Presto在数据湖:机遇、挑战与技术解析
版权申诉
87 浏览量
更新于2024-07-05
收藏 14.56MB PDF 举报
"4-1.Presto在数据湖领域的机遇与挑战.pdf"
Presto是一种云原生的数据湖分析工具,尤其在大数据领域中,它展现出了在数据湖分析中的巨大潜力和挑战。阿里云的云原生数据湖分析团队(DataLakeAnalytics,DLA)专注于研发DLA-Presto,这是一款基于Presto的解决方案,由徐明明等专家进行开发和维护。Presto最初由Facebook创建,目的是解决Hive在交互式查询上的性能问题,现在已成为一个广泛使用的在线分析处理(OLAP)系统。
Presto的优势在于其高效性,尤其适用于adhoc查询和数据探索,同时也能胜任轻量级的ETL任务。它支持多种开放的文件格式,如CSV、JSON、Parquet和ORC,使得用户能够处理结构化和非结构化的数据。此外,Presto能轻松连接各种不同的数据源,允许用户在数据湖环境中进行灵活的数据分析。
数据湖作为一种集中式存储,允许用户存储任意规模的结构化和非结构化数据,例如,阿里云的对象存储服务(OSS)可作为典型的LakeStorage。Presto采用全内存计算,确保了查询的快速响应,同时,其易用的插件机制增强了系统的可扩展性。Presto还拥有强大的社区支持,提供了完整的SQL语义,这意味着用户无需担心SQL语法限制,几乎可以实现所有的数据分析需求。
在架构层面,Presto由Coordinator和Worker组成。Coordinator负责SQL查询的解析、生成执行计划和任务调度,而Worker则执行实际的计算任务。查询过程分为多个Stage,每个Stage由分布在网络中的多个Task执行,数据以Split的形式在Task间流动,最终转化为查询结果。这种设计确保了整个查询过程中数据大部分时间保持在内存中,避免了频繁的磁盘I/O,从而极大地提高了性能。
Presto的插件机制包括四类:Storage Plugin、Metadata Plugin、Session Plugin和JDBC Driver Plugin。这些插件允许Presto接入不同的数据源,管理元数据,处理会话属性,以及提供与不同客户端的交互能力。通过这种机制,Presto可以无缝集成如HDFS、S3、Hive、MySQL等多种数据存储系统,极大地增强了其在数据湖场景下的适用性。
面对数据湖领域的挑战,Presto不断优化,以适应日益复杂的数据需求和大规模的数据处理。例如,随着数据量的增长,如何保证查询性能、实现高效的数据分片和并行处理、以及优化资源管理和调度都是Presto需要持续解决的问题。此外,随着非结构化数据的增多,Presto在处理这些数据的能力也需要不断提升。
Presto作为一款强大的数据湖分析引擎,提供了快速、灵活且全面的SQL支持,为用户在数据湖环境中进行数据分析提供了强大工具。然而,随着技术的发展和数据湖的深化应用,Presto还需不断进化,以应对新的挑战和机遇。
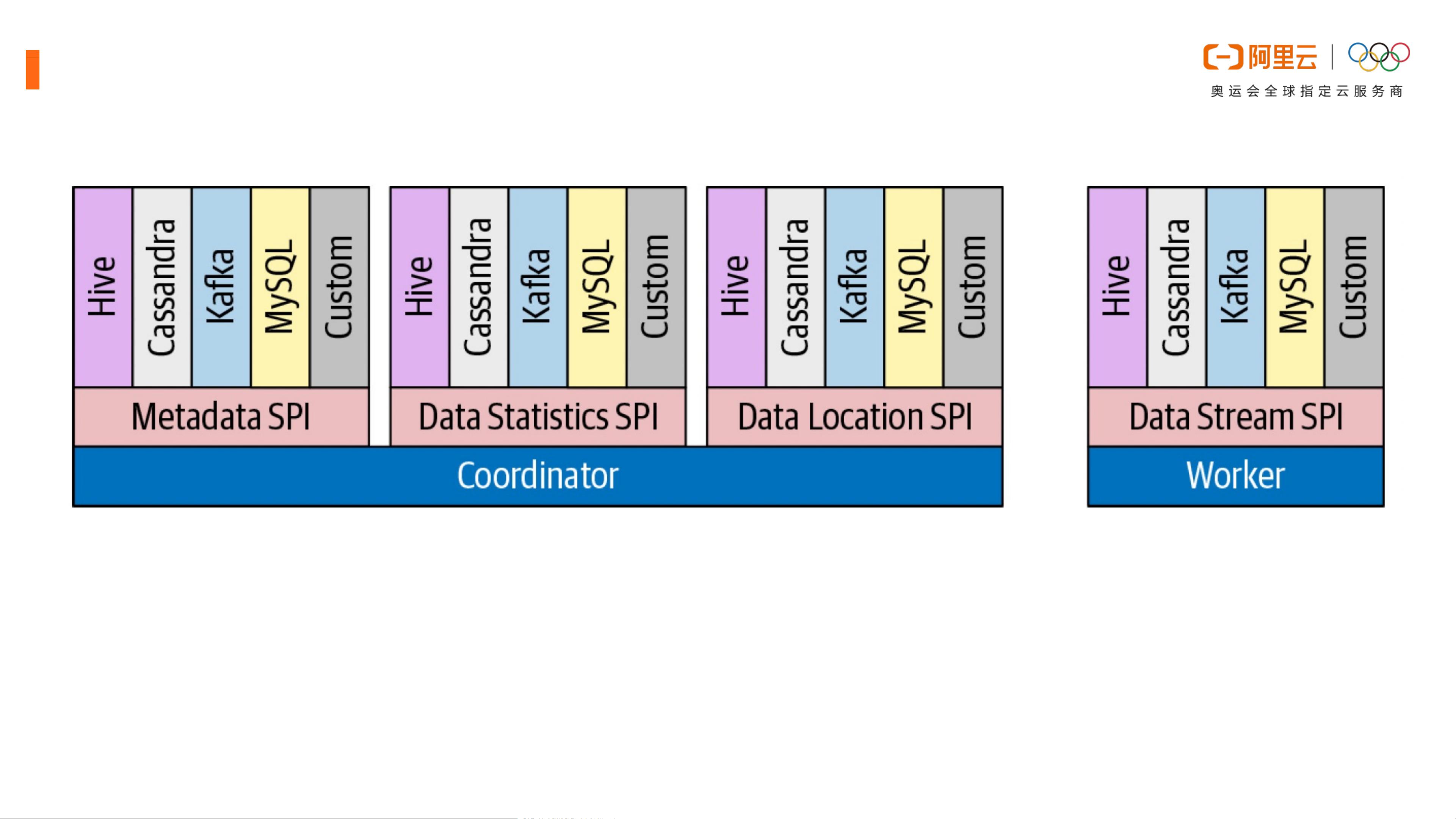
Presto的插件机制
1.Presto的插件机制主要由四类SPI组成:
1.元数据SPI:用来告诉Coordinator这个插件有哪些库,每个库有哪些表,每个表有哪些列。
2.统计信息SPI:用来告诉Coordinator每个表的行数,每个列的非空个数之类的,从而帮助Coordinator生成更优的执
行计划。
3.数据位置SPI:用来告诉Coordinator每张表的数据地址在哪里,是如何分布的,从而可以为每张表生成Split,并且
分配给最优的Worker。
4.数据流SPI:用来告诉Worker如何从给定的Split信息,从底层读取数据出来。

剩余38页未读,继续阅读
2021-10-12 上传
2020-06-04 上传
2021-08-09 上传
2019-10-10 上传
2021-03-29 上传
2017-09-24 上传

普通网友
- 粉丝: 13w+
- 资源: 9195
 我的内容管理
展开
我的内容管理
展开







最新资源
- ARSW-FINAL-EXAM2
- Tarea_Sistemas_distribuidos
- 北方交通大学硕士研究生入学考试试题结构力学2006.rar
- hunter
- CortexAnalysis:基于皮质分析的诊断
- UrsineEngine:跨平台游戏引擎,用C ++编写并可通过Python编写脚本
- Zebra_Accordion:jQuery的小手风琴插件-开源
- CipherApp:基本密码应用程序
- test_glassdoor
- abetsunggo.me
- 考试 冬小麦不同水分条件下的产量试验进行了不同水分处
- blobgen:JS库,用于将随机化的剪切路径应用于HTML元素,创建有趣的非矩形形状
- ASAM_OpenDRIVE_BS_V1-6-0_cn.7z
- MyApplication.zip
- 少儿编程Scratch与数学深度融合课程(全套视频资料).rar
- VC++自绘制作weather天气预报界面
