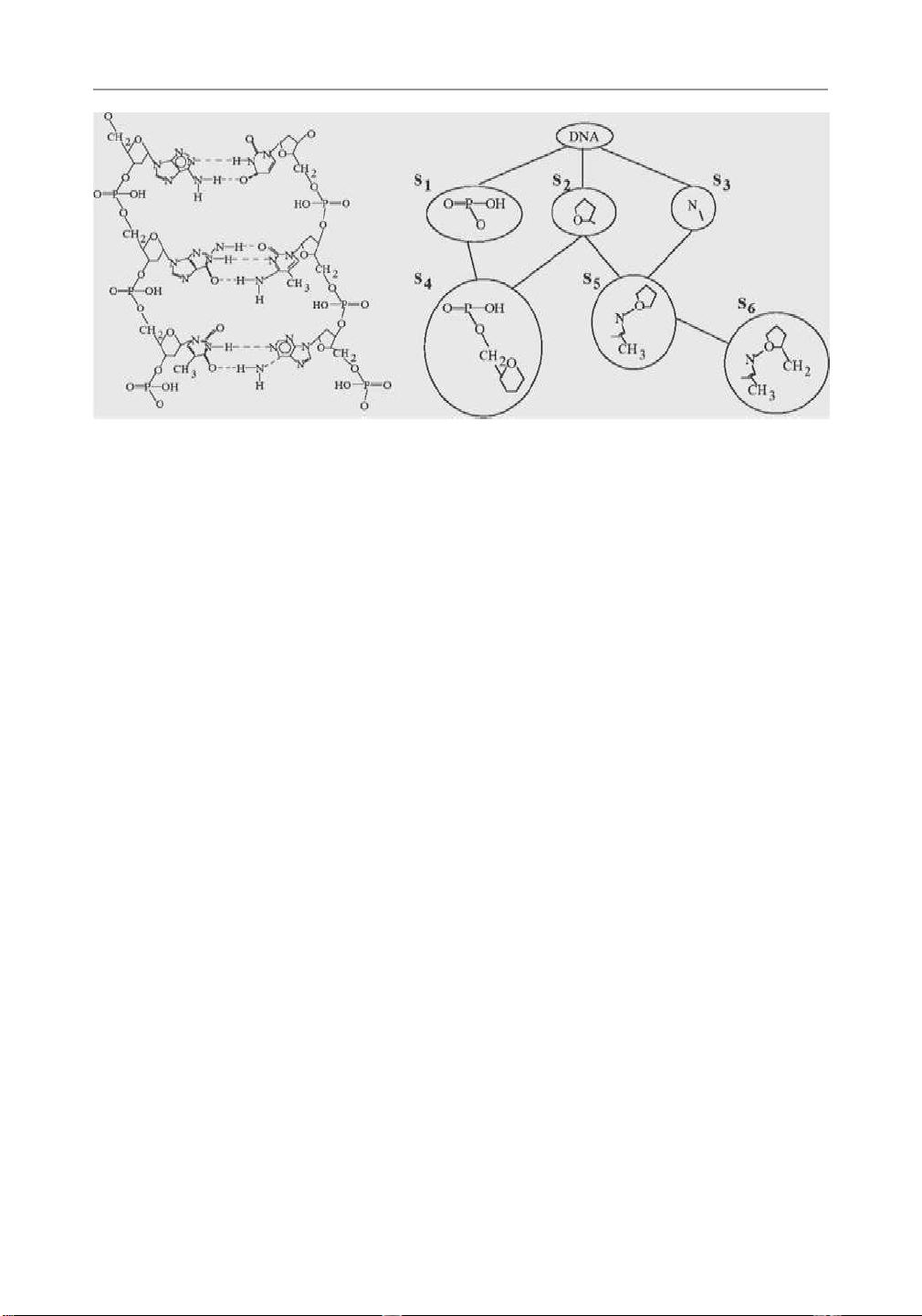
在右侧给出一个输入图表,表示左侧描绘的DNA结构
部分
反面例子。
如果
IG /
表示图
G
的描述长度
(以位为单位),则
IG S /
表示由子图
S
压缩的图
G
的描述长度,
然后可以寻找最小化
I.GC S /
IS / IG- /
IG-S /
的
S
,其
中最后两个项表示负的部分图表被子图
正确压缩。
这种方法将引导搜索更大的
子图,这些子图描述了正例,但不是负
面例子。
最后,这个过程可以用集合覆盖的方法迭
代,以学习析取假设。 如果使用错误度量,
那么包含学习子图的任何正例将从后续迭代
中删除。 如果使用信息理论度量,则正例和
负例中的学习子图的实例(甚至每个例子的
多个实例)被压缩为单个顶点。 请注意,压
缩是有损的,也就是说,压缩图中没有足够
的信息来了解实例如何连接到图的其余部分。
这种方法与学习一般模式的目标一致,而不
仅仅是压缩。
图形语法推理
在上述算法中,模式仅限于非递归结构。 为
了学习
子图图案,或可用作生成任意大图的构建块
的图案,需要学习图形图的能力。 图形语法
推断的关键是重叠结构的识别。 通过检查模
式的实例是否重叠,可以检测递归图形语法
生成的可能性。 如果一组实例由单个顶点重
叠,则可以提出递归节点替换图语法生成。
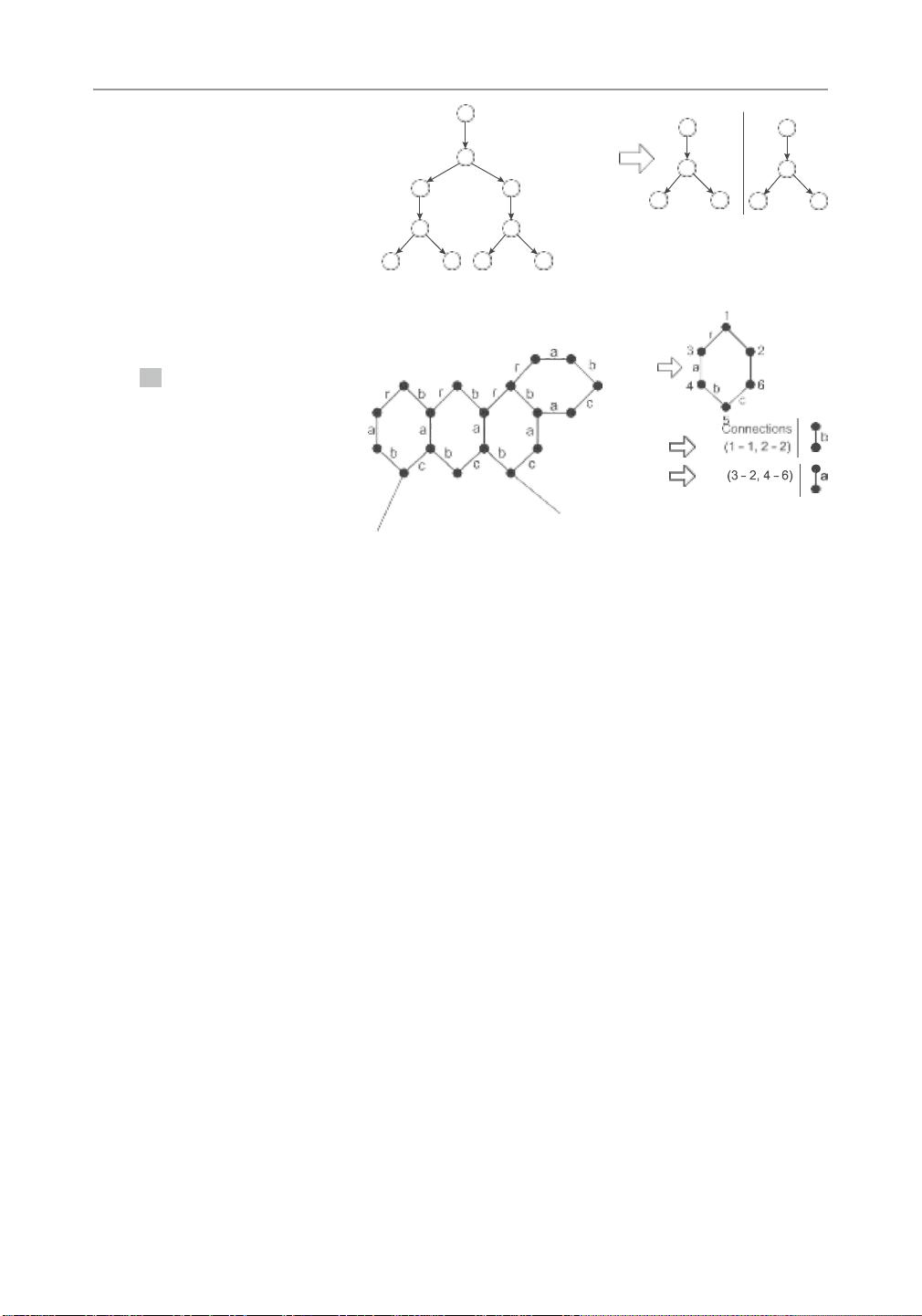
图4 显示了从简单的重复输入图(左)学习
的节点替换图语法(右)的示例。 输入图如
图4 所示由三个重叠的子结构组成。 根据实
例重叠的方式,还可以推断描述模式如何连
接到自身的连接指令。 例如,图4中的连接
指令表明图形可以通过将一个模式实例的顶
点1连接到另一个模式实例的顶点3或顶点4来
增长。
如果一组模式实例重叠
边缘,然后可以提出递归边缘替换图形语法
生成。 图5 显示了从输入图(左)学习的边
缘替换图语法(右)的示例。 连接说明描述
了图案如何通过标记为“a”的边缘或标记为“b”
的边缘连接。
除了包含递归模式之外,图挖掘的贪婪搜
索方法是



剩余203页未读,继续阅读
2019-01-25 上传
2019-01-25 上传
114 浏览量
2019-01-26 上传
2019-01-26 上传
2019-01-26 上传
2019-01-26 上传
2019-01-26 上传
2017-09-27 上传

changqingt27
- 粉丝: 0
- 资源: 21
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
