机票大数据平台:Spark+Hadoop驱动的机场吞吐量与航班分析
需积分: 21 178 浏览量
更新于2024-07-17
1
收藏 39KB DOCX 举报
本需求规格说明书详细阐述了针对机票大数据平台的开发需求,旨在通过收集和分析携程等订票网站的机票信息,提供关键的业务洞察。项目的核心目标是统计城市间的吞吐量、航空公司业务占比及服务水平,并通过可视化展示票价变动,帮助用户做出更明智的购票决策。
Spark作为核心的计算引擎,其内存分布数据集的优势使得平台能够支持交互式查询和大规模数据处理,提升数据分析效率。Hadoop则提供了分布式文件系统HDFS,确保了数据的高容错性和大容量存储,适应超大数据集的应用。HDFS允许流式访问数据,配合MapReduce模型,实现了数据的高效存储和处理。
该软件是一个独立的机票大数据统计分析网站,采用Hadoop进行数据分布式存储,Spark进行实时处理,实现了从数据到分析的无缝连接。开发背景主要针对企业用户,他们关注航班价格、航空公司市场份额和航线选择,同时,普通用户也寻求低价机票和航班选择信息。
在功能需求方面,系统应具备实时显示热门城市航线、航空公司占比,以及不同日期和时间的票价等功能。性能需求着重于优化用户体验,要求主页热门航线加载时间不超过1秒,单个航空公司或城市航线加载时间控制在0.5秒以内。系统设计需考虑最大并发用户数,至少达到400个,确保在高峰期也能稳定运行。
数据库设计包括关键表,如"airline_sample"用于存储航班基础信息,"airline"记录航线热度,"AllPrice"则储存每趟航班的多维度票价信息。然而,开发过程中面临的时间(仅20天)、硬件(阿里云服务器续期问题)和语言(前端框架版本不一致)约束也需要开发者密切关注和解决。
综上,该机票大数据平台项目旨在打造一个数据驱动的决策支持工具,通过整合和分析海量机票信息,为用户提供个性化和精准的旅行建议,同时兼顾性能和可用性,以满足不同用户群体的需求。
需求规格说明书 机票大数据平台
spark 算子实现大规模数据处理,实现程序到数据。
2.1.2.
开发背景
统计机票订票网站的机票信息得出各大城市间航线,分析航空城市的吞
吐量以及各航空公司的业务占比和服务水平,以便用户选择航班和订票
时间。
2.1.3.
软件功能
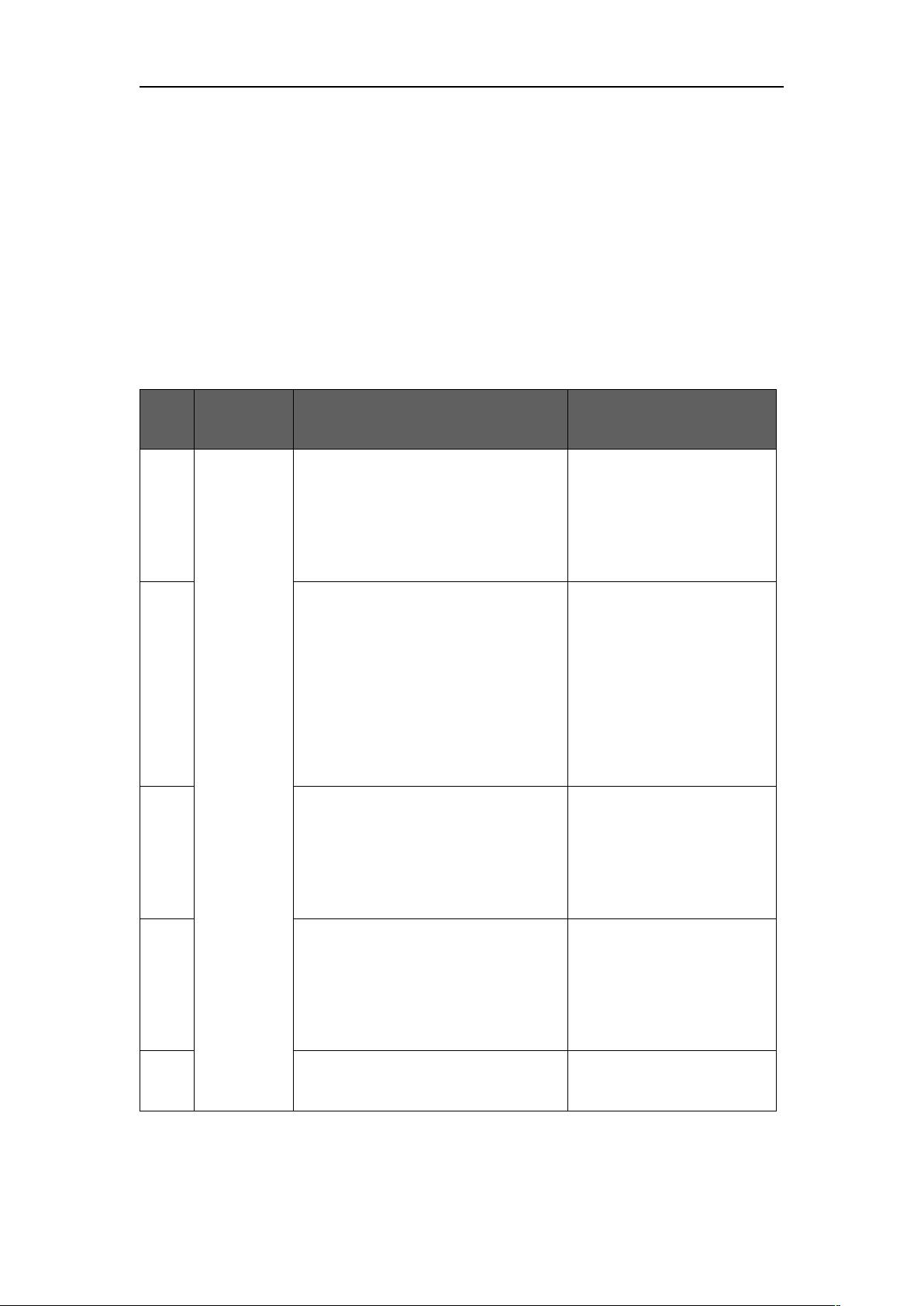
序号 模块 功能名称 简要描述
1
城市模块
各城市吞吐量显示
地图显示各城市吞吐量
信息
2
城市吞吐量变化显示
点击进入某城市单独界
面,图表显示该城市吞吐
量的变化
3
城市热门排行显示
显示城市热门程度以及
热门排行
4
某城市热门航线排行显示
显示热门目的地(航
线)的热门程度及排行
5
某城市航空公司业务占比显示 图表显示各航空公司的
4
剩余16页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-07-11 上传
2022-12-18 上传
2022-11-17 上传

阳宗德
- 粉丝: 7926
- 资源: 83
 我的内容管理
展开
我的内容管理
展开







最新资源
- rromero.io:作业PHP
- LogStop:重新生成文件链接以防止其被记录
- tsugi-welcome-to-recture-recording:将演讲记录介绍到课程站点并帮助进行初始配置的页面
- 60pc_Mechanical_Keyboard:60%尺寸的键盘,包括PCB,框架和固件
- OEPY:地球科学和海洋学基础Python基础课程
- Projeto-1
- 安卓毕业设计加源码-PlutoThesis:XeLaTeX版本的哈工大硕博毕业论文模版(此版本废弃,不再维护,新模板hithesishttps
- 高斯·塞德尔
- 无线充电qi标准协议1.2.4
- PBrsync:不再支持双向rsync和文件管理的Python包装器
- DapperLibrary:Dapper通用库
- Progress-Home-Acc-Fake
- Radios de Bolivia-crx插件
- 抑郁检测
- Cyclone IV四代FPGA器件详解datasheet(芯片手册中文版).zip
- barebones:适用于HTML5及更高版本的轻量级,骨架式,响应式WordPress样板主题。 以强大的功能作为起点很好,可以鼓励大多数项目的快速发展
