Transformer-XL:超越固定长度上下文的注意力语言模型
需积分: 15 92 浏览量
更新于2024-07-14
收藏 4.36MB PDF 举报
"Transformer-XL是针对语言模型的深度学习架构,旨在解决Transformer在处理长序列时固定长度上下文的问题,通过引入段级循环机制和新颖的位置编码方案,实现了对更长期依赖的学习,同时保持了时间连贯性。"
Transformer-XL论文详细探讨了Transformer模型在语言建模中的局限性,主要在于其固定长度上下文限制,这使得模型难以捕捉到超出该范围的长期依赖关系。为了解决这个问题,研究者提出了Transformer-XL这一新架构。Transformer-XL的核心创新包括两个关键部分:
1. **段级循环机制(Segment-Level Recurrence Mechanism)**:与传统的循环神经网络(RNN)不同,Transformer-XL不再局限于单步的前向传递。它将输入序列分成多个连续的片段,并在片段间建立联系,允许信息跨片段传播,从而实现对长序列的记忆。这种设计避免了完全重计算整个历史序列,提高了效率。
2. **新颖的位置编码方案(Novel Positional Encoding Scheme)**:Transformer模型原始的位置编码在固定长度内有效,而Transformer-XL提出了一种新的位置编码方法,能够适应更长的序列,并且能处理跨越多个片段的位置信息。这确保了模型在处理长序列时仍然可以正确地理解序列顺序。
通过这些改进,Transformer-XL在保留Transformer模型并行计算优势的同时,显著提升了处理长序列的能力。实验结果显示,Transformer-XL相比RNN模型,能学习到的长期依赖关系长80%,相比标准Transformer则长450%。在各种序列长度的任务上,Transformer-XL都表现出了优越的性能。此外,由于其高效的评估过程,Transformer-XL在评估阶段的速度比标准Transformer快1,800多倍。
在实际应用中,Transformer-XL的这些提升意味着它可以更有效地应用于如机器翻译、文本生成、情感分析等需要理解和处理长依赖关系的任务。它不仅提高了模型的性能,而且优化了计算效率,对于大规模语言模型的训练和部署具有重要意义。Transformer-XL的成功改进了当时的最佳结果,降低了每词交叉熵(bpc)和困惑度(perplexity),进一步推动了自然语言处理领域的进步。
x
1
x
2
x
4
x
3
x
8
x
5
x
6
x
7
New Seg ment
x
12
x
9
x
10
x
11
Fixed (No Grad)
x
1
x
2
x
4
x
3
x
8
x
5
x
6
x
7
Fixed (No Grad) New Seg ment
(a) Training phase.
x
1
x
2
x
4
x
3
x
8
x
5
x
6
x
7
x
12
x
9
x
10
x
11
Extende d Co ntext
(b) Evaluation phase.
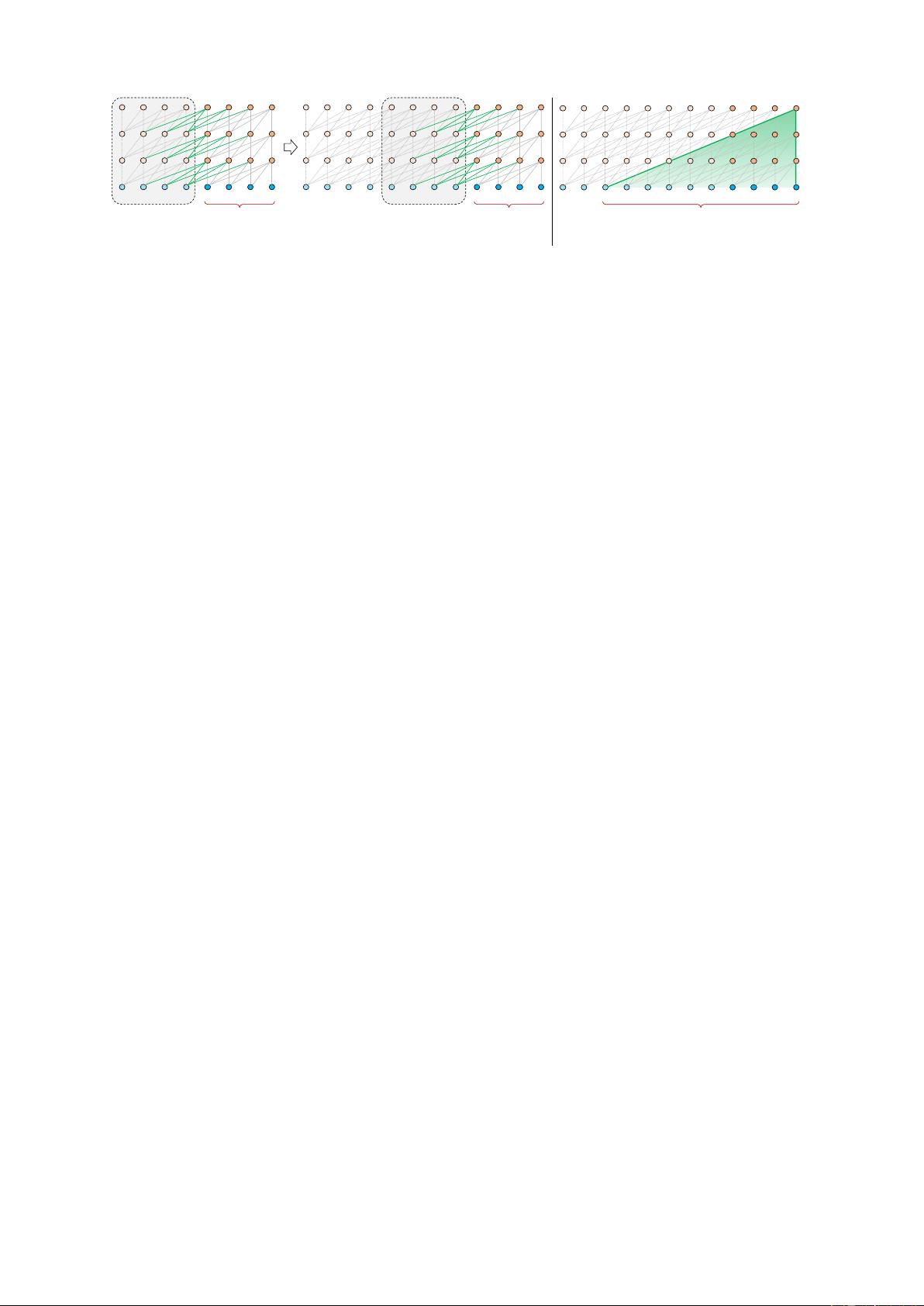
Figure 2: Illustration of the Transformer-XL model with a segment length 4.
per-segment, which differs from the same-layer
recurrence in conventional RNN-LMs. Conse-
quently, the largest possible dependency length
grows linearly w.r.t. the number of layers as well
as the segment length, i.e., O(N × L), as vi-
sualized by the shaded area in Fig. 2b. This
is analogous to truncated BPTT (Mikolov et al.,
2010), a technique developed for training RNN-
LMs. However, different from truncated BPTT,
our method caches a sequence of hidden states in-
stead of the last one, and should be applied to-
gether with the relative positional encoding tech-
nique described in Section 3.3.
Besides achieving extra long context and re-
solving fragmentation, another benefit that comes
with the recurrence scheme is significantly faster
evaluation. Specifically, during evaluation, the
representations from the previous segments can
be reused instead of being computed from scratch
as in the case of the vanilla model. In our ex-
periments on enwiki8, Transformer-XL is up to
1,800+ times faster than the vanilla model during
evaluation (see Section 4).
Finally, notice that the recurrence scheme does
not need to be restricted to only the previous seg-
ment. In theory, we can cache as many previous
segments as the GPU memory allows, and reuse
all of them as the extra context when processing
the current segment. Thus, we can cache a prede-
fined length-M old hidden states spanning (pos-
sibly) multiple segments, and refer to them as the
memory m
n
τ
∈ R
M×d
, due to a clear connection to
the memory augmented neural networks (Graves
et al., 2014; Weston et al., 2014). In our experi-
ments, we set M equal to the segment length dur-
ing training, and increase it by multiple times dur-
ing evaluation.
3.3 Relative Positional Encodings
While we found the idea presented in the pre-
vious subsection very appealing, there is a cru-
cial technical challenge we haven’t solved in or-
der to reuse the hidden states. That is, how can
we keep the positional information coherent when
we reuse the states? Recall that, in the standard
Transformer, the information of sequence order is
provided by a set of positional encodings, denoted
as U ∈ R
L
max
×d
, where the i-th row U
i
corre-
sponds to the i-th absolute position within a seg-
ment and L
max
prescribes the maximum possible
length to be modeled. Then, the actual input to the
Transformer is the element-wise addition of the
word embeddings and the positional encodings. If
we simply adapt this positional encoding to our
recurrence mechanism, the hidden state sequence
would be computed schematically by
h
τ +1
= f (h
τ
, E
s
τ +1
+ U
1:L
)
h
τ
= f (h
τ −1
, E
s
τ
+ U
1:L
),
where E
s
τ
∈ R
L×d
is the word embedding se-
quence of s
τ
, and f represents a transformation
function. Notice that, both E
s
τ
and E
s
τ +1
are as-
sociated with the same positional encoding U
1:L
.
As a result, the model has no information to dis-
tinguish the positional difference between x
τ,j
and
x
τ +1,j
for any j = 1, . . . , L, resulting in a sheer
performance loss.
In order to avoid this failure mode, the funda-
mental idea is to only encode the relative posi-
tional information in the hidden states. Concep-
tually, the positional encoding gives the model a
temporal clue or “bias” about how information
should be gathered, i.e., where to attend. For the
same purpose, instead of incorporating bias stati-
cally into the initial embedding, one can inject the
same information into the attention score of each
layer. More importantly, it is more intuitive and
generalizable to define the temporal bias in a rela-
tive manner. For instance, when a query vector q
τ,i
attends on the key vectors k
τ,≤i
, it does not need
to know the absolute position of each key vector
to identify the temporal order of the segment. In-
stead, it suffices to know the relative distance be-
tween each key vector k
τ,j
and itself q
τ,i
, i.e. i−j.
Practically, one can create a set of relative posi-
剩余19页未读,继续阅读
424 浏览量
2024-01-22 上传
196 浏览量
424 浏览量
289 浏览量
125 浏览量
2024-10-08 上传
2023-05-19 上传
158 浏览量

叫我李嘉图
- 粉丝: 17
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- LabVIEW使用TCP通讯示例程序(包含服务器端和客户端VI源程序代码文件,可直接运行)
- 微信小程序设计-蒙台梭利幼教.zip
- 微信小程序设计-搜索框.zip
- 微信小程序设计-粤语小词典.zip
- 微信小程序设计-KFC-master.zip
- vivado 工程 axi ethlite
- 微信小程序设计-喜乐茶铺商城小程序.zip
- 微信小程序设计-你画我猜.zip
- 微信小程序设计-仿斗鱼直播小程序.zip
- 微信小程序设计-艺术.zip
- 微信小程序设计-会议精灵.zip
- Python pdf2image中所需要的poppler文件
- 智能排课系统,管理员登录后设置实验室数量,和设定实验室开放的时间,分发各账号给老师,使用C#开发.zip
- C语言C++ 爱心表白代码.zip
- 阿里云DataV数据可视化.zip
- 微信小程序设计-【学习Demo】影视推荐、音乐播放、地图.zip
