RNN与LSTM详解:从原理到GRU和LSTM的应用
需积分: 0 69 浏览量
更新于2024-08-04
1
收藏 176KB DOCX 举报
"本文介绍了RNN(循环神经网络)和LSTM(长短期记忆网络)的基本原理、应用场景以及它们在处理序列数据,特别是自然语言处理中的重要性。文章还提到了GRU(门控循环单元)作为RNN的一种变体,以及它们在解决长期依赖问题上的优势。"
RNN循环神经网络是一种深度学习模型,特别适合处理序列数据,如文本、音频或时间序列数据。RNN的核心特性是其循环结构,允许信息在时间轴上流动,使得模型能捕获序列中的上下文关系。在RNN的前向传播过程中,每个时间步的隐藏状态(a)会根据当前输入(x)和上一时间步的隐藏状态计算得到,并用于生成当前时间步的输出(y)。这个过程可以用以下公式表示:
a<1> = g(W*x<1> + b) + a<0>
其中,g是激活函数,如tanh或sigmoid,W是权重矩阵,b是偏置项,a<0>是初始隐藏状态。
然而,RNN在处理长序列数据时存在“梯度消失”或“梯度爆炸”的问题,这使得模型难以学习到长期依赖关系。为了解决这个问题,LSTM和GRU应运而生。
LSTM由遗忘门、输入门和输出门组成,这些门控机制允许模型选择性地记住或忘记信息,从而有效地解决了长期依赖问题。遗忘门负责丢弃不再需要的信息,输入门控制新信息的流入,而输出门则决定了当前时间步的输出如何基于记忆细胞的内容和当前状态。LSTM的更新过程可以概括为:
f< t > = σ(W_f * [h< t-1 >, x< t >] + b_f)
i< t > = σ(W_i * [h< t-1 >, x< t >] + b_i)
c< t > = f< t > * c< t-1 > + i< t > * tanh(W_c * [h< t-1 >, x< t >] + b_c)
o< t > = σ(W_o * [h< t-1 >, x< t >] + b_o)
h< t > = o< t > * tanh(c< t >)
GRU是LSTM的一个简化版本,它结合了遗忘和输入门的概念,使用更新门和重置门来控制信息的流动。GRU的计算过程如下:
r< t > = σ(W_r * [h< t-1 >, x< t >] + b_r)
z< t > = σ(W_z * [h< t-1 >, x< t >] + b_z)
c< t > = tanh(W_c * [r< t > * h< t-1 >, x< t >] + b_c)
h< t > = (1 - z< t >) * h< t-1 > + z< t > * c< t >
无论是LSTM还是GRU,它们都在自然语言处理任务中表现出色,特别是在处理那些需要长期依赖的句子,如区分"The cat, already ate…, was full."和"The cats, already ate…, were full."这样的情况。通过保留和操控长期记忆,这些门控RNN变体在许多NLP任务中取得了显著的性能提升。
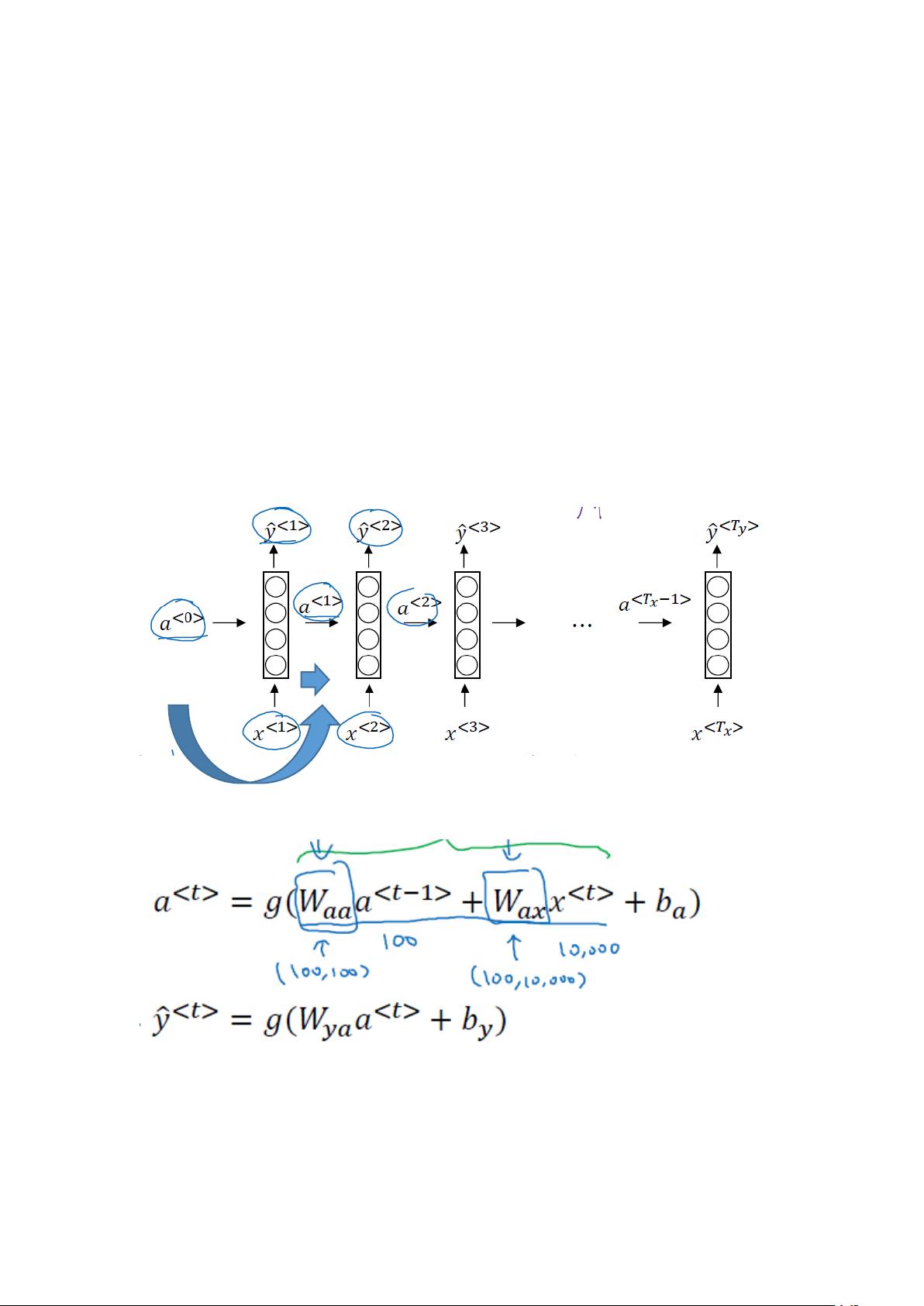
RNN 循环神经网络和 LSTM 网络
(参考网易云课堂吴恩达课程)
一、RNN 运用场景
用来处理序列数据,处理文本,最常见的如自然语言处理。RNN 每一层隐藏层会输出
一个 a 值,将其保存下来并传递给下一个隐藏层,因此可以充分利用好序列中每一个元素的
信息。
二、RNN 原理
1.前向传播过程
初始化 a<0>,传入 x<1>,计算出 a<1>,利用 a<1>计算出 y<1>,计算方向为逆时针
参数说明:g 为激活函数,第一行常用 tanh 函数,第二行常用 sigmoid 函数,b 为偏置项,
W 为权重
2.反向传播
下载后可阅读完整内容,剩余3页未读,立即下载
2021-11-04 上传
2023-03-14 上传
2024-06-28 上传
2022-07-15 上传
2022-07-14 上传
2019-02-28 上传
2024-05-22 上传
2021-08-04 上传
2024-03-24 上传

梁肖松
- 粉丝: 32
- 资源: 300
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
