深入解析Kafka源码:从Producer到Consumer
需积分: 16 51 浏览量
更新于2024-07-18
收藏 5.5MB PDF 举报
"kafka源码分析,包括kafka的基础介绍、Unix环境下的使用、生产者机制、Scala语言实现的生产者、SocketServer的工作原理、日志追加流程、ISR(In-Sync Replicas)机制以及Scala语言实现的消费者初始化等核心概念。"
在深入分析Kafka源码之前,我们先了解一下Kafka的基本概念。Kafka是一个分布式流处理平台,由LinkedIn开发并开源,后来成为Apache软件基金会的顶级项目。它主要设计用于构建实时数据管道和流应用,能够高效地处理大量的实时数据。
1. **Kafka-Intro**: Kafka的核心特性包括高吞吐量、持久化、分区和复制。它允许创建主题(Topic),每个主题可以被分成多个分区(Partition),每个分区在集群中有一个或多个副本,以提供容错能力。
2. **Kafka-Unix**: 在Unix环境下,Kafka的部署和操作通常涉及配置环境变量、启动服务器、管理主题和消费者组等。Unix命令行工具如`kafka-topics.sh`和`kafka-console-consumer.sh`被用来与Kafka集群交互。
3. **Kafka-Producer**: 生产者是向Kafka主题发布消息的组件。源码分析中可能涵盖如何创建生产者实例、发送消息的流程、批处理和分区策略等。
4. **Kafka-Producer-Scala**: Scala是Kafka的首选编程语言,生产者API在Scala中提供了丰富的功能,包括异步发送、回调处理、错误处理和自定义分区器。
5. **Kafka-SocketServer**: SocketServer是Kafka内部处理客户端连接和请求的核心组件。源码分析可能涉及网络通信协议、请求处理线程模型以及性能优化等方面。
6. **Kafka-LogAppend**: 日志追加是Kafka存储消息的方式。分析这部分可能涉及日志分区的管理、消息的序列化与反序列化、以及如何保证消息顺序。
7. **Kafka-ISR**: ISR是保持副本同步的关键机制,包含处于同步状态的副本集合。当领导者副本失败时,ISR中的其他副本可以快速晋升为新的领导者,保证服务的连续性。
8. **Kafka-Consumer-init-Scala**: 消费者是读取Kafka主题消息的组件,源码分析可能涵盖消费者组管理、位移管理(Offset Management)、自动提交和手动提交位移的实现。
Kafka的源码分析涉及到许多底层细节,如线程池的管理、内存管理、网络I/O、序列化机制、分区策略以及容错设计等。通过深入理解这些机制,开发者可以更好地优化Kafka的性能、实现更复杂的应用场景,例如定制的生产者或消费者行为、提升消息处理效率,以及构建更健壮的数据流系统。对于分布式系统、大数据处理和实时数据分析领域的专业人士来说,深入研究Kafka的源码是提升技能和理解其工作原理的重要途径。

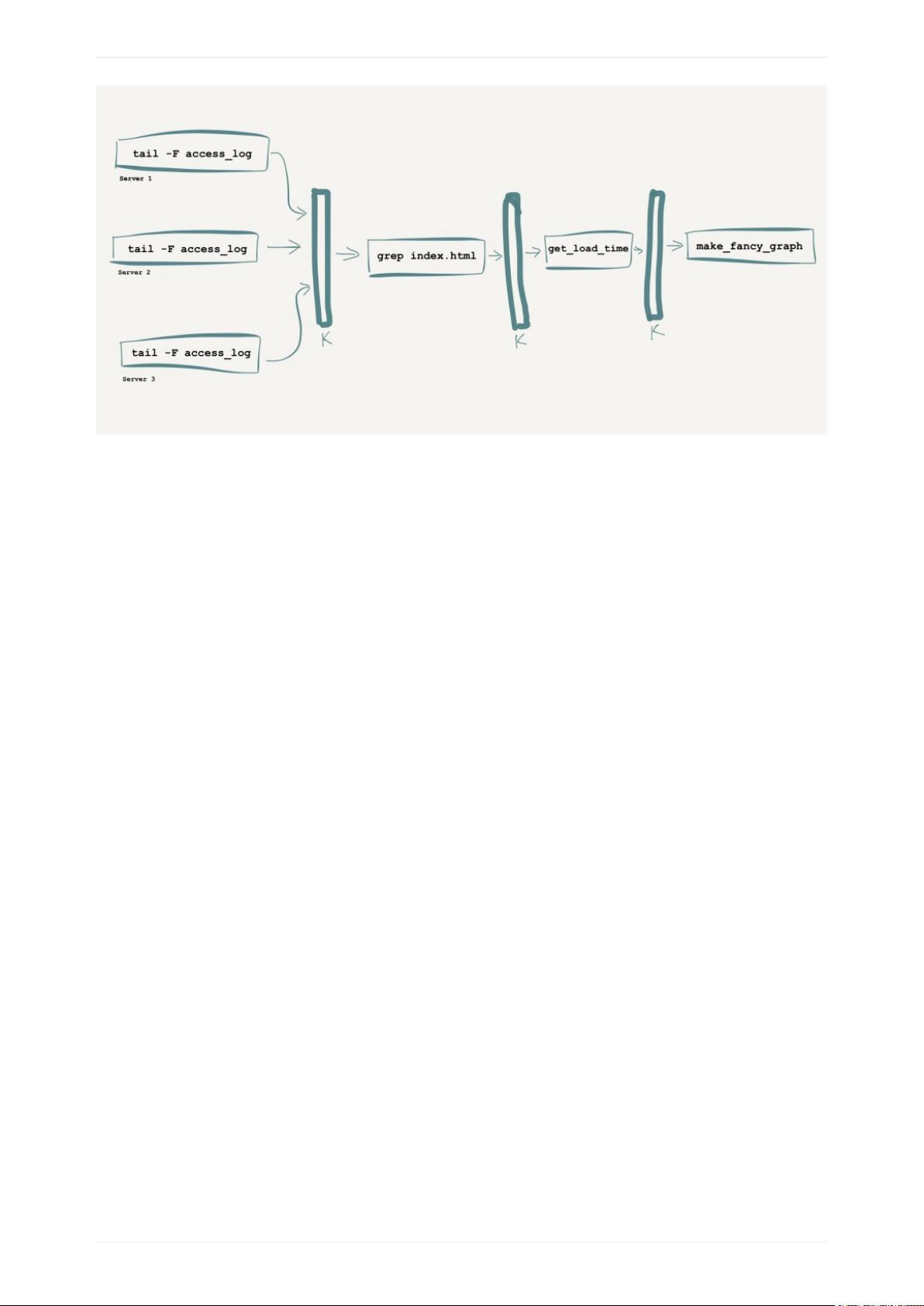
最简单的来看,Kafka就像一个Unix的管道:你将数据写到它的一端,然后数据从另一
端出来.
(严格来说,你写的数据会通过网络传输,你读取的数据也是通过网络,不过现在我们暂
时忽略这些.)
如果这就是Kafka所能做的,那有什么了不起的,对吧?实际上Kafka还有一些额外的特
征,带来新的能力.
结构化数据
Unix的管道在文本数据行之间流动,通常是以新的一行为结束(这条管道).这些行可
以很长,但是工作单元仍然是一行文本.
如果你处理的不是ASCII数据,或者你处理的数据不能以一一行来表示就会有点麻烦.
而Kafka支持任意的格式和任意大小.
这就允许你可以存储任何数据到Kafka中:文本,CSV,二进制数据,自定义编码数据等
等.对于Kafka而言,它只是一系列的
消息,其中每条消息都是一系列的字节.比如可以(模拟)写一个Kafka的"命令行":
$TwitterFeed|filter_tweetsFrom@apachekafka
这里的filter_tweets命令可能不是一个简单的基于字符串的grep,而是一种能够理解
从TwitterFeed输出的数据格式.
比如TwitterFeed可能输出JSON,则filter_tweets需要做些JSON的处理.TwitterFeed
如果返回的是二进制数据,
则filter_tweets需要知道二进制的格式/协议.这种灵活性可以让Kafka成为一种发送
任何数据类型的Unix管道.
数据持久化
我们可能有一个复杂的会花费一些时间才能跑完的命令.如果只运行一次,你可能不
关心.但是如果你要多次迭代运行,
你可能会会将输出结果先写到一个文件中,这样之后的阶段可以更快地迭代,而不需
要重新多次运行很慢的那部分命令.
kafka
16kafka-Unix


剩余189页未读,继续阅读
109 浏览量
185 浏览量
2025-01-19 上传
164 浏览量
515 浏览量
166 浏览量
569 浏览量
873 浏览量

qq_24949063
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- React.js实现的简单HTML5文件拖放上传组件
- iReport:强大的开源可视化报表设计器
- 提升代码整洁性:Eclipse虚线对齐插件指南
- 迷你时间秀:个性化系统时间显示与管理工具
- 使用ruby-install一次性安装多种Ruby版本
- Logality:灵活自定义的JSON日志记录器
- Mogre3D游戏开发实践教程免费分享
- PHP+MySQL实现的简单权限账号管理小程序
- 微信支付统一下单签名错误排查与解决指南
- 虚幻引擎4实现的多边形地图生成器
- TouchJoy:专为触摸屏Windows设备打造的屏幕游戏手柄
- 全方位嵌入式开发工具包:ARM平台必备资源
- Java开发必备:30个实用工具类全解析
- IBM475课程资料深度解析
- Java聊天室程序:全技术栈源码支持与学习指南
- 探索虚拟房屋世界:house-tour-VR应用体验
