DiffTaichi:物理模拟的差异化编程
需积分: 9 4 浏览量
更新于2024-07-09
收藏 4.24MB PDF 举报
"DiffTaichi - 可微分编程用于物理模拟"
在计算机视觉领域,DiffTaichi是一项创新技术,它是一种专为构建高性能可微分物理模拟器设计的新型可微分编程语言。该技术首次发表在ICLR 2020的会议论文中,由MIT CSAIL、Adobe Research和UC Berkeley的研究人员共同提出。DiffTaichi的独特之处在于它结合了命令式编程语言的特点,能够自动生成模拟步骤的梯度,同时保持算术强度和并行性。
DiffTaichi的工作原理是通过源代码转换来实现的,这些转换能够生成模拟步骤的梯度,而不影响计算效率和并行执行的能力。这得益于一个轻量级的“磁带”机制,它可以记录整个模拟程序的结构,并按反向顺序重播梯度内核,从而实现端到端的反向传播。这种方法使得在物理模拟中的基于梯度的学习和优化任务变得更加高效和便捷。
论文展示了DiffTaichi在多个物理模拟器上的应用效果,例如,使用该语言编写的一个可微分弹性物体模拟器,其代码长度比手工编写的CUDA版本缩短了4.2倍,但性能并未降低。这表明DiffTaichi不仅提高了开发者的生产力,还显著提升了代码的执行效率。
在计算机视觉中,物理模拟通常用于理解真实世界物体的行为和交互,以及训练深度学习模型进行预测和决策。例如,它可以用于虚拟环境中的物体碰撞检测、动画生成,甚至是机器人操作的学习。通过DiffTaichi,开发者可以更快速地迭代和优化物理模型,而无需手动微调复杂的数值计算,这对于研究和应用都具有重大意义。
此外,DiffTaichi的开源性质使得全球的研究者和工程师都能够利用这个工具,进一步推动计算机视觉和物理模拟的融合。这可能会引领新的研究方向,比如在虚拟现实(VR)、增强现实(AR)和游戏开发中创建更加逼真的物理效果,或者在自动驾驶汽车等领域帮助训练更加准确的环境感知模型。
DiffTaichi提供了一种全新的方法,将编程语言与物理模拟相结合,简化了复杂模拟系统的开发过程,并通过自动梯度计算加速了学习和优化。这不仅对于计算机视觉研究者,也对整个计算科学领域的专业人士来说,都是一种强大的工具,有望推动相关领域的发展。
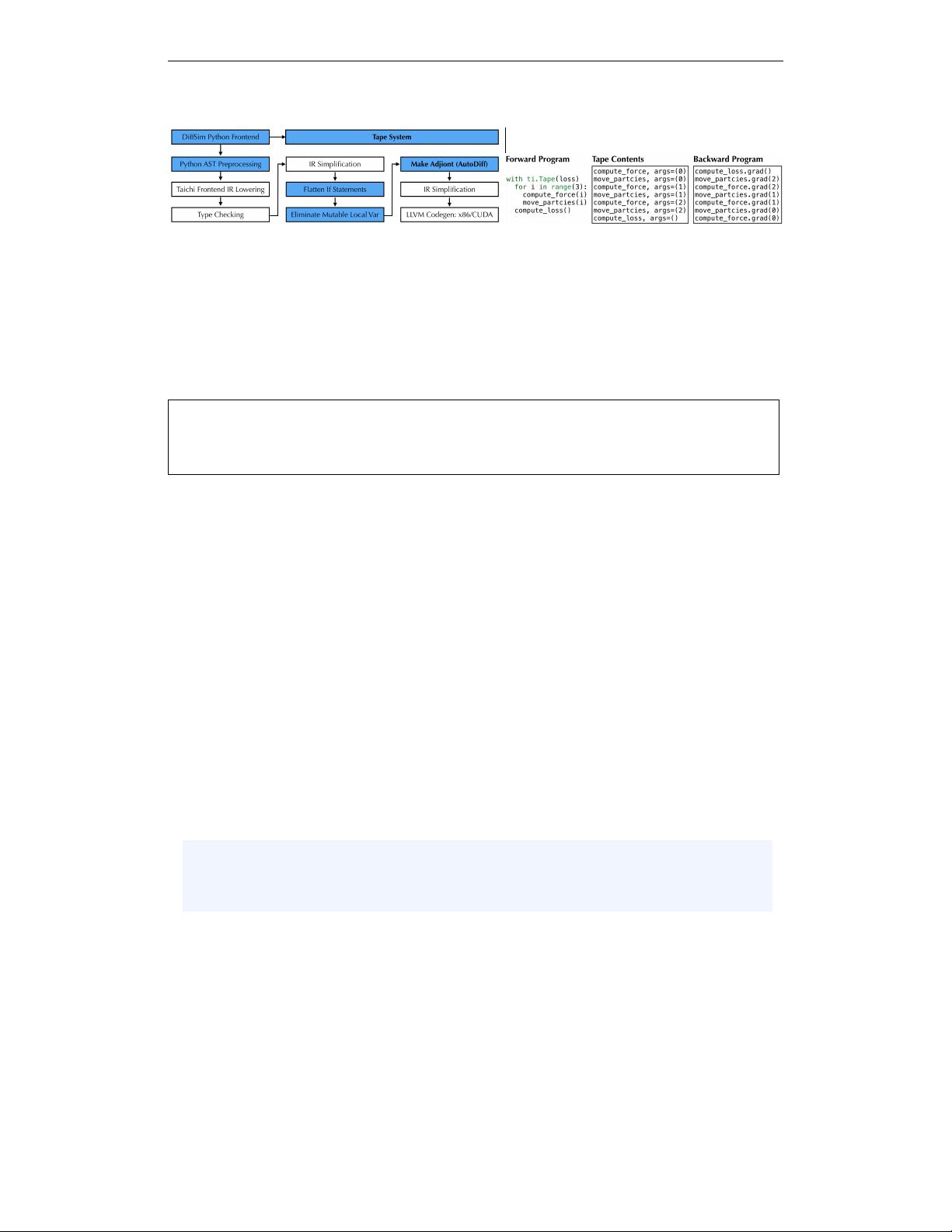
Published as a conference paper at ICLR 2020
Figure 2: Left: The DiffTaichi system. We reuse some infrastructure (white boxes) from Taichi,
while the blue boxes are our extensions for differentiable programming. Right: The tape records
kernel launches and replays the gradient kernels in reverse order during backpropagation.
Assumption Unlike functional programming languages where immutable output buffers are gen-
erated, imperative programming allows programmers to freely modify global tensors. To make
automatic differentiation well-defined under this setting, we make the following assumption on im-
perative kernels:
Global Data Access Rules:
1) If a global tensor element is written more than once, then starting from the second write, the
write must come in the form of an atomic add (“accumulation”).
2) No read accesses happen to a global tensor element, until its accumulation is done.
In forward simulators, programmers may make subtle changes to satisfy the rules. For instance,
in the mass-spring simulation example, we record the whole history of x and v, instead of keep-
ing only the latest values. The memory consumption issues caused by this can be alleviated via
checkpointing, as discussed later in Appendix D.
With these assumptions, kernels will not overwrite the outputs of each other, and the goal of AD is
clear: given a primal kernel f that takes as input X
1
, X
2
, . . . , X
n
and outputs (or accumulates to)
Y
1
, Y
2
, . . . , Y
m
, the generated gradient (adjoint) kernel f
∗
should take as input X
1
, X
2
, . . . , X
n
and
Y
∗
1
, Y
∗
2
, . . . , Y
∗
m
and accumulate gradient contributions to X
∗
1
, X
∗
2
, . . . , X
∗
m
, where each X
∗
i
is an
adjoint of X
i
, i.e. ∂(loss)/∂X
i
.
Storage Control of Adjoint Tensors Users can specify the storage of adjoint tensors using the
Taichi data structure description language (Hu et al., 2019a), as if they are primal tensors. We also
provide ti.root.lazy_grad() to automatically place the adjoint tensors following the layout of their
primals.
3.1 LOCAL AD: DIFFERENTIATING TAICHI KERNELS USING SOURCE CODE TRANSFORMS
A typical Taichi kernel consists of multiple levels of for loops and a body block. To make later AD
easier, we introduce two basic code transforms to simplify the loop body, as detailed below.
int a = 0;
if (b > 0) { a = b;}
else { a = 2b;}
a = a + 1;
return a;
// flatten branching
int a = 0;
a = select(b > 0, b, 2b);
a = a + 1
return a;
// eliminate mutable var
ssa1 = select(b > 0, b, 2b);
ssa2 = ssa1 + 1
return ssa2;
Figure 3: Simple IR preprocessing before running the AD source code transform (left to right).
Demonstrated in C++. The actual Taichi IR is often more complex. Containing loops are ignored.
Flatten Branching In physical simulation branches are common, e.g., when implementing bound-
ary conditions and collisions. To simplify the reverse-mode AD pass, we first replace “if” statements
with ternary operators select(cond, value_if_true, value_if_false), whose gradients are clearly de-
fined (Fig. 3, middle). This is a common transformation in program vectorization (e.g. Karrenberg
& Hack (2011); Pharr & Mark (2012)).
Eliminate Mutable Local Variables After removing branching, we end up with straight-line loop
bodies. To further simplify the IR and make the procedure truly single-assignment, we apply a
4
剩余19页未读,继续阅读
2021-05-27 上传
2019-09-18 上传
2021-02-10 上传
2024-09-05 上传
2021-02-11 上传
2018-10-09 上传
2021-06-02 上传
2021-02-20 上传
101 浏览量

潜夙
- 粉丝: 0
- 资源: 40
 我的内容管理
展开
我的内容管理
展开







最新资源
- ES管理利器:ES Head工具详解
- Layui前端UI框架压缩包:轻量级的Web界面构建利器
- WPF 字体布局问题解决方法与应用案例
- 响应式网页布局教程:CSS实现全平台适配
- Windows平台Elasticsearch 8.10.2版发布
- ICEY开源小程序:定时显示极限值提醒
- MATLAB条形图绘制指南:从入门到进阶技巧全解析
- WPF实现任务管理器进程分组逻辑教程解析
- C#编程实现显卡硬件信息的获取方法
- 前端世界核心-HTML+CSS+JS团队服务网页模板开发
- 精选SQL面试题大汇总
- Nacos Server 1.2.1在Linux系统的安装包介绍
- 易语言MySQL支持库3.0#0版全新升级与使用指南
- 快乐足球响应式网页模板:前端开发全技能秘籍
- OpenEuler4.19内核发布:国产操作系统的里程碑
- Boyue Zheng的LeetCode Python解答集
