机器学习笔记:线性回归与Logistic回归解析
需积分: 32 116 浏览量
更新于2024-09-08
2
收藏 762KB PDF 举报
"这篇笔记主要介绍了线性回归、逻辑回归以及一般回归的基本概念和应用,是基于斯坦福大学机器学习课程的学习总结。笔记探讨了如何使用回归方法进行预测和分类,特别是通过线性回归来拟合数据,并且讨论了机器学习的学习过程。"
线性回归是一种常见的统计和机器学习方法,主要用于分析两个或多个变量之间的关系,尤其是当目标变量(y)是连续数值时。线性回归假设因变量和自变量之间存在线性关系,即y = β0 + β1x1 + β2x2 + ... + βnxn + ε,其中β0到βn是权重参数,x1到xn是特征,ε是误差项。线性回归的目标是找到最佳的权重参数,使得模型对训练数据的预测尽可能接近实际值。
在处理回归问题时,通常使用最小二乘法来优化模型,寻找使所有数据点与直线之间距离平方和最小的权重参数。这可以通过梯度下降或正规方程等方法实现。线性回归不仅适用于单变量问题,也能处理多变量情况,即多元线性回归,这时模型可以捕获不同特征对结果的综合影响。
然而,现实世界中的数据往往并不完全符合线性关系。为了处理非线性关系,线性回归可以通过特征工程来扩展其能力,如通过多项式特征(x1^2, x2^3, x1*x2等)来引入非线性。此外,线性回归的一个重要假设是误差项应服从正态分布且独立同分布,这对于模型的统计推断和预测性能至关重要。
逻辑回归(Logistic Regression),尽管名字中有“回归”二字,实际上是一种分类方法。它适用于二分类问题,通过将线性回归的结果传递给 logistic 函数(Sigmoid 函数),将其转换为 (0,1) 区间内的概率值,进而决定样本属于某一类的概率。逻辑回归在医学诊断、信用评分等领域有广泛应用。
一般回归(Generalized Linear Regression)则是一类更广泛的方法,包括线性回归和逻辑回归在内,它允许因变量遵循不同的概率分布,如泊松分布(Poisson Regression)、负二项分布(Negative Binomial Regression)等,以适应各种类型的数据特性。
机器学习的过程通常包括数据预处理、模型选择、训练、验证和测试。线性回归作为基础模型,经常用于模型比较或作为其他复杂模型(如神经网络)的初始化。在训练过程中,通过不断调整模型参数,试图找到一个最优模型,使其对训练数据的预测误差最小,同时避免过拟合,确保模型对未见数据也有较好的泛化能力。
线性回归、逻辑回归和一般回归是数据分析和机器学习中的基础工具,它们各自有其适用场景,能帮助我们理解和预测不同类型的变量关系。通过深入理解这些方法,可以为后续学习更复杂的模型打下坚实的基础。
对回归方法的认识
JerryLead
csxulijie@gmail.com
2011 年 2 月 27 日
1 摘要
本报告是在学习斯坦福大学机器学习课程前四节加上配套的讲义后的总结与认识。前四
节主要讲述了回归问题,属于有监督学习中的一种方法。该方法的核心思想是从离散的统计
数据中得到数学模型,然后将该数学模型用于预测或者分类。该方法处理的数据可以是多维
的。
讲义最初介绍了一个基本问题,然后引出了线性回归的解决方法,然后针对误差问题做
了概率解释。
2 问题引入
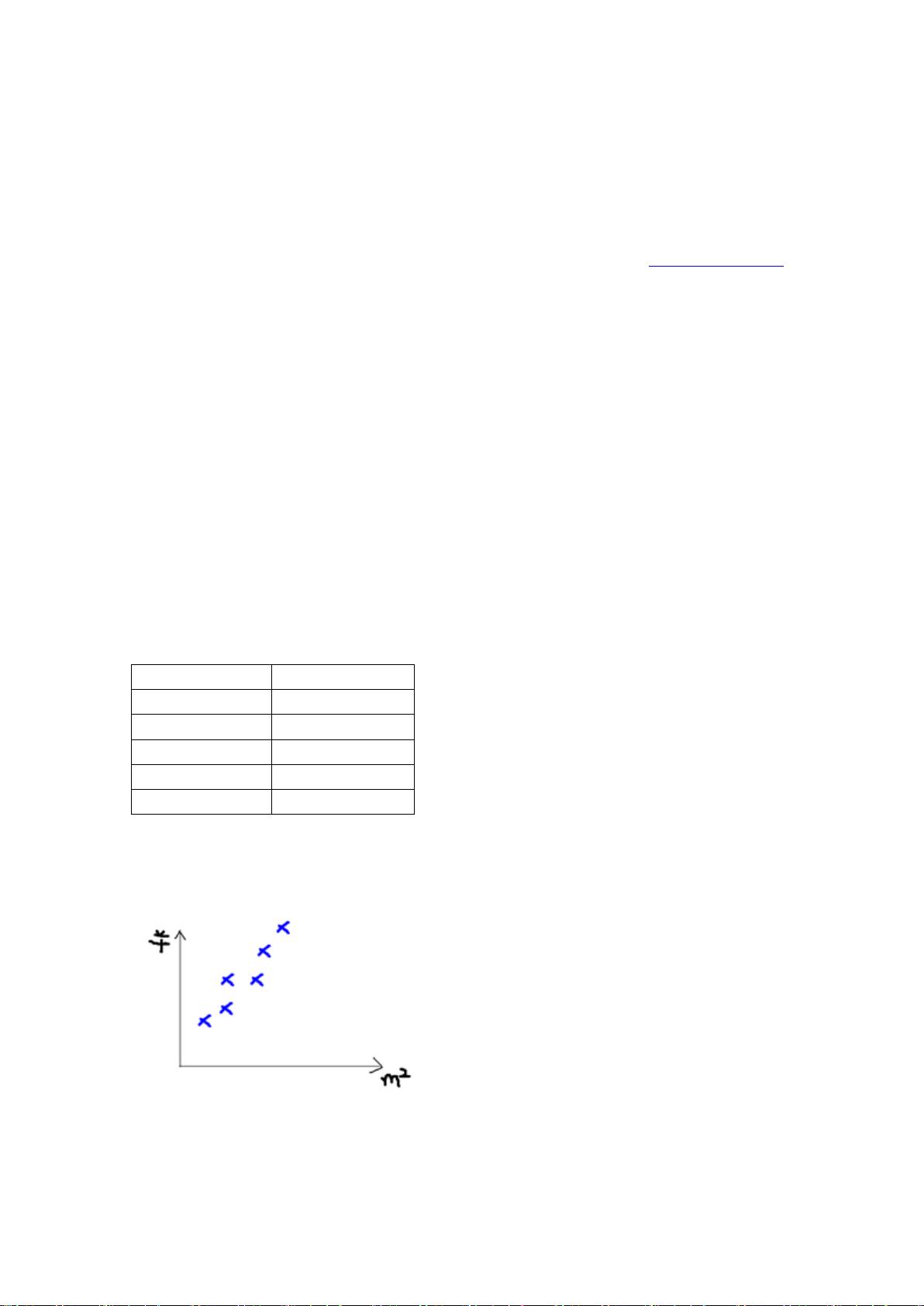
假设有一个房屋销售的数据如下:
面积(m^2)
销售价钱(万元)
123
250
150
320
87
160
102
220
…
…
这个表类似于北京 5 环左右的房屋价钱,我们可以做出一个图,x 轴是房屋的面积。y 轴是
房屋的售价,如下:
如果来了一个新的面积,假设在销售价钱的记录中没有的,我们怎么办呢?
我们可以用一条曲线去尽量准的拟合这些数据,然后如果有新的输入过来,我们可以在
将曲线上这个点对应的值返回。如果用一条直线去拟合,可能是下面的样子:
下载后可阅读完整内容,剩余8页未读,立即下载
2017-08-28 上传
2022-08-09 上传
2022-02-13 上传
2021-02-03 上传
点击了解资源详情
点击了解资源详情

wyh0307
- 粉丝: 1
- 资源: 18
 我的内容管理
展开
我的内容管理
展开







最新资源
- RichardRNStudio
- wnl.rar_Java编程_Java_
- word2vec:Google的Python接口word2vec
- :rocket:可定制的圆形/线性进度条软件包,支持动画文本,使用SwiftUI构建-Swift开发
- The Flow Of Time-crx插件
- 可运营的SSL证书在线生成系统源码,附带图文搭建教程
- grb:通过HTTP进行争夺从未如此简单
- vgg19-tensorflowjs-model::memo:Tensorflow.js VGG-19的预训练模型
- vault-kustomization
- composify:将WordPress插件zip文件转换为git存储库,以便composer版本约束正常运行
- 基于C#实现的普通图像读取及遥感图像处理
- student.rar_教育系统应用_Visual_C++_
- matlab哈士奇代码-Husky:沙哑
- PSI In-application Extension-crx插件
- 猫鼬简介:Ejemplo de un ORMbásicocreado con mongosse para mongo
- qtff-2001.zip_文件格式_Visual_C++_
