Python爬虫基础:Cookie与Session详解
需积分: 16 192 浏览量
更新于2024-07-17
收藏 3.27MB DOC 举报
"Python爬虫基础知识,包括网络爬虫开发准备、Cookiejar的使用、会话控制、W3C标准以及网页抓取方法。适合Python初学者和中高级程序员学习,内容涵盖Web前端知识和爬虫必备库。"
在Python爬虫开发中,了解和掌握Cookie的基础知识至关重要。Cookie是一种在客户端和服务器之间保持状态的技术,它诞生于Web无状态协议的需求。HTTP协议本身不保存任何关于客户端与服务器之间交互的状态,这意味着每次请求都是独立的。为了解决这个问题,Cookie应运而生。
Cookie主要用来存储Web状态信息,例如用户登录状态。在用户访问网站时,服务器可以通过设置Cookie来保存一些信息,如Session ID,这些信息存储在用户的浏览器中。当用户再次请求同一网站的其他页面时,浏览器会自动将Cookie包含在请求头中,服务器据此识别出用户的身份和状态。
Cookie的使用分为两种常见方式:客户端的Cookie和服务器端的Session。Cookie将信息保存在客户端,而Session则将信息存储在服务器端。客户端每次请求时,通过Cookie携带的Session ID来查找服务器上的对应会话信息。在爬虫开发中,通常更关注Cookie,因为它可以直接从客户端获取,这对于模拟用户行为和登录状态尤其有用。
在Python爬虫中,Cookiejar是一个重要的库,它允许开发者管理Cookie,以便在处理HTTP请求时保持会话状态。通过Cookiejar,我们可以实现对登录网站的模拟登录和保持登录状态,这对于爬取需要登录后才能访问的内容非常有用。
同时,理解W3C标准也很重要,它是Web内容的制作规范,包括HTML、CSS、JavaScript等方面,对于解析网页结构和提取数据有着基础性的指导意义。熟悉W3C标准有助于更好地理解网页结构,从而编写更精准的爬虫代码。
在实际的网页抓取过程中,Python提供了如BeautifulSoup、Scrapy等强大的库,它们能够帮助我们解析HTML和XML文档,提取所需数据。配合requests库进行HTTP请求,以及使用Cookiejar管理Cookie,可以构建出功能完备的网络爬虫。
学习Python爬虫基础知识,包括Cookie的使用、会话控制、W3C标准以及网页抓取方法,是成为高效爬虫开发者的关键步骤。通过阅读《Python快乐编程》这样的教材,并结合配套的视频和源码,可以深入理解和实践这些概念,从而提升自己的Python爬虫技能。
图
2.6
为爬虫爬取的
CU
网站登录后的下一个页面,该页面通过
Cookie
保存了登录状
态,所以可以看到该页面也是登录状态。
例
2-1
中的代码按照
Cookiejar
库处理
Cookie
的步骤,引入
Cookiejar
库后,第
12
行代
码首先创建了一个
CookieJar
对象
cookiejar,然后第
14
行创建一个
Cookie
处理器,随后以
该处理器作为参数通过
urllib.request.build_opener()创建一个
Opener
对象
opener,并使用
urllib.request.install_opener(opener)将
opener
安装为全局默认的对象,这样在使用
urlopen()
方法时,也会使用安装的
Opener
对象。
需要注意的是,第
9
行和第
10
行代码中使用了“User-Agent”属性,关于该属性的知识
介绍放在后面,这里只需要知道如何获取该属性值即可。例
2-1
中使用的浏览器是
Firefox
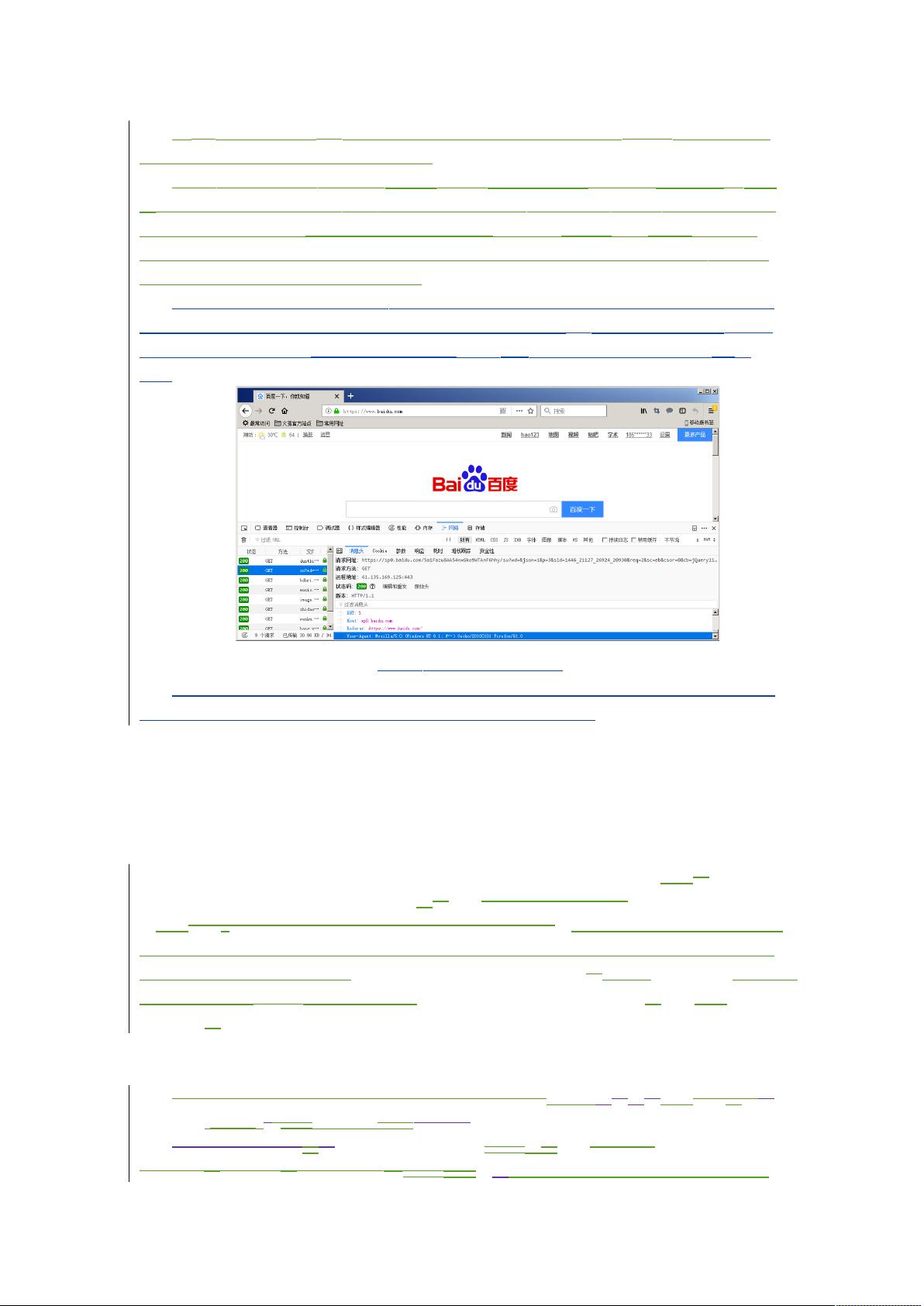
火狐浏览器, “打开网页 http://www.baidu.com”并按
F12
打开网页调试界面,如图
2.6
所
示。
图 2.6 获取
User-Agent
属性值
“ ”将调试界面切换到 网络 后,点击输入框会出现很多方法,选择一个方法将会在右侧
的消息头中看到该属性及对应的值。最后将其放入程序中即可。
2.2 正则表达式介绍
2.1.1 正则表达式的概念
在编写网页文件的程序时,经常会对含有复杂规则的字符串进行查询,而。正则表达
式就是用一些具有特殊含义的符号组合在到一起(称为正则表达式)来描述字符或字符串
的规则方法,。或者说正则就是用来描述这一类事物的规则。比如想要查询一个网页中所有
的联系人电话,此时可以编写一个正则表达式来表示所有的电话,然后在网页中提取出所
有满足该规则的字符串即可。在 Python 中,通过内嵌的 re 模块,来实现正则表达式的功能。
需要注意的是,Python
的正则表达式是被编译成一系列的字节码,然后使用 C 语言编写的
匹配引擎来执行。
2.1.2 正则表达式详解
正则表达式就是描述字符串排列的一系列规则,例如当想要查找找到网页一篇英文章
中所有的“python”“qfedu
字符串时单词
ianfeng”,
其余信息过滤掉,则就可以使用正则表达式 qfedu
来去匹配文章中的
QianFeng、qianFeng、QIANFENG
等
qfedu
单词,但设置的规则不同,匹配出来的结果也

剩余40页未读,继续阅读
514 浏览量
539 浏览量
155 浏览量
2023-12-09 上传
2024-09-07 上传
153 浏览量

好程序员517
- 粉丝: 68
- 资源: 16
 我的内容管理
展开
我的内容管理
展开







最新资源
- FLASH四宝贝之-使用ActionScript.3.0组件
- 《j2ee开发全程实录+》.pdf
- 精通 JavaScript.pdf
- 矩阵理论+Matrix+Theory
- JSP2_0技术手册.pdf
- 图书馆读者网络服务系统的架构与实现
- 振荡器模拟知识20090406
- 推荐Java 学习资料——Java技能百练.pdf
- 深入浅出Struts2.pdf
- Hibernate开发指南.pdf
- 代理中Domino对域的解析和GetItemValue使用方法
- EJB3.pdf EJB3.pdf
- VHDL电路设计例代码集.doc
- photoshop快捷键
- 俄罗斯方块VC++课程设计
- modelsim学习资源包
