淘宝海量数据技术架构:从数据源到产品层解析
需积分: 10 32 浏览量
更新于2024-09-08
收藏 409KB DOCX 举报
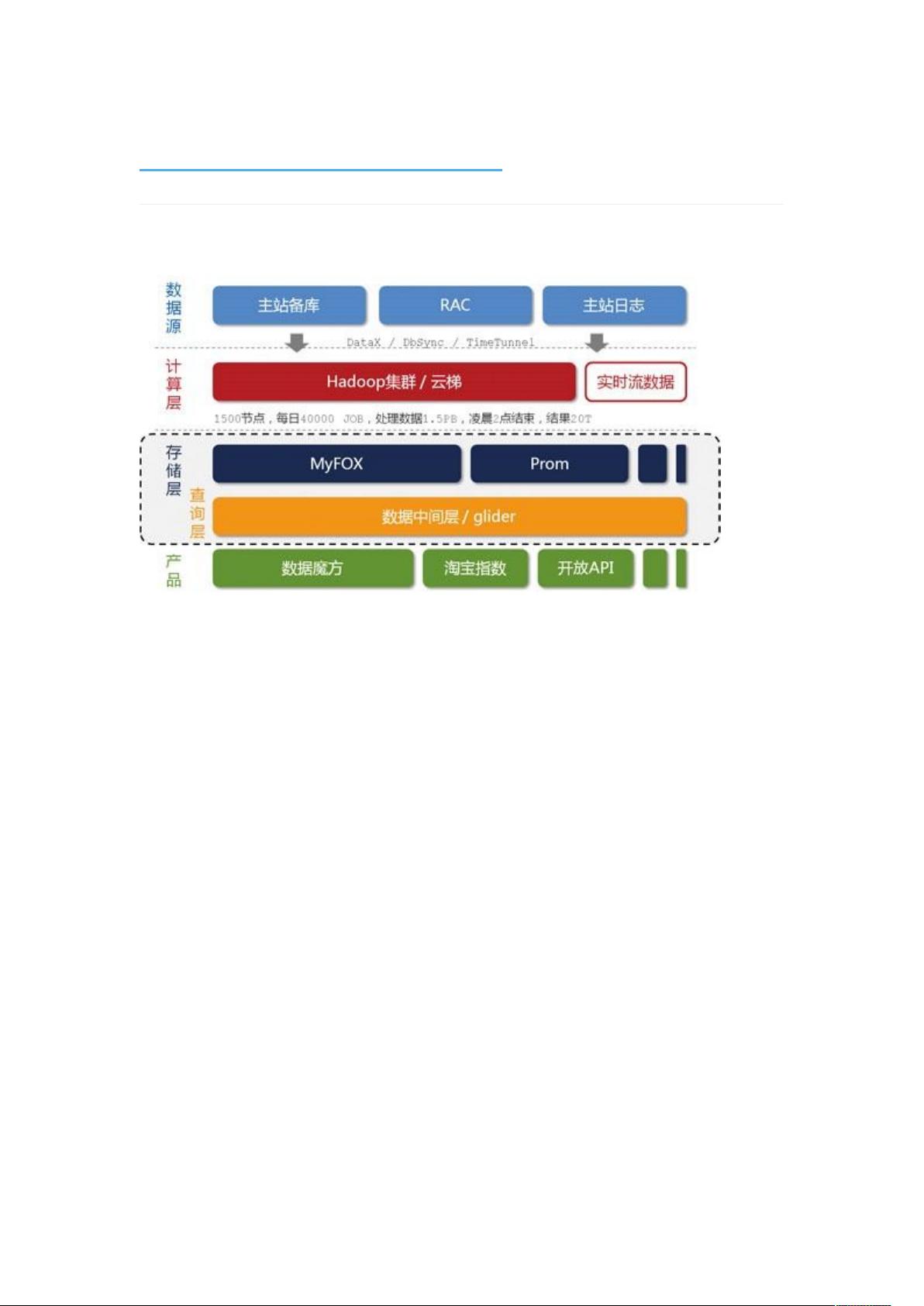
"阿里海量数据技术架构主要由数据源、计算层、存储层、查询层和产品层五部分构成,应对大数据处理需求。数据源包括用户、店铺、商品、交易数据库以及用户行为日志等。数据通过DataX、DbSync、Timetunnel传输到Hadoop集群‘云梯’进行MapReduce计算。对实效性要求高的数据,如搜索词统计,通过实时计算平台‘银河’处理,结果存储在NoSQL设备中。存储层包含MySQL分布式数据库MyFOX和HBase NoSQL存储集群Prom,以及第三方模块。为了解决异构存储对前端产品的影响,设计了数据中间层glider,提供RESTful接口。"
阿里海量数据技术架构的设计和实施是应对大规模电子商务平台如淘宝所面临的挑战的关键。首先,数据源是整个架构的基础,涵盖了从用户交互、店铺运营到商品交易等多个方面的数据库和日志数据,这些数据构成了数据分析的基石。接下来,数据传输组件如DataX、DbSync和Timetunnel扮演着关键角色,它们确保数据能实时或准实时地传输到计算层。
计算层的核心是拥有1500个节点的Hadoop集群“云梯”,处理大约40000个作业,对1.5PB的原始数据进行MapReduce计算,通常在凌晨两点前完成。这种离线计算模式适用于处理大量历史数据,但不适合对时效性有高要求的场景。
为了满足这类需求,阿里构建了实时计算平台“银河”。银河是一个分布式系统,接收实时消息,进行内存计算,并快速将结果写入NoSQL存储,如可能被前端产品调用的搜索词统计数据。然而,无论是“云梯”还是“银河”,它们都不适合直接提供实时查询服务,因为前者专注于离线计算,后者则需要处理复杂的集成问题。
因此,存储层成为关键,包括了基于MySQL的分布式关系型数据库MyFOX和基于HBase的NoSQL存储集群Prom,以及可能的第三方存储模块。存储层的多样性可能导致前端产品使用的复杂性增加,为此引入了数据中间层glider,它作为一个统一的接口,通过HTTP RESTful协议对外提供服务,简化了数据访问流程。
总结来说,阿里的海量数据技术架构是一种层次化的、灵活的解决方案,能够有效地处理和分析海量数据,同时满足不同业务场景的实时性和延迟性需求。通过定制化和分层设计,该架构能够适应不断变化的业务需求,确保数据的高效处理和利用,支撑起整个电商平台的智能决策和用户体验优化。
淘宝海量数据产品的技术架构
淘宝海量数据产品的技术架构是什么,又是如何应对双十一的海量访问的?先看图:
按照数据的流向来划分,我们把淘宝数据产品的技术架构分为五层(如图 1 所示),
分别是数据源、计算层、存储层、查询层和产品层。位于架构顶端的是我们的数据来
源层,这里有淘宝主站的用户、店铺、商品和交易等数据库,还有用户的浏览、搜索
等行为日志等。这一系列的数据是数据产品最原始的生命力所在。
在数据源层实时产生的数据,通过淘宝自主研发的数据传输组件 DataX、DbSync 和
Timetunnel 准实时地传输到一个有 1500 个节点的 Hadoop 集群上,这个集群我们称之
为“云梯”,是计算层的主要组成部分。在“云梯”上,我们每天有大约 40000 个作业对
1.5PB 的原始数据按照产品需求进行不同的 MapReduce 计算。这一计算过程通常都能
在凌晨两点之前完成。相对于前端产品看到的数据,这里的计算结果很可能是一个处
于中间状态的结果,这往往是在数据冗余与前端计算之间做了适当平衡的结果。
不得不提的是,一些对实效性要求很高的数据,例如针对搜索词的统计数据,我们希
望能尽快推送到数据产品前端。这种需求再采用“云梯”来计算效率将是比较低的,为此
我们做了流式数据的实时计算平台,称之为“银河”。“银河”也是一个分布式系统,它接
收来自 TimeTunnel 的实时消息,在内存中做实时计算,并把计算结果在尽可能短的时
间内刷新到 NoSQL 存储设备中,供前端产品调用。
容易理解,“云梯”或者“银河”并不适合直接向产品提供实时的数据查询服务。这是因为,
对于“云梯”来说,它的定位只是做离线计算的,无法支持较高的性能和并发需求;而对
下载后可阅读完整内容,剩余9页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-10-24 上传
2024-03-12 上传
2021-10-24 上传
2020-06-04 上传
2021-10-11 上传
2022-11-24 上传

lkys
- 粉丝: 11
- 资源: 51
 我的内容管理
展开
我的内容管理
展开







最新资源
- GEC2410B实验箱 linux实验
- 单片机的40个实验.pdf
- 一种基于编码的关联规则挖掘算法
- 有关数字地和模拟地分割的介绍.pdf
- 适合新手入门的C#中文教程
- 移动代理服务器MAS短信API2.2开发手册(.Net)
- 移动代理服务器MAS短信API2.2开发手册(DB接口)
- 基于事务相似矩阵的关联规则挖掘算法
- 组态王在楼宇监控的应用
- 分布式关联规则挖掘系统实现
- dynamips 报错及非正常现象的解决办法
- 英语完形填空的考试系统
- 演讲文本Come on in and sit in the aisles./ p6 u& j*
- PHPCMS 整站代码分析讲解
- VC++动态链接库编程深入浅出
- 高效使用JUnit(如何提升JUnit在Java开发中的价值)
