网络爬虫详解:通用与聚焦爬虫及其工作原理
需积分: 10 51 浏览量
更新于2024-08-27
收藏 1.2MB DOCX 举报
"51job 16.docx 关注于网络爬虫的介绍和搜索引擎的工作原理"
网络爬虫在IT行业中扮演着至关重要的角色,它们是互联网信息收集和整理的关键工具。爬虫通过遵循一定的规则,自动化地浏览并抓取网页内容,这相当于模拟用户的网络请求行为。在实际应用中,爬虫主要分为两类:通用爬虫和聚焦爬虫。
通用爬虫广泛用于搜索引擎,其任务是全网范围内抓取网页,构建一个互联网内容的本地副本,以供快速检索。这类爬虫通常由大型搜索引擎公司运行,如谷歌、百度等。它们从预定义的种子URL开始,逐步遍历链接,将新发现的URL加入待抓取队列,不断扩展抓取范围。
聚焦爬虫则更加有针对性,专注于特定主题或领域。它们根据目标数据定制爬取策略,例如累积式爬虫持续抓取并去除重复内容,增量式爬虫仅抓取更新或新增的网页,而深层网络爬虫则致力于获取隐藏在网络表单背后的、非直接链接可达的信息。
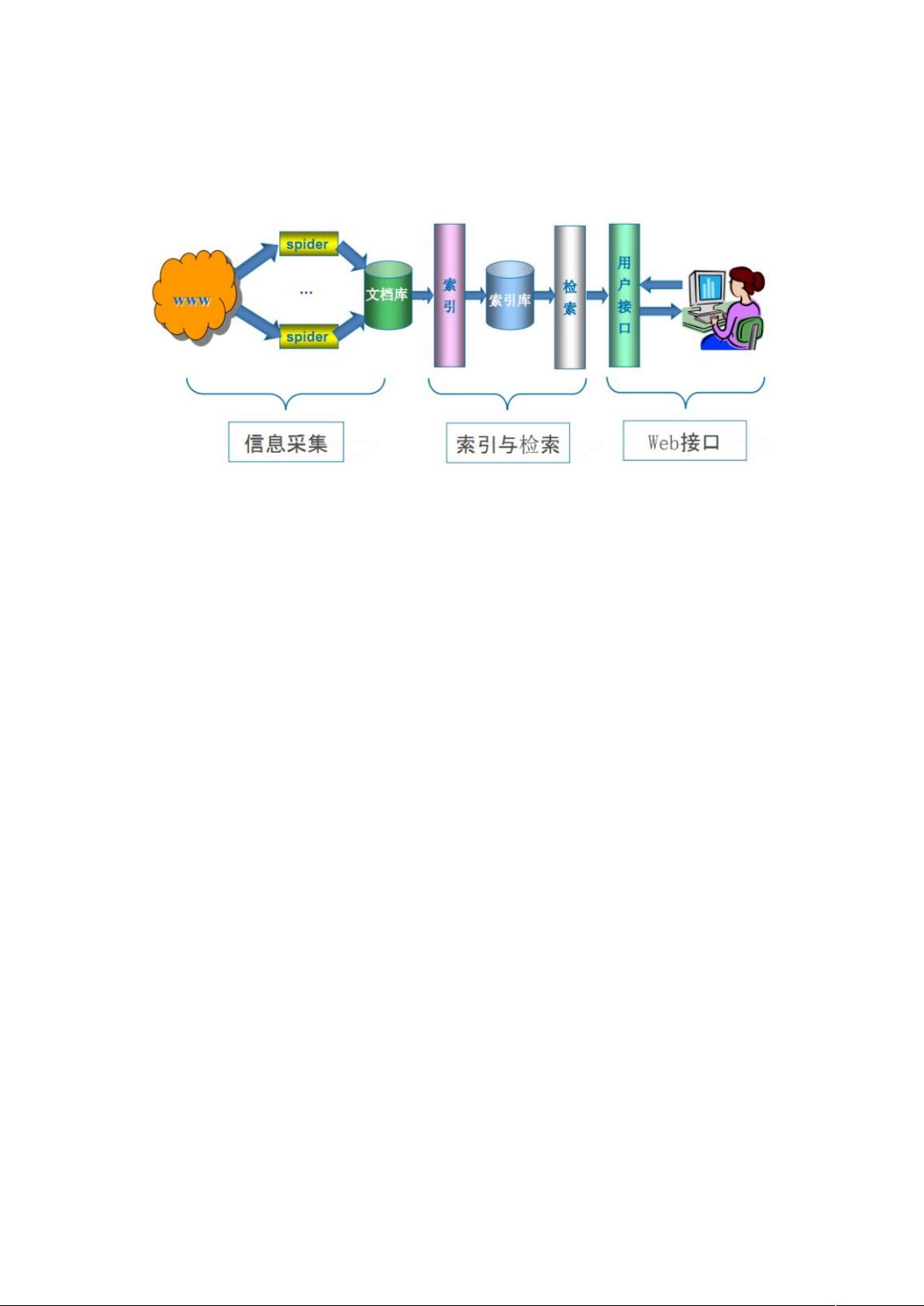
搜索引擎的工作原理包括三个主要步骤:
1. 抓取网页:首先,搜索引擎会从初始的种子URL集合开始,逐步抓取网页。它们解析URL,下载页面,并将新的URL添加到待抓取队列。这个过程会不断循环,直到达到预定的抓取深度或覆盖度。
2. 数据存储:抓取的网页会被存储在原始页面数据库中,保持与用户浏览器看到的HTML一致。同时,搜索引擎会检查重复内容,避免低质量或抄袭的网页对索引造成影响。
3. 预处理:预处理阶段包括文本提取、中文分词(将连续的汉字序列拆分成有意义的词语)、噪声消除(去除不相关的内容如导航、广告等)、索引处理(构建便于搜索的索引结构)、链接关系计算(评估页面之间的关联性)以及特殊文件处理(如PDF、图片等非HTML文件的处理)。
这个过程确保了用户在搜索时能够得到高质量、相关性强的结果。网络爬虫技术与搜索引擎的结合,使得海量的网络信息得以有序化,极大地推动了信息时代的进步。在开发过程中,开发者需要考虑如何优化爬虫策略,以提高抓取效率,同时遵守互联网的使用规则,尊重网站的Robots协议,避免过度抓取导致服务器压力过大。
同时会根据页面的 PageRank 值(链接的访问量排名)来进行网站排名,这样 Rank 值
高的网站在搜索结果中会排名较前,当然也可以直接使用 Money 购买搜索引擎网站排名,
简单粗暴。
但是,这些通用性搜索引擎也存在着一定的局限性:
1、通用搜索引擎所返回的结果都是网页,而大多情况下,网页里 90%的内容对用户来
说都是无用的。2、不同领域、不同背景的用户往往具有不同的检索目的和需求,搜索引
擎无法提供针对具体某个用户的搜索结果。
3、万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频多媒体等
不同数据大量出现,通用搜索引擎对这些文件无能为力,不能很好地发现和获取。
4、通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询,无法
准确理解用户的具体需求。
针对这些情况,聚焦爬虫技术被广泛使用。
比较两者区别:
聚焦爬虫是“面向特定主体需求”的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在于
聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证之抓取与需求相关的网页信
息。
四、通用爬虫和聚焦爬虫工作原理
剩余10页未读,继续阅读
200 浏览量
599 浏览量
224 浏览量
2021-09-27 上传
107 浏览量
2023-11-17 上传
2021-09-27 上传
2021-09-21 上传
109 浏览量

LilyWang0904
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 网络蜘蛛基本原理和算法
- 搜索引擎基本原理和算法介绍
- 计算机网络第四版(谢希仁)习题详细答案.doc
- Efficient C++ Performance Programming TechniquesAddison.Wesley.Efficient.C...Performance.Programming.Techniques.pdf
- CISCO路由器配置手册.doc
- IAR-AVR C编译器指南.pdf
- 软件工程学习书《人月神话》
- 40种网页常用小技巧
- rose ha 配置文档
- Software Architecture4+1
- 索引的SQL语句优化
- C++实现人工神经网络的类
- Qt嵌入式图形开发(入门篇)
- J2EE中文教材.doc
- 实战XML第二版.pdf
- Qt嵌入式图形开发(基础篇).pdf
