"基于DTW算法的数字语音识别实现原理与实例"
版权申诉
179 浏览量
更新于2024-03-09
收藏 323KB DOC 举报
本文主要介绍了基于DTW算法的语音识别原理与实现。首先以一个能够识别数字0-9的语音识别系统为例,阐述了基于DTW算法的特定人孤立词语音识别的基本原理和关键技术。文中详细讨论了语音端点检测方法、特征参数计算方法以及DTW算法的实现。最后给出了在Matlab下的编程方法和实验结果,结果显示该算法能够很好地识别特定人所说出的单词。
DTW算法,全称为Dynamic Time Warping,是一种用于测量两个序列之间的相似度的算法。在语音识别中,DTW算法可以用来计算语音信号之间的相似度,进而用于识别特定人所说出的单词。该算法的核心思想是通过动态规划的方式,找到两个序列之间的最佳匹配路径,从而计算它们之间的相似度。
在基于DTW算法的语音识别系统中,首先需要进行语音端点检测,以确定语音信号的起始和结束点。然后需要对语音信号进行特征参数的计算,常用的特征参数包括MFCC(Mel Frequency Cepstral Coefficients)和LPCC(Linear Prediction Cepstral Coefficients)。这些特征参数能够有效地表征语音信号的频谱特性,为后续的匹配过程提供必要的信息。
在DTW算法的实现过程中,需要计算两个序列之间的距离矩阵,并通过动态规划的方式找到最佳匹配路径。具体来说,就是通过计算每个序列中的各个点之间的距离,并将这些距离累积起来,然后寻找一条累积距离最小的路径作为最佳匹配路径。最后,根据最佳匹配路径的长度和累积距离,可以确定两个序列之间的相似度,进而实现语音识别的功能。
在实验部分,本文使用Matlab对DTW算法进行了编程实现,并进行了一系列的实验。实验结果表明,基于DTW算法的语音识别系统能够很好地识别特定人所说出的数字。这为基于DTW算法的语音识别系统的进一步研究和应用提供了可靠的基础。
总之,本文的研究内容涵盖了基于DTW算法的语音识别原理与实现过程,通过对语音端点检测、特征参数计算、DTW算法实现以及实验结果的详细讨论,揭示了DTW算法在语音识别领域的重要作用和应用前景。希望本文的研究成果能够为相关领域的研究和实践提供一定的借鉴和参考,并为语音识别技术的发展做出一定的贡献。
. . . .
常见的语音识别方法有动态时间归整技术(DTW)、矢量量化技术(VQ)、隐马尔可夫模
型 (HMM) 、 基 于 段 长 分 布 的 非 齐 次 隐 马 尔 可 夫 模 型 (DDBHMM) 和人 工 神 经 元 网 络
(ANN)。DTW 是较早的一种模式匹配和模型训练技术,它应用动态规划的思想成功解决了
语音信号特征参数序列比较时时长不等的难题,在孤立词语音识别中获得了良好性能。虽
然 HMM 模型和 ANN 在连续语音大词汇量语音识别系统优于 DTW,但由于 DTW 算法计
算量较少、无需前期的长期训练,也很容易将 DTW 算法移植到单片机、DSP 上实现语音
识别且能满足实时性要求,故其在孤立词语音识别系统中仍然得到了广泛的应用。本文将
通过能识别数字 0~9 的语音识别系统的实现过程详细阐述基于 DTW 算法的特定人孤立词
识别的相关原理和关键技术。
二、语音识别系统概述
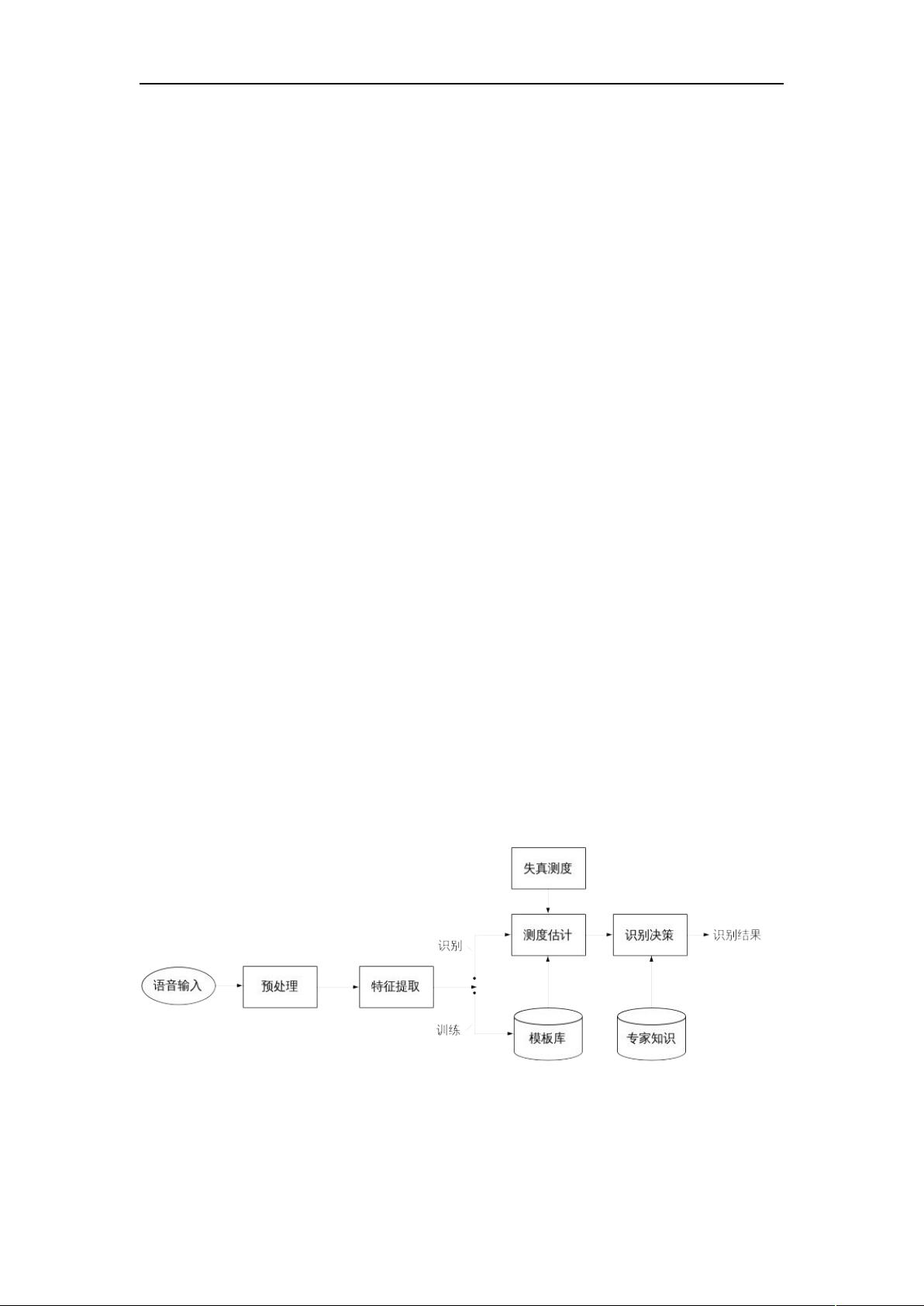
语音识别系统的典型原理框图如图 1-1 所示。从图中可以看出语音识别系统的本质就
是一种模式识别系统,它也包括特征提取、模式匹配、参考模式库等基本单元。由于语音
信号是一种典型的非平稳信号,加之呼吸气流、外部噪音、电流干扰等使得语音信号不能
直接用于提取特征,而要进行前期的预处理。预处理过程包括预滤波、采样和量化、分帧
加窗、预加重、端点检测等。经过预处理的语音数据就可以进行特征参数提取。在训练阶
段,将特征参数进行一定的处理之后,为每个词条得到一个模型,保存为模板库。在识别
阶段,语音信号经过相同的通道得到语音参数,生成测试模板,与参考模板进行匹配,将
匹配分数最高的参考模板作为识别结果。后续的处理过程还可能包括更高层次的词法、句
法和文法处理等,从而最终将输入的语音信号转变成文本或命令。
图 1-1 语音识别系统原理框图
本文所描述的语音识别系统将对数字 0~9 共 10 段参考语音进行训练并建立模板库,
之后将对多段测试语音进行识别测试。系统实现了上图中的语音输入、预处理、特征提取
训练建立模板库和识别等模块,最终建立了一个比较完整的语音识别系统。
3 / 15
剩余14页未读,继续阅读
2014-05-08 上传
2019-03-07 上传
2021-09-26 上传
105 浏览量
118 浏览量
2022-05-31 上传
2022-07-16 上传

beibeidzh
- 粉丝: 8
- 资源: 24万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Delphi高手突破(官方版).pdf
- LoadRunner中文版文档
- MATLAB 训练讲义toStudents.pdf
- 计算机操作系统(汤子瀛)习题答案
- 构建SOA 的IT 捷径
- 2002年程序员上午试卷
- 雅思王路807 必备雅思工具
- modelsim编译xilinx库的方法.doc
- 西软宽带安全审计管理软件说明书
- kjava开发手册--介绍j2me开发的一些实践
- H.264.pdf,编码解码
- ASP.NET专业项目实例开发(修订版)-课件(部分3)
- ASP.NET专业项目实例开发(修订版)-课件(部分1)
- cuda中文手册--GPU的通用编程
- 2009最新java经典面试题目(包含答案)
- java设计模式中文版
