




PyTorch优化技巧与Stable Diffusion模型性能提升实战
PDF格式 | 3.89MB |
更新于2025-03-20
| 17 浏览量 | 举报
知识点1:Stable Diffusion模型训练流水线
Stable Diffusion模型的训练流程涉及多个关键组件,包括文本编码器、图像信息生成器(Unet + Scheduler)和图像解码器等模块。这些模块共同工作,将文本信息转化为图像信息,然后再通过图像解码器生成最终的图像。每个模块的工作流程都是优化的关键点,通过优化这些模块的工作流程,可以提高模型的训练效率。
知识点2:优化数据加载器配置
数据加载器的配置对模型训练的效率有重要影响。通过优化数据加载器,可以减少数据加载的时间,提高模型的训练速度。具体的优化方法包括调整数据预处理的策略、优化数据的存储和读取方式等。
知识点3:内核融合提高计算效率
内核融合是一种提高计算效率的技术,它通过将多个计算操作合并为一个操作来减少计算开销。在Stable Diffusion模型的训练中,可以通过内核融合技术来减少GPU的计算延迟,从而提高模型的训练效率。
知识点4:引入FastAttention减少GPU内存访问延迟
FastAttention是一种优化技术,它通过减少GPU内存的访问次数来提高计算效率。在Stable Diffusion模型的训练中,可以通过引入FastAttention来减少GPU内存的访问延迟,从而提高模型的训练效率。
知识点5:利用多流和合并指数加权平均(EMA)改进模型参数更新
多流和合并指数加权平均(EMA)是两种改进模型参数更新的技术。多流技术可以并行处理多个计算任务,提高模型的训练效率。EMA技术则可以平滑模型的参数更新过程,提高模型的训练稳定性。在Stable Diffusion模型的训练中,可以通过这两种技术来改进模型的参数更新,从而提高模型的训练效率和稳定性。
知识点6:应用ZeRO降低显存占用提升批处理量
ZeRO是一种优化技术,它可以有效地降低模型在GPU上的显存占用,从而允许更大的批量数据被加载到GPU中进行训练,提高模型的训练效率。在Stable Diffusion模型的训练中,可以通过应用ZeRO技术来降低模型的显存占用,提升批处理量,从而提高模型的训练速度。
知识点7:性能指标分析
通过对不同优化技术前后的性能指标进行对比,可以直观地展示每项优化的效果。性能指标主要包括训练时间、硬件资源消耗、模型的准确性等。通过分析这些性能指标,可以评估优化技术的效果,为进一步的模型优化提供依据。
知识点8:实验数据和性能提升百分比
文中给出了具体的实验数据和性能提升百分比,这为评估优化技术的效果提供了直接的证据。通过这些实验数据,可以直观地看到优化技术在实际应用中的效果,为优化技术的选择提供参考。
知识点9:应用场景
优化技术主要应用于基于PyTorch构建并希望提高其训练速度或降低成本的专业团队,特别是在云平台或本地集群上大规模部署Stable Diffusion模型进行训练的场景。
知识点10:硬件平台兼容性
优化技术的应用可以显著提高Stable Diffusion模型在多种硬件平台下的表现,尤其是NVIDIA A100 GPU。这对于优化技术的普及和应用具有重要意义。
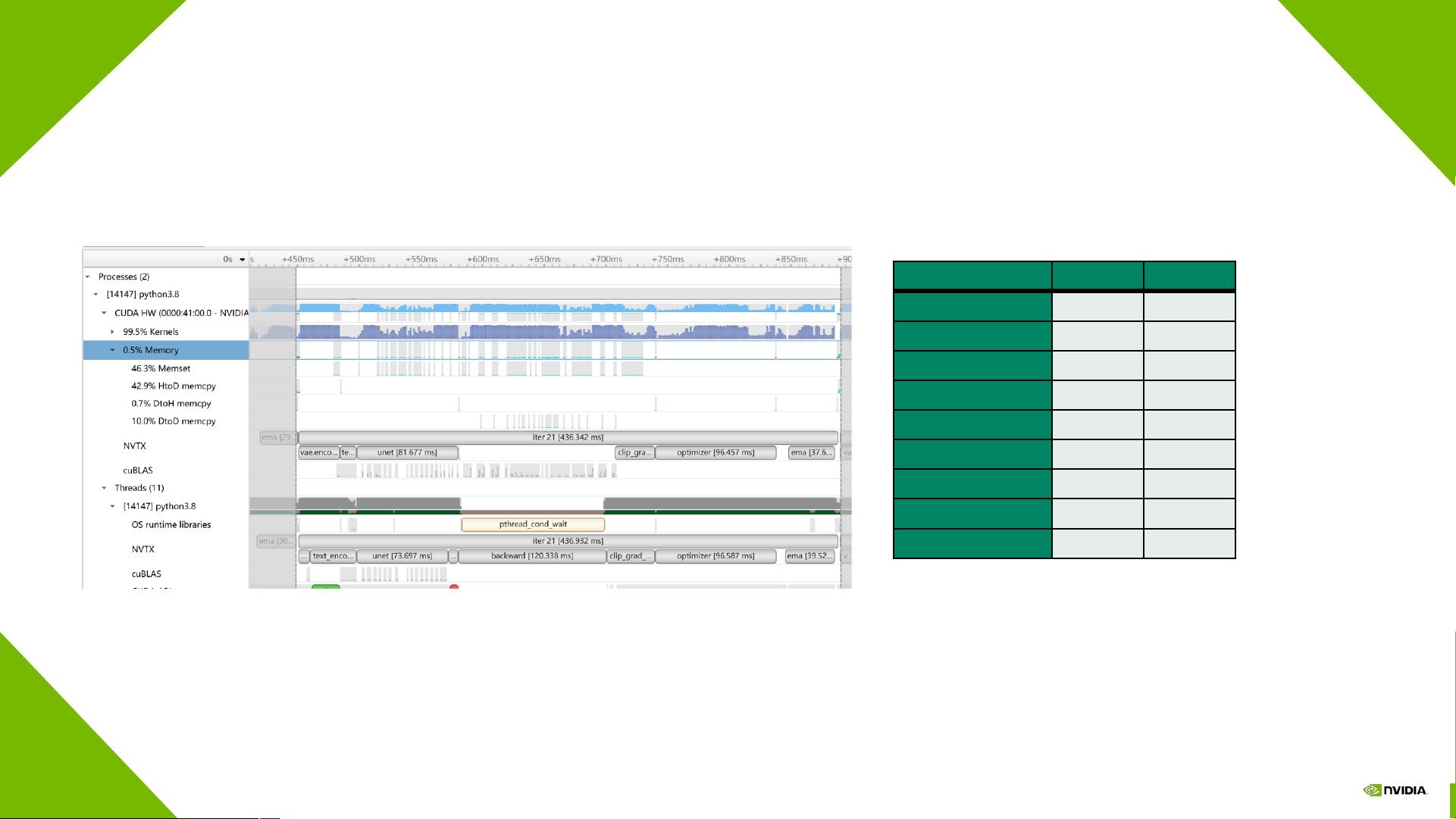
Stable Diffusion Training Pipeline
Nsys timeline
module
Time(ms)
ratio
vae.encoder fwd
33.173
7.60%
text_encoder fwd
13.946
3.20%
Unet fwd
81.677
18.72%
Unet bwd
125.197
28.69%
clip_grad_norm
32.124
7.36%
update
96.457
22.11%
ema_unet
37.659
8.63%
other
16.109
3.69%
total
436.342
100.00%
下载后可阅读完整内容,剩余22页未读,立即下载
查看更多
相关推荐





磐基Stack专业服务团队
- 粉丝: 5327
 我的内容管理
展开
我的内容管理
展开








最新资源
- MySQL下JDBC分页代码的优化与应用
- Linux下具备缩放功能的H264转JPG图片工具
- 通联支付平台演示案例与技术分析
- T9拼音输入法在51单片机上的Proteus仿真实现
- 清华Delphi数据库开发案例解析与源码下载
- 博弈论宝典深度解析与应用指南
- 极通EWEBS专业版50用户补丁发布,支持20090217版本升级
- 深入解析Java枚举类型的应用与技巧
- Kotlin技术探索:深入理解和应用navigation-subgraph-viewmodel
- 清华课件:数字电路第十、十一章学习资料
- 《信号与系统》郑君里教材完整习题解答指南
- Vuejs结合Laravel打造SPA项目实战
- 探讨网络游戏中的社区网络与联网音频设备应用
- C# 开发中的日历控件使用指南
- 蓝锂插件:实现定时自动采集与网站数据管理
- ScriptCryptor: 将vbs脚本封装成不可见的exe文件






















